實驗1:判斷是否是回文數
判斷一個正整數是不是回文數。如果一個數的正向和逆向的講法相同,那麼稱該數為回文數,如12321、7887是回文數
輸入:一個正整數
輸出:如果是回文數,輸出“是回文數”;否則輸出“不是回文數”
測試樣例:
樣例1:個位數
輸入:3
輸出:是回文數
樣例2:奇數位回文數
輸入:1578751
輸出:是回文數
樣例3:偶數位回文數
輸入:12344321
輸出:是回文數
樣例4:非回文數
輸入:1234231
輸出:不是回文數
x=int(input("請輸入一個整數:"))
if x<0 or(x%10==0 and x!=0):
print("不是回文數")
elif not x//10:
print("是回文數")
else:
n=0
while(x>n):
n=n*10+x%10
x//=10
if x==n or x==(n//10):
print("是回文數")
else:
print("不是回文數")
改進:將其當作字符串,十分快捷
x=int(input("請輸入一個正整數:"))
x=str(x)
print("是回文數") if x==x[::-1] else print("不是回文數")
參考代碼:
text = input("請輸入一個字符串:")
l = len(text)
mid = int(l/2)
if text[0:mid] == text[l-1:mid-int(not(l%2)):-1]:
print("是回文")
else:
print("不是回文")
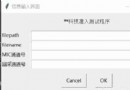
運行截圖:
實驗2:猜年齡
題目:輸入猜測的年齡,直到猜對為止,每次給出猜大了或猜小了的提示,猜測成功時輸出猜測的次數。
提示:被猜的數字采用隨機數方式生成,生成方式用random模塊實現,具體方法如下:
import random
age = random.randint(1, 100) #生成1到100內的整數
測試樣例:
樣例(假設被猜年齡為53):
輸入:1
輸出:猜小了
輸入:50
輸出:猜小了
輸入:60
輸出:猜大了
輸入:55
輸出:猜小了
輸入:53
輸出:猜對了,共猜了4次
import random
age = random.randint(1, 101)
times=0
guess=0
print (age) #輸出了隨機生成的數
while guess!=age:
guess=int(input("請輸入你要猜測的數字:"))
if guess>age:
print("猜大了")
elif guess<age:
print("猜小了")
times=times+1
if guess==age:
print("猜對了,共猜了",times,"次")
參考代碼:
from random import randint
age = randint(1, 101)
times = 0
while True:
guess = int(input("輸入你猜的數:"))
times += 1
if guess < age:
print("猜小了")
elif guess > age:
print("猜大了")
else:
print("猜對了!共猜了{}次".format(times))
break
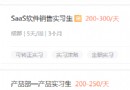
運行截圖: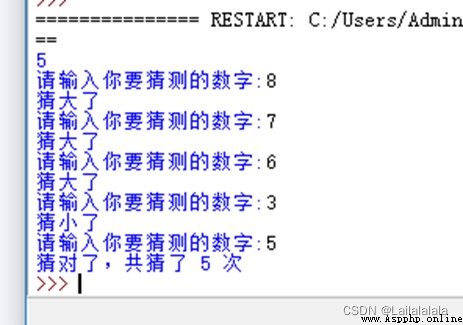
實驗3:提取列表中的數據,放到字典中
題目:定義一個列表stus,列表stus中的每個元素是包括學號、語文成績、數學成績、英語成績的字典類型,列表數據如下:
stus = [{‘sid’:’102’, ‘Chinese’:90, ‘Math’:80, ‘English’:70}, {‘sid’:’103’, ‘Chinese’:76, ‘Math’:89, ‘English’:88}, {‘sid’:’101’, ‘Chinese’:95, ‘Math’:91, ‘English’:65}]
提取列表stus中的數據,放到字典courses中,按學號從大到小的順序輸出courses內容,輸出形式如下:
103:[76, 89, 88]
102:[90,80,70]
101:[95,91,65]
思路:
字典作為元素定義在列表裡面,用列表的遍歷就能提出來,提取出來之後直接就是字典,用items()來直接獲取。以元組it來訪問每一對鍵值,就行了。因為要把學號提取出來,所有要比較’it[0]==sid’,相等則將it[1]提取出來作為鍵k,不是則將成績提取出來作為courses的值v。因為有多門課,所以v是以列表的形式保存,所以先定義v是個空列表,再將值用append()函數將其儲存,因為按照學號從大到小輸出,我們需要將字典的鍵值提取到列表score裡,最好我們還要進行排序,用sort()函數。最後按格式輸出。
提示:
Sort函數:
格式:sort(key = lambda x:x[0],reverse = True)
此處的lambda是默認的,記住就好。x:x[0]代表對鍵(key)進行排序,而x:x[1]代表對值(values)進行排序,reverse=true表示降序,reverse=false表示逆序。
代碼:
stus = [{
'sid':'102','Chinese':90, 'Math':80, 'English':70}, {
'sid':'103', 'Chinese':76, 'Math':89, 'English':88}, {
'sid':'101', 'Chinese':95, 'Math':91, 'English':65}]
courses={
}
for item in stus:
v=[]
for it in item.items():
if it[0]=='sid':
k=it[1]
else:
v.append(it[1])
courses[k]=v
scores=list(courses.items())
scores.sort(key=lambda x:x[0],reverse=False)
for l in scores:
print('{}:{}'.format(l[0],l[1]))
參考代碼:
stus = [{
'sid':'102', 'Chinese':90, 'Math':80, 'English':70},
{
'sid':'103', 'Chinese':76, 'Math':89, 'English':88},
{
'sid':'101', 'Chinese':95, 'Math':91, 'English':65}]
courses = {
}
ids = []
for s in stus:
courses[s['sid']] = [s['Chinese'], s['Math'], s['English']]
ids.append(s['sid'])
ids.sort(reverse=True)
for i in ids:
print(i,courses[i],sep=':')
運行截圖:
實驗4:模擬數據壓縮中的行程長度壓縮方法
行程長度壓縮的方法是,對一個待壓縮的字符串而言,依次記錄每個字符及重復的次數,例如,待壓縮字符串為”AAABBBBCBB”,則壓縮的結果是(A,3)(B,4)(C,1)(B,2)。現要求根據輸入的字符串,得到壓縮後的結果(字符串不區分大小寫,即所有小寫字母均可視為相應的大寫字母)。
提示:可以先用upper方法將所有輸入先轉為大寫字母
輸入一個字符串
輸入壓縮格式
樣例1:無重復字符串
輸入:abcdABCD
輸出:(A,1)(B,1)(C,1)(D,1)(A,1)(B,1)(C,1)(D,1)
樣例2:有重復字符串
輸入:aAaBBbCcaAbbBbbBcCCc
輸出:(A,3)(B,3)(C,2)(A,2)(B,6)(C,4)
代碼:
a=input("請輸入帶壓縮字符串:")
b=a.upper()
r=''
if len (b)==0:
print( r)
l =b[0]
count=1
for i in b[1:]:
if l==i:
count=count+1
else:
r+="({},{})".format(l,count)
l=i
count=1
r+="({},{})".format(l ,count)
print( r)
參考代碼:
text = input("輸入一個字符串:")
text = text.upper()
print(text)
ch = text[0]
t = 1
res = []
for c in text[1:]:
if c == ch:
t += 1
else:
res.append((ch,t))
t = 1
ch = c
res.append((ch,t))
print(res)
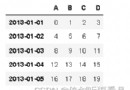
運行截圖: