兩個字說,正則表達式的特點就是【簡潔】。
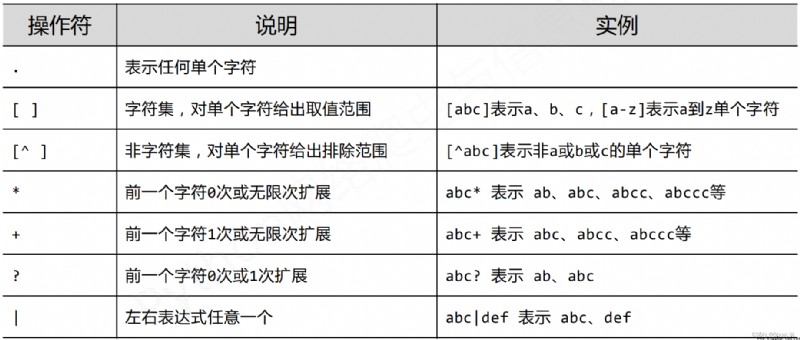


在此解釋最後一個:{}的意思是Y重復的次數,加上:3後表示P和N之間有0~3個Y
(1)Re庫主要用於字符串匹配
(2)其采用raw string類型(原生字符串類型)
(3)采用raw string類型表示正則表達式,格式為 r'text'
eg:r'[1-9]\d{5}':由一個1~9的數和5個0~9的數組成的正則表達式
注:raw string是不包含對轉義字符再次轉義的字符串(如\d,在用string表示的情況下要寫成\\d,但raw string沒這種情況)
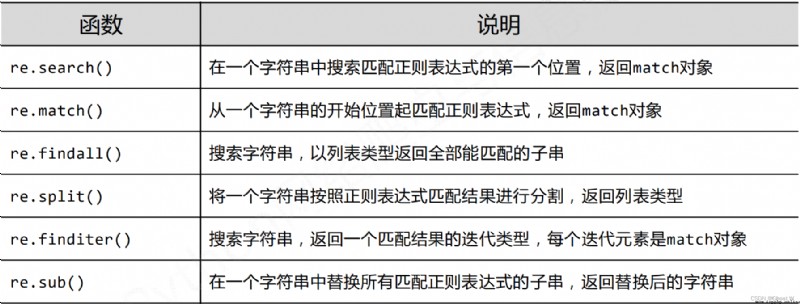

import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group[0])
#輸出 100081
import re
match = re.match(r'[1-9]\d{5}','BIT 100081')
if match:
match.group(0)
match.group(0)
'''因為是從頭匹配,由於開頭不符合匹配條件,因此匹配失敗;下半部分的代碼就可以匹配成功
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
match.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
'''
match = re.match(r'[1-9]\d{5}','100081 BIT')
if match:
match.group(0)
'100081'
import re
ls = re.findall(r'[1-9]\d{5}','BIT100081 TSU100084')
ls
['100081', '100084']
#原理是將可以匹配的字符串存儲在一個列表中
import re
re.split(r'[1-9]\d{5}','BIT100081 TSU100084')#作用是去掉匹配的字符串,將剩下部分存儲在列表中
['BIT', ' TSU', '']
re.split(r'[1-9]\d{5}','BIT100081 TSU100084',maxsplit=1)#最後maxsplit=1作用是只去掉前面一個匹#配的字符串
['BIT', ' TSU100084']
import re
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'):
if m:
print(m.group(0))
# 匹配到一次返回一次
100081
100084
import re
re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
#將所有的匹配部分換成zipcode