在開始正式的數據分析前,我們需要對不合理的數據進行預先的處理。
常見的不合理數據有缺失數據、重復數據、異常數據等
對於各種原因造成的缺失空值,一般有兩種處理方式:
Ctrl+g調出"定位"窗口,打開"定位條件",選擇"空值",即可選中該區域內的所有空值。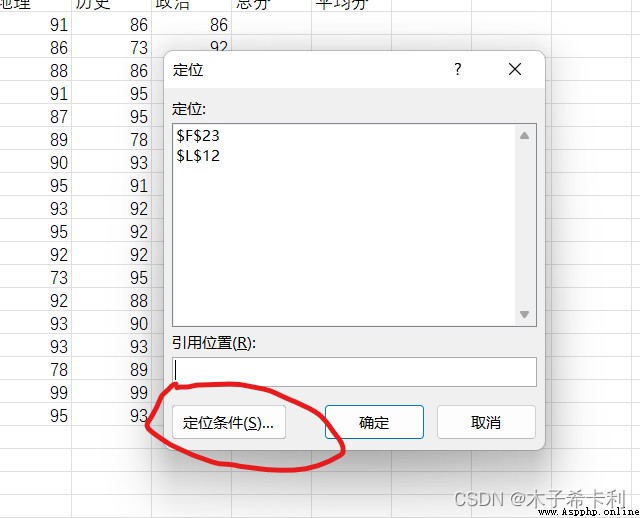
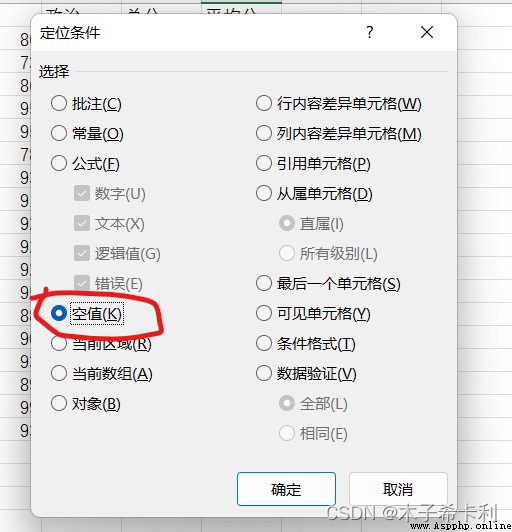
在Pandas中,"NaN"代表數字型空值
df_obj.info()
之前我們利用這個方法來查看字段的數據類型,但它也能顯示出空值的信息。
如:
grades_df.info()
""" <class 'pandas.core.frame.DataFrame'> Index: 18 entries, 包宏偉 to 張桂花 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 學號 18 non-null int64 1 班級 18 non-null object 2 語文 18 non-null float64 3 數學 16 non-null float64 4 英語 18 non-null int64 5 生物 17 non-null float64 6 地理 18 non-null int64 7 歷史 18 non-null int64 8 政治 18 non-null int64 9 總分 18 non-null float64 10 平均分 18 non-null float64 dtypes: float64(5), int64(5), object(1) memory usage: 1.7+ KB """
#18個行索引,第3列16個非空值(non-null),第5列有17個非空值,說明第3列有18-16=2個缺失值,第5列有18-17=1個缺失值
df_obj.isnull()
True代表為缺失空值DataFrame對象如:
print(grades_df.isnull())
""" 學號 班級 語文 數學 英語 生物 地理 歷史 政治 總分 \ 姓名 包宏偉 False False False False False False False False False False 陳萬地 False False False False False False False False False False 杜學江 False False False False False False False False False False 符合 False False False False False True False False False False 吉祥 False False False True False False False False False False 李北大 False False False False False False False False False False 李娜娜 False False False False False False False False False False 劉康鋒 False False False False False False False False False False 劉鵬舉 False False False True False False False False False False 倪冬聲 False False False False False False False False False False 齊飛揚 False False False False False False False False False False 蘇解放 False False False False False False False False False False 孫玉敏 False False False False False False False False False False 王清華 False False False False False False False False False False 謝如康 False False False False False False False False False False 闫朝霞 False False False False False False False False False False 曾令煊 False False False False False False False False False False 張桂花 False False False False False False False False False False 平均分 姓名 包宏偉 False 陳萬地 False 杜學江 False 符合 False 吉祥 False 李北大 False 李娜娜 False 劉康鋒 False 劉鵬舉 False 倪冬聲 False 齊飛揚 False 蘇解放 False 孫玉敏 False 王清華 False 謝如康 False 闫朝霞 False 曾令煊 False 張桂花 False """
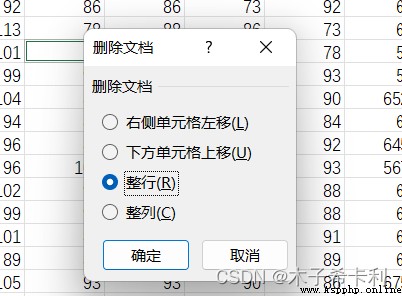
選中缺失值後,右鍵選擇"刪除"–>“整行”
df_obj.dropna(axis: 'Axis' = 0,
how: 'str' = 'any',
inplace: 'bool' = False,
)
axis設置刪除的是行還是列。為0代表行,為1代表列。默認為列。how設置刪除條件。為"any"代表只要本行/列出現空值就刪除。為"all"代表只有本行全為空值才刪除。默認為"any"inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為False如:
df = pd.DataFrame([["張三", 18, 120],[None, None, 130],
[None, None, None], ["李四", 17, 100] ],
index=[1, 2, 3, 4],
columns=['姓名', '年齡', '得分'])
print(df)
""" 姓名 年齡 得分 1 張三 18.0 120.0 2 None NaN 130.0 3 None NaN NaN 4 李四 17.0 100.0 """
new_df1=df.dropna(how="all")
print(new_df1)
""" 姓名 年齡 得分 1 張三 18.0 120.0 2 None NaN 130.0 4 李四 17.0 100.0 """
new_df2=df.dropna(how="any")
print(new_df2)
""" 姓名 年齡 得分 1 張三 18.0 120.0 4 李四 17.0 100.0 """
print(df) # 以上操作默認在返回的新表中操作,不會影響原表
""" 姓名 年齡 得分 1 張三 18.0 120.0 2 None NaN 130.0 3 None NaN NaN 4 李四 17.0 100.0 """
當缺失值占整行數據少於 30 % 30\% 30%時,我們可以考慮把缺失值替換成其他值。
通過"定位條件"選中所有空值後,在第一個空值中輸入要替換成的目標值(常用0、眾數、平均數、相鄰數據等),Ctrl+Enter ,即可替換所有空值。
df.fillna(value: 'object | ArrayLike | None' = None,
method: 'FillnaOptions | None' = None,
axis: 'Axis | None' = None,
inplace: 'bool' = False,
)
value設置替換值。可以傳入單個替換值。也可以傳入key為行/列索引,value為該行/列的替換值組成的字典。
method設置可選的替換方式。pad或ffill為上一個非空值。backfill或bfill為下一個非空值。
axis設置替換的單位是行還是列。為0代表行,為1代表列。默認為列。
inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為False
如:
df = pd.DataFrame([["張三", 18, 120],[None, None, 130],
[None, None, None], ["李四", 17, 100] ],
index=[1, 2, 3, 4],
columns=['姓名', '年齡', '得分'])
new_df1=df.fillna(0)
print(new_df1)
""" 姓名 年齡 得分 1 張三 18.0 120.0 2 0 0.0 130.0 3 0 0.0 0.0 4 李四 17.0 100.0 """
new_df2=df.fillna({
"姓名":"佚名","年齡":18,"得分":0})
print(new_df2)
""" 姓名 年齡 得分 1 張三 18.0 120.0 2 佚名 18.0 130.0 3 佚名 18.0 0.0 4 李四 17.0 100.0 """
重復值一般直接刪除。
選中表格區域,在菜單欄依次選擇"數據">“數據工具">“刪除重復值”,勾選想要檢測重復值的列。只要這些選中的列數據全部相同,就會刪除重復行,只留下一個。
df.drop_duplicates(subset: 'Hashable | Sequence[Hashable] | None' = None,
keep: "Literal['first'] | Literal['last'] | Literal[False]" = 'first',
inplace: 'bool' = False,
ignore_index: 'bool' = False)
subset設置想要檢測重復值的列。可以傳入一個列表。默認為所有列。keep設置保留的數據的位置。'first'代表第一個,'last'代表最後一個,None代表一個都不留。inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為Falseignore_index設置是否重新設置默認索引(從0開始的整數)。False代表不重新設置,True代表重新設置。如:
df = pd.DataFrame([["張三", 18, 120], ["張三", 18, 120], ["張三", 17, 130],
["李四", 17, 120], ["李四", 17, 100]],
index=[1, 2, 3, 4, 5],
columns=['姓名', '年齡', '得分'])
new_df1=df.drop_duplicates()
print(new_df1)
""" 姓名 年齡 得分 1 張三 18 120 3 張三 17 130 4 李四 17 120 5 李四 17 100 """
new_df2=df.drop_duplicates(subset=['姓名','年齡'])
print(new_df2)
""" 1 張三 18 120 3 張三 17 130 4 李四 17 120 """
new_df3=df.drop_duplicates(ignore_index=True)
print(new_df3)
""" 姓名 年齡 得分 0 張三 18 120 1 張三 17 130 2 李四 17 120 3 李四 17 100 """
異常值指非正常數據,要麼過高,要麼過低,總之不符合實際。
檢測異常值的常用策略:
處理異常值的常用策略:
DataFrame表對象replace方法其他章節詳述
選中某一列,在"數字"欄中可查看其數據類型:
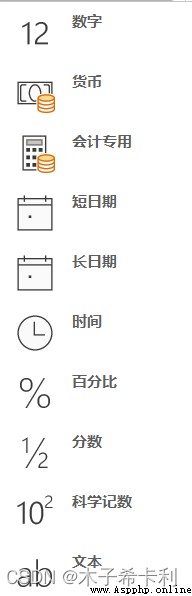
Pandas的主要數據類型有以下幾種:
可以使用前面介紹過的info()方法來查看整個表的數據類型及其他信息,還可以通過dtypes屬性只獲取整個表的數據類型,列的dtype屬性獲取特定列的數據類型。
df.dtypes
df[列索引].dtype
如:
df = pd.DataFrame(
{
"學科": ["數學分析", "高等代數", "解析幾何"],
"學期": [3, 2, 1],
"學分": [18, 12, 4],
"是否必修": [True, True, False]
},
index=range(1, 4))
print(df["學科"].dtype)
print(df["學期"].dtype)
print(df["學分"].dtype)
print(df["是否必修"].dtype)
""" object int64 int64 bool """
print(df.dtypes)
""" 學科 object 學期 int64 學分 int64 是否必修 bool dtype: object """
不同的數據類型能進行的操作不同。為了滿足需求,需要將數據強制轉換為正確的類型。
選中某列,同樣在"數字"欄,點擊類型完成轉換。有時可以看到明顯的格式變化。
df.astype(dtype, copy: 'bool_t' = True, errors: 'str' = 'raise')
dtype可以傳入字典,key為列索引,value為轉化的目標類型copy設置是否復制,即不在原表上操作,返回新表,默認為Trueerrors設置轉化失敗後的行為。'raise'為報錯,'ignore'為忽視。默認'raise'如:
new_df=df.astype({
"學期":"object","學分":"float64"})
print(df.dtypes)
""" 學科 object 學期 int64 學分 int64 是否必修 bool dtype: object """
print(new_df.dtypes)
""" 學科 object 學期 object 學分 float64 是否必修 bool dtype: object """
在表的第一行上方插入新的一行,在表的第一列左方插入新的一列。
選中第一行/第一列,右擊"插入>整行/整列"
在新行新列中添加索引
DataFrame對象默認以0開始的整數數列為索引。
可以通過index屬性修改行索引,columns屬性修改列索引。
df.index=[...]
df.columns=[...]
如:
df = pd.DataFrame([["a", "A"], ["b", "B"], ["c", "C"]])
print(df)
""" 0 1 0 a A 1 b B 2 c C """
df.index = range(1, 4)
df.columns = ["小寫", "大寫"]
print(df)
""" 小寫 大寫 1 a A 2 b B 3 c C """
將該列拖動到第一列即可
df.set_index(keys,
drop: 'bool' = True,
inplace: 'bool' = False
)
key可為單個列索引,或列索引列表(稱為層次化索引)drop設置是否刪除表中的該列,僅將其設為索引。默認為Trueinplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為False如:
df = pd.DataFrame({
"商品名稱": ["蘋果", "梨", "手機", "電腦", "玩偶", "玩具汽車"],
"商品種類": ["食品", "食品", "電子產品", "電子產品", "玩具", "玩具"],
"商品編號": [1, 2, 1, 2, 1, 2],
"商品單價": [2, 3, 4000, 5000, 100, 200]
})
print(df)
""" 商品名稱 商品種類 商品編號 商品單價 0 蘋果 食品 1 2 1 梨 食品 2 3 2 手機 電子產品 1 4000 3 電腦 電子產品 2 5000 4 玩偶 玩具 1 100 5 玩具汽車 玩具 2 200 """
new_df1 = df.set_index("商品編號")
print(new_df1)
""" 商品種類 商品編號 商品單價 商品名稱 蘋果 食品 1 2 梨 食品 2 3 手機 電子產品 1 4000 電腦 電子產品 2 5000 玩偶 玩具 1 100 玩具汽車 玩具 2 200 """
new_df2 = df.set_index(["商品種類", "商品編號"])
print(new_df2)
""" 商品名稱 商品單價 商品種類 商品編號 食品 1 蘋果 2 2 梨 3 電子產品 1 手機 4000 2 電腦 5000 玩具 1 玩偶 100 2 玩具汽車 200 """
層次化索引可實現多維表格
直接修改索引名即可。
df.rename(index: 'Renamer | None' = None,
columns: 'Renamer | None' = None,
inplace: 'bool' = False,
errors: 'str' = 'ignore',)
index設置行索引命名的過程。可以傳入字典,key為舊索引名,value為新索引名。columns設置列索引命名的過程。可以傳入字典,key為舊索引名,value為新索引名。inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為Falseerrors設置轉化失敗後的行為。'raise'為報錯,'ignore'為忽視。默認'raise'如:
new_df3=df.rename(columns={
"商品名稱":"名稱","商品種類":"種類","商品編號":"編號"},index={
0:6})
print(new_df3)
""" 名稱 種類 編號 商品單價 6 蘋果 食品 1 2 1 梨 食品 2 3 2 手機 電子產品 1 4000 3 電腦 電子產品 2 5000 4 玩偶 玩具 1 100 5 玩具汽車 玩具 2 200 """
將行索引恢復為列
如果是一列的行索引,直接拖動離開第一列即可。
如果是層次化索引,復制、粘貼、刪除以恢復
df.reset_index(level: 'Hashable | Sequence[Hashable] | None' = None,
drop: 'bool' = False,
inplace: 'bool' = False
)
level設置要恢復的行索引對應的列。默認所有層全部恢復。可指定層數(0開始)或列名。drop設置是否刪除對應索引,不把它恢復成數據列。默認為Falseinplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為False如:
new_df4=new_df2.reset_index(level=1)
print(new_df4)
""" 商品編號 商品名稱 商品單價 商品種類 食品 1 蘋果 2 食品 2 梨 3 電子產品 1 手機 4000 電子產品 2 電腦 5000 玩具 1 玩偶 100 玩具 2 玩具汽車 200 """
new_df5=new_df2.reset_index(level="商品編號")
print(new_df5)
""" 商品種類 商品名稱 商品單價 商品編號 1 食品 蘋果 2 2 食品 梨 3 1 電子產品 手機 4000 2 電子產品 電腦 5000 1 玩具 玩偶 100 2 玩具 玩具汽車 200 """
new_df6=new_df2.reset_index()
print(new_df6)
""" 商品種類 商品編號 商品名稱 商品單價 0 食品 1 蘋果 2 1 食品 2 梨 3 2 電子產品 1 手機 4000 3 電子產品 2 電腦 5000 4 玩具 1 玩偶 100 5 玩具 2 玩具汽車 200 """
reset_index()方法常用於數據分組、數據透視表中