字符串是Python中最常用的數據類型
創建字符串很簡單,我們可以使用引號(’ ’ 或 " ")來創建字符串,只需為變量分配一個值即可。
str1 = 'Hello Python'
str2 = "hello python"
當然,除了使用引號直接創建字符串之外,我們還可以使用 str() 函數將其他數據類型或對象轉換為字符串,其具體用法見下方內置函數。
和列表、元組一樣,我們既可以使用下標索引訪問字符串中的某個元素(得到是一個字符),也可以使用切片訪問字符串中的一組元素(得到是子字符串)。
下標索引訪問字符串分為兩大類,即正向索引和反向索引,格式為 str_name[i] ,其中,str_name 表示字符串名,i表示索引值,i可以是正數(正向索引)也可以是負數(反向索引)。
可以得知,str_name[0]表示字符串的第一個字符,str_name[-1]則表示字符串的最後一個字符。
str1 = 'Hello Py'
print(str1[0])
print(str1[-1])
H
y
正向索引:從第一個(下標0)開始、第二個(下標1)…
反向索引:從倒數第一個(下標-1)、倒數第二個(下標-2)…
如若對上方描述不太理解,可參考下表:
Python訪問子字符串,可以使用中括號 [ ] 來截取字符串,即切片訪問。
使用切片訪問字符串的格式為 str_name[strat : end : step] ,其中,start 表示起始索引,end 表示結束索引,step 表示步長。
str1 = 'Hello Py'
print(str1[0:5])
print(str1[-8:-1])
print(str1[:])
print(str1[::2])
Hello
Hello P
Hello Py
HloP
截取字符串的一部分,遵循左閉右開原則,str[0:2] 是不包含第 3 個字符的。
使用 for 循環遍歷字符串時,將會輸出字符串中的每一個字符。
str_h = 'Hi Py'
for char in str_h:
print(char)
H
i
P
y
如果我們需要確定在一個字符串中,是否存在相同的字符或者子字符串,可以使用成員運算符中的 in 和 not in 關鍵字。
str1 = 'Hello Python'
print('H' in str1)
print('Python' not in str1)
True
False
我們可以截取字符串的一部分並與其他字段拼接,如下實例:
str1 = 'Hello World'
print(str1[:6] + 'Python')
Hello Python
同列表和元組一樣,字符串之間可以使用 + 號和 * 號分別實現字符串的連接(合並)和復制(重復),這意味著它們可以生成一個新的字符串。
1、+連接(合並)
a = 'Hello'
b = 'Python'
print(a + b)
HelloPython
2、*復制(重復)
c = 'Hello'
print(c * 5)
HelloHelloHelloHelloHello
如果需要在字符中使用特殊字符時,則使用反\斜槓 \ 轉義字符,如下表:
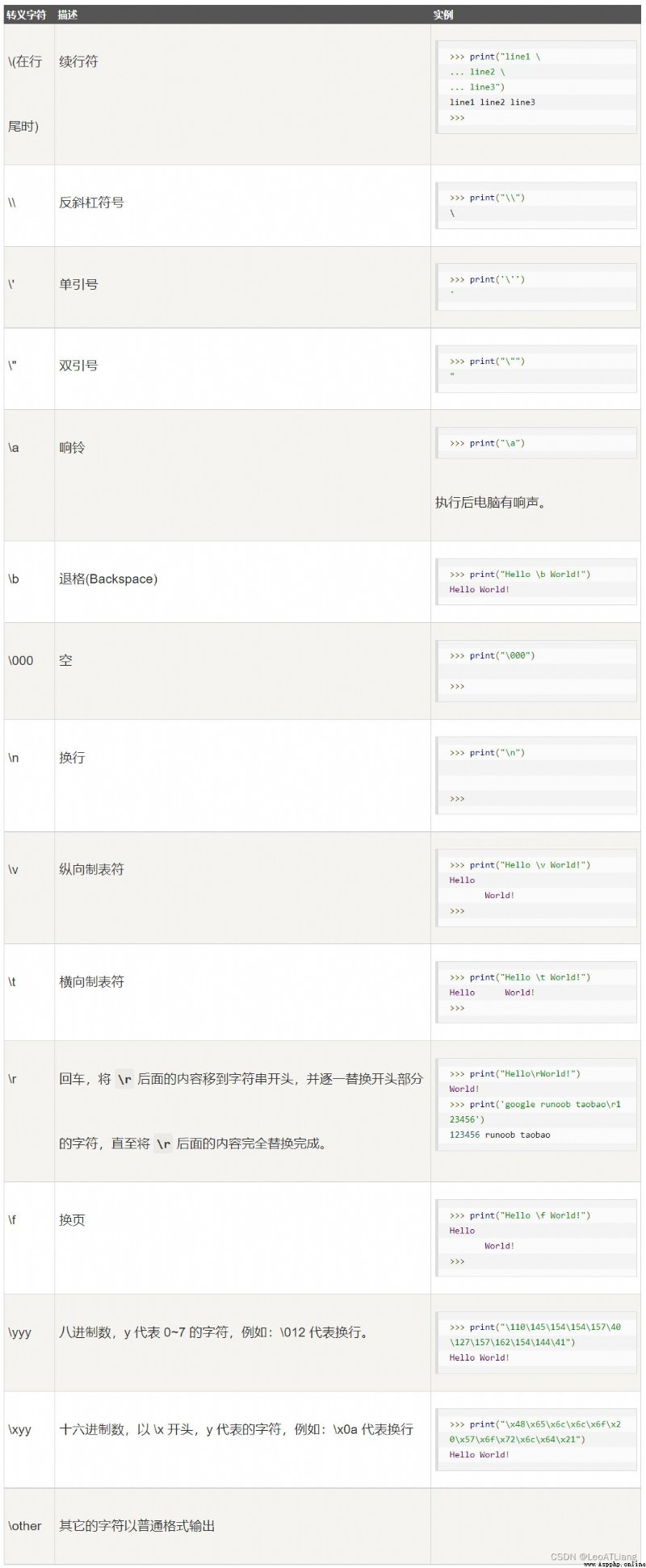
原始字符串:所有的字符串都是直 接按照字面的意思來使用,沒有轉義特殊或不能打印的字符。
原始字符串除在字符串的第一個引號前加上字母 r / R (可以大小寫)以外,與普通字符串有著幾乎完全相同的語法。
print(r'\n')
print(R'\n')
print(r'\t')
print(r'\a')
\n
\n
\t
\a
Python支持格式化字符串的輸出。盡管這樣可能會用到非常復雜的表達式,但最基本的用法是將一個值插入到一個有字符串格式符 %s 的字符串中。
print('我叫 %s ,今年 %d 歲!' % ('pink', 21))
我叫 pink ,今年 21 歲!
在Python中,字符串格式化使用與 C語言 中 printf() 函數一樣的用法。
Python字符串格式化符號如下表所示:
格式化操作符輔助指令:
Python2.6 開始,新增了一種格式化字符串的函數 str.format(),它增強了字符串格式化的功能。
Python三引號允許一個字符串跨多行,字符串中可以包含換行符、制表符以及其他特殊字符。實例如下:
str1 = """這是一個多行字符串 多行字符串可以使用制表符 TAB[\t] 也可以使用換行符[\n] """
print(str1)
這是一個多行字符串
多行字符串可以使用制表符
TAB[ ]
也可以使用換行符[
]
三引號讓程序員從引號和特殊字符串的泥潭裡面解脫出來,自始至終保持一小塊字符串的格式是所謂的WYSIWYG(所見即所得)格式的。
當你需要一塊HTML或者SQL時,這時用字符串組合,特殊字符串轉義將會非常的繁瑣。
errHTML = ''' <HTML><HEAD><TITLE> Friends CGI Demo</TITLE></HEAD> <BODY><H3>ERROR</H3> <B>%s</B><P> <FORM><INPUT TYPE=button VALUE=Back ONCLICK="window.history.back()"></FORM> </BODY></HTML> '''
cursor.execute(''' CREATE TABLE users ( login VARCHAR(8), uid INTEGER, prid INTEGER) ''')
f-string 是 python3.6 之後版本添加的,稱之為字面量格式化字符串,是新的格式化字符串的語法。
之前我們習慣用百分號 (%):
name = 'pink'
print('Hello %s' % name)
f-string 格式化字符串以 f 開頭,後面跟著字符串,字符串中的表達式用大括號 {} 包起來,它會將變量或表達式計算後的值替換進去,實例如下:
name = 'pink'
print(f'Hello {
name}')
print(f'{
1 + 2}')
baidu = {
'name': 'Baidu', 'url': 'https://www.baidu.com'}
print(f'{
baidu["name"]}:{
baidu["url"]}')
Hello pink
3
Baidu:https://www.baidu.com
用了這種方式明顯更簡單了,不用再去判斷使用 %s,還是 %d。
在 Python 3.8 的版本中可以使用 = 符號來拼接運算表達式與結果:
x = 1
print(f'{
x + 1}')
y = 1
print(f'{
x + 1 = }')
2
x + 1 = 2
在Python2中,普通字符串是以8位ASCII碼進行存儲的,而Unicode字符串則存儲為16位unicode字符串,這樣能夠表示更多的字符集。使用的語法是在字符串前面加上前綴 u。
在Python3中,所有的字符串都是Unicode字符串。
1、print()函數
print() 函數的功能我們已經非常熟悉了,就是打印輸出。
str1 = 'Hello Python'
print(str1)
Hello Python
2、len()函數
當我們要確定一個字符串中有多少個字符時,我們可以使用 len() 函數。
str2 = 'Hello Python'
print(len(str2))
12
3、type()函數
使用 type() 函數可以確定變量是什麼類型(字符串、列表、元組、字典或集合)。
str3 = 'Hello Python'
print(type(str3))
<class 'str'>
當對 str3 使用 type() 確定變量類型時,會返回
<class 'str'>,表明這是一個字符串。
4、str()函數
我們可以使用 str() 函數將列表、元組、字典、集合和區間等對象轉換為字符串,以下將會一一介紹:
list1 = ['a', 'b', 'c']
print(type(str(list1)))
print(str(list1))
<class 'str'>
['a', 'b', 'c']
tuple1 = ('A', 'B', 'C')
print(type(str(tuple1)))
print(str(tuple1))
<class 'str'>
('A', 'B', 'C')
dict1 = {
'name': 'pink'}
print(type(str(dict1)))
print(str(dict1))
<class 'str'>
{
'name': 'pink'}
set1 = {
'name', 'gender'}
print(type(str(set1)))
print(str(set1))
<class 'str'>
{
'name', 'gender'}
range1 = range(0, 10)
print(type(str(range1)))
print(str(range1))
<class 'str'>
range(0, 10)
5、max()函數和min()函數
max() 函數的作用是返回字符串中最大的字符。min() 函數的作用是返回字符串中最小的字符。
str_m = 'AazZ'
print(max(str_m))
print(min(str_m))
z
A
在Python中,del 函數並不支持刪除字符串中的單個字符,但我們可以使用 del 函數刪除整個字符串:
str1 = 'Hello Python'
del str1
print(str1)
當我們使用 del 函數刪除某字符串後,如果再使用 print() 函數打印輸出時,會報錯
NameError: name 'str1' is not defined,表明該字符串未被定義。
1、 capitalize()方法
capitalize() 將字符串的第一個字母變成大寫,其他字母變小寫。
語法
string.capitalize()
參數值
無參數
實例
str1 = 'hello python'
print(str1.capitalize())
Hello python
2、casefold()方法
casefold() 方法返回一個字符串,其中所有字符均為小寫。
語法
string.casefold()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.casefold())
hello python
此方法與 lower() 方法相似,但是 casefold() 方法更強大,更具攻擊性,這意味著它將更多字符轉換為小寫字母,並且在比較兩個用 casefold() 方法轉換的字符串時會找到更多匹配項。
3、lower()方法
lower() 方法轉換字符串中所有大寫字符為小寫(符號和數字將被忽略)。
語法
string.lower()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.lower())
hello python
4、upper()方法
upper() 方法將字符串中的小寫字母轉為大寫字母(符號和數字將被忽略)。
語法
string.upper()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.upper())
HELLO PYTHON
5、title()方法
title() 方法返回"標題化"的字符串,就是說所有單詞的首個字母轉化為大寫,其余字母均為小寫。
語法
string.title()
參數值
無參數
實例
str1 = 'HELLO Python'
print(str1.title())
Hello Python
6、swapcase()方法
swapcase() 方法用於對字符串的大小寫字母進行轉換,即將大寫字母轉換為小寫字母,小寫字母會轉換為大寫字母。
語法
string.swapcase()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.swapcase())
hELLO pYTHON
1、islower()方法
islower() 方法檢測字符串是否由小寫字母組成。
語法
string.islower()
參數值
無參數
str1 = 'Hello Python'
print(str1.islower())
False
如果所有字符均為小寫,則 islower() 方法返回 True,否則返回 False。不檢查數字、符號和空格,僅檢查字母字符。
2、isupper()方法
isupper() 方法檢測字符串中所有的字母是否都為大寫。
語法
string.isupper()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.isupper())
False
如果所有字符均大寫,則 isupper() 方法返回 True,否則返回 False。不檢查數字、符號和空格,僅檢查字母字符。
3、istitle()方法
istitle() 方法檢測字符串中所有的單詞拼寫首字母是否為大寫,且其他字母為小寫。
語法
string.istitle()
參數值
無參數
實例
str1 = 'Hello Python'
print(str1.istitle())
True
如果文本中的所有單詞均以大寫字母開頭,而單詞的其余部分均為小寫字母,則 istitle() 方法返回 True。否則返回 False。符號和數字將被忽略。
count()方法
count() 方法用於統計字符串裡某個字符出現的次數。可選參數為在字符串搜索的開始與結束位置。
語法
string.count(value, start, end)
參數值
實例
txt = "I love apples, apple are my favorite fruit"
print(txt.count("apple", 10, 24))
1
1、find()方法
find() 方法檢測字符串中是否包含子字符串 str ,如果指定 beg(開始) 和 end(結束) 范圍,則檢查是否包含在指定范圍內,如果指定范圍內如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回 -1。
語法
string.find(value, start, end)
參數值
實例
txt = "Hello, welcome to my world."
x = txt.find("e")
print(x)
1
txt = "Hello, welcome to my world."
x = txt.find("e", 5, 10)
print(x)
8
txt = "Hello, welcome to my world."
print(txt.find("q"))
print(txt.index("q"))
Traceback (most recent call last):
File "C:\Users\MK\Desktop\Python方法\str.py", line 4, in <module>
print(txt.index("q"))
ValueError: substring not found
-1
2、index()方法
index() 方法檢測字符串中是否包含子字符串 str ,如果指定 beg(開始) 和 end(結束) 范圍,則檢查是否包含在指定范圍內,該方法與 find() 方法一樣,只不過如果str不在 string中會報一個異常。
語法
string.index(value, start, end)
參數值
實例
txt = "Hello, welcome to my world."
x = txt.index("e")
print(x)
1
txt = "Hello, welcome to my world."
x = txt.index("e", 5, 10)
print(x)
8
txt = "Hello, welcome to my world."
print(txt.find("q"))
print(txt.index("q"))
-1
Traceback (most recent call last):
File "C:\Users\MK\Desktop\Python方法\str.py", line 3, in <module>
print(txt.index("q"))
ValueError: substring not found
3、find() 和 index() 區別
find() 方法與 index() 方法幾乎相同,唯一的區別是,如果找不到該值,index() 方法將引發異常,則 find() 方法將返回 -1。
1、rfind()方法
rfind() 返回字符串最後一次出現的位置,如果沒有匹配項則返回 -1 。
語法
string.rfind(value, start, end)
參數值
實例
txt = "Hello, welcome to my world."
x = txt.rfind("e")
print(x)
13
txt = "Hello, welcome to my world."
x = txt.rfind("e", 5, 10)
print(x)
8
txt = "Hello, welcome to my world."
print(txt.rfind("q"))
print(txt.rindex("q"))
-1
Traceback (most recent call last):
File "C:\Users\MK\Desktop\Python方法\str.py", line 3, in <module>
print(txt.rindex("q"))
ValueError: substring not found
2、rindex()方法
rindex() 返回子字符串 str 在字符串中最後出現的位置,如果沒有匹配的字符串會報異常,你可以指定可選參數[beg:end]設置查找的區間。
語法
string.rindex(value, start, end)
參數值
實例
txt = "Hello, welcome to my world."
x = txt.rindex("e")
print(x)
13
txt = "Hello, welcome to my world."
x = txt.rindex("e", 5, 10)
print(x)
8
txt = "Hello, welcome to my world."
print(txt.rfind("q"))
print(txt.rindex("q"))
-1
Traceback (most recent call last):
File "C:\Users\MK\Desktop\Python方法\str.py", line 3, in <module>
print(txt.rindex("q"))
ValueError: substring not found
3、rfind() 和 rindex() 區別
rfind() 和 rindex() 都是查找指定值的最後一次出現。如果找不到該值,則 rfind() 方法將返回 -1,而 rindex() 方法將引發異常。
1、startswith()方法
startswith() 方法用於檢查字符串是否是以指定子字符串開頭,如果是則返回 True,否則返回 False。如果參數 beg 和 end 指定值,則在指定范圍內檢查。
語法
string.startswith(value, start, end)
參數值
實例
檢查位置 7 到 20 是否以字符 “wel” 開頭:
txt = "Hello, welcome to my world."
x = txt.startswith("wel", 7, 20)
print(x)
True
如果字符串以指定的值開頭,則 startswith() 方法返回 True,否則返回 False。
2、endswith()方法
endswith() 方法用於判斷字符串是否以指定後綴結尾,如果以指定後綴結尾返回 True,否則返回 False。可選參數 “start” 與 “end” 為檢索字符串的開始與結束位置。
語法
string.endswith(value, start, end)
參數值
實例
txt = "Hello, welcome to my world."
x = txt.endswith("my world.")
print(x)
True
txt = "Hello, welcome to my world."
x = txt.endswith("my world.", 5, 11)
print(x)
False
如果字符串以指定值結尾,則 endswith() 方法返回 True,否則返回 False。
encode()和 decode()
encode() 方法以指定的編碼格式編碼字符串,decode() 方法以指定的解碼格式解碼字符串。
errors參數可以指定不同的錯誤處理方案。
語法
string.encode(encoding=encoding, errors=errors)
string.decode(decoding=decoding, errors=errors)
參數值
實例
str = 'pink老師'
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print("UTF-8 編碼:", str_utf8)
print("GBK 編碼:", str_gbk)
print("UTF-8 解碼:", str_utf8.decode('UTF-8', 'strict'))
print("GBK 解碼:", str_gbk.decode('GBK', 'strict'))
UTF-8 編碼: b'pink\xe8\x80\x81\xe5\xb8\x88'
GBK 編碼: b'pink\xc0\xcf\xca\xa6'
UTF-8 解碼: pink老師
GBK 解碼: pink老師
1、center()方法
center() 方法返回一個指定的寬度 width 居中的字符串,fillchar 為填充的字符,默認為空格。
語法
string.center(length, character)
參數值
實例
使用字母 “O” 作為填充字符:
txt = "banana"
x = txt.center(20, "O")
print(x)
OOOOOOObananaOOOOOOO
2、ljust()方法
ljust() 方法返回一個原字符串左對齊,並使用空格填充至指定長度的新字符串。如果指定的長度小於原字符串的長度則返回原字符串。
語法
string.ljust(length, character)
參數值
實例
使用字母 “O” 作為填充字符:
txt = "banana"
x = txt.ljust(20, "O")
print(x)
bananaOOOOOOOOOOOOOO
3、rjust()方法
rjust() 返回一個原字符串右對齊,並使用空格填充至長度 width 的新字符串。如果指定的長度小於字符串的長度則返回原字符串。
語法
string.rjust(length, character)
參數值
實例
使用字母 “O” 作為填充字符:
txt = "banana"
x = txt.rjust(20, "O")
print(x)
OOOOOOOOOOOOOObanana
4、zfill()方法
zfill() 方法返回指定長度的字符串,原字符串右對齊,前面填充0。
語法
string.zfill(len)
參數值
實例
用零填充字符串,直到它們長為 10 個字符:
a = "hello"
b = "welcome to my world"
c = "10.000"
print(a.zfill(10))
print(b.zfill(10))
print(c.zfill(10))
00000hello
welcome to my world
000010.000
zfill() 方法在字符串的開頭添加零(0),直到達到指定的長度。如果 len 參數的值小於字符串的長度,則不執行填充。
1、lstrip()方法
lstrip() 方法用於截掉字符串左邊的空格或指定字符。
語法
string.lstrip(characters)
參數值
實例
刪除前導字符:
txt = ",,,,,ssaaww.....banana"
x = txt.lstrip(",.asw")
print(x)
banana
2、rstrip()方法
rstrip() 刪除 string 字符串末尾的指定字符,默認為空白符,包括空格、換行符、回車符、制表符。
語法
string.rstrip(characters)
參數值
實例
刪除結尾字符:
txt = "banana,,,,,ssaaww....."
x = txt.rstrip(",.asw")
print(x)
banan
3、strip()方法
strip() 方法用於移除字符串頭尾指定的字符(默認為空格)或字符序列。
語法
string.strip(characters)
參數值
實例
刪除前導和尾隨字符:
txt = ",,,,,rrttgg.....banana....rrr"
x = txt.strip(",.grt")
print(x)
banana
1、isspace()方法
isspace() 方法檢測字符串是否只由空白字符組成。
語法
string.isspace()
參數值
無參數
實例
txt = " s "
x = txt.isspace()
print(x)
False
如果字符串中的所有字符都是空格,則 isspace() 方法將返回 True,否則返回 False。
2、isprintable()方法
isprintable() 方法檢查文本中的所有字符是否可打印。
語法
string.isprintable()
參數值
無參數
實例
txt = "Hello!\nAre you #1?"
x = txt.isprintable()
print(x)
False
如果所有字符都是可打印的,則 isprintable() 方法返回 True,否則返回 False。不可打印的字符可以是回車和換行符。
3、isidentifier()方法
isidentifier() 方法檢查字符串是否是有效標識符。
語法
string.isidentifier()
參數值
無參數
實例
a = "MyFolder"
b = "Demo002"
c = "2bring"
d = "my demo"
print(a.isidentifier())
print(b.isidentifier())
print(c.isidentifier())
print(d.isidentifier()
True
True
False
False
如果字符串是有效標識符,則 isidentifier() 方法返回 True,否則返回 False。
如果字符串僅包含字母數字字母(a-z)和(0-9)或下劃線(_),則該字符串被視為有效標識符。有效的標識符不能以數字開頭或包含任何空格。
4、isalnum()方法
isalnum() 方法檢測字符串是否由字母和數字組成。
語法
string.isalnum()
參數值
無參數
實例
檢查文本中的所有字符是否都是字母數字:
txt = "Company 12"
x = txt.isalnum()
print(x)
False
如果所有字符均為字母數字,即字母(a-z)和數字(0-9),則 isalnum() 方法返回 True。
非字母數字的例子:(space)!#%&? 等等。
5、isalpha()方法
isalpha() 方法檢測字符串是否只由字母或文字組成。
語法
string.isalpha()
參數值
無參數
實例
檢查文本中的所有字符是否都是字母:
txt = "Company10"
x = txt.isalpha()
print(x)
False
如果所有字符都是字母(a-z),則 isalpha() 方法將返回 True。
非字母的字符例子:(space)!#%&? 等等。
6.1、isdigit()方法
isdigit() 方法檢測字符串是否只由數字組成。
語法
string.isdigit()
參數值
無參數
實例
檢查文本中的所有字符是否都是字母:
a = "\u0030" # unicode for 0
b = "\u00B2" # unicode for ²
print(a.isdigit())
print(b.isdigit())
True
True
如果所有字符都是數字,則 isdigit() 方法將返回 True,否則返回 False。
指數(例如²)也被視作數字。
6.2、isnumeric()方法
isnumeric() 方法檢測字符串是否只由數字組成,數字可以是: Unicode 數字,全角數字(雙字節),羅馬數字,漢字數字。
指數類似 ² 與分數類似 ½ 也屬於數字。
語法
string.isnumeric()
參數值
無參數
實例
檢查字符是否為數字:
a = "\u0030" # unicode for 0
b = "\u00B2" # unicode for ²
c = "10km2"
print(a.isnumeric())
print(b.isnumeric())
print(c.isnumeric())
True
True
False
如果所有字符均為數字(0-9),則 isumeric() 方法返回 True,否則返回 False。
指數(比如 ² 和 ¾)也被視為數字值。
6.3、isdecimal()方法
isdecimal() 方法檢查 unicode 對象中的所有字符是否都是小數。
語法
string.isdecimal()
參數值
無參數
實例
檢查 unicode 中的所有字符是否都是小數:
a = "\u0030" # unicode for 0
b = "\u0047" # unicode for G
print(a.isdecimal())
print(b.isdecimal())
True
False
如果所有字符均為小數(0-9),則 isdecimal() 方法將返回 True。
此方法用於 unicode 對象。
1、format()方法
format() 方法格式化指定的值,並將其插入字符串的占位符內,占位符使用大括號 {} 定義。
語法
string.format(value1, value2...)
參數值
占位符
可以使用命名索引 {price}、編號索引{0}、甚至空的占位符 {} 來標識占位符。
實例
使用不同的占位符值:
txt1 = "My name is {fname}, I'am {age}".format(fname="Bill", age=64)
txt2 = "My name is {0}, I'am {1}".format("Bill", 64)
txt3 = "My name is {}, I'am {}".format("Bill", 64)
print(txt1)
print(txt2)
print(txt3)
My name is Bill, I'am 64
My name is Bill, I'am 64
My name is Bill, I'am 64
格式化類型
在占位符內,您可以添加格式化類型以格式化結果:
2、format_map()方法
format_map() 方法格式化字符串中的指定值。
語法
str.format_map(mapping)
參數值
實例
str_a = '我是 {name} 老師 {gender} {age} 歲'
dict_1 = {
'name': 'pink', 'gender': '男', 'age': 21}
print(str_a.format_map(dict_1))
我是 pink 老師 男 21 歲
1、split()方法
split() 通過指定分隔符從左側對字符串進行切片,如果第二個參數 num 有指定值,則分割為 num+1 個子字符串。
語法
string.split(separator, max)
參數值
實例
txt = "hello, my name is Bill, I am 63 years old"
x = txt.split(", ")
print(x)
['hello', 'my name is Bill', 'I am 63 years old']
txt = "apple#banana#cherry#orange"
x = txt.split("#")
print(x)
['apple', 'banana', 'cherry', 'orange']
txt = "apple#banana#cherry#orange"
# 將 max 參數設置為 1,將返回包含 2 個元素的列表!
x = txt.split("#", 1)
print(x)
['apple', 'banana#cherry#orange']
split() 方法將字符串拆分為列表。
您可以指定分隔符,默認分隔符是任何空白字符。
**注釋:**若指定 max,列表將包含指定數量加一的元素。
2、rsplit()方法
rsplit() 通過指定分隔符從右側對字符串進行切片,如果第二個參數 num 有指定值,則分割為 num+1 個子字符串。
語法
string.rsplit(separator, max)
參數值
實例
將字符串拆分為最多 2 個項目的列表:
txt = "apple, banana, cherry"
# 將 max 參數設置為 1,將返回包含 2 個元素的列表!
x = txt.rsplit(", ", 1)
print(x)
['apple, banana', 'cherry']
rsplit() 方法從右側開始將字符串拆分為列表。
如果未指定 “max”,則此方法將返回與 split() 方法相同的結果。
注釋: 若指定 max,列表將包含指定數量加一的元素。
3、splitlines()方法
splitlines() 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一個包含各行作為元素的列表,如果參數 keepends 為 False,不包含換行符,如果為 True,則保留換行符。
語法
string.splitlines(keeplinebreaks)
參數值
實例
拆分字符串,但保留換行符:
txt = "Thank you for your visiting\nWelcome to China"
x = txt.splitlines(True)
print(x)
['Thank you for your visiting\n', 'Welcome to China']
1、partition()方法
partition() 方法搜索指定的字符串,並將該字符串拆分為包含三個元素的元組。
第一個元素包含指定字符串之前的部分,第二個元素包含指定的字符串,第三個元素包含字符串後面的部分。
注釋:此方法搜索指定字符串的第一個匹配項。
語法
string.partition(value)
參數值
實例
txt = "I could eat bananas all day"
x = txt.partition("bananas")
print(x)
('I could eat ', 'bananas', ' all day')
txt = "I could eat bananas all day"
x = txt.partition("apples")
print(x)
('I could eat bananas all day', '', '')
2、rpartition()方法
rpartition() 方法搜索指定字符串的最後一次出現,並將該字符串拆分為包含三個元素的元組。
第一個元素包含指定字符串之前的部分,第二個元素包含指定的字符串,第三個元素包含字符串之後的部分。
語法
string.rpartition(value)
參數值
實例
txt = "I could eat bananas all day, bananas are my favorite fruit"
x = txt.rpartition("bananas")
print(x)
('I could eat bananas all day, ', 'bananas', ' are my favorite fruit')
txt = "I could eat bananas all day, bananas are my favorite fruit"
x = txt.rpartition("apples")
print(x)
('', '', 'I could eat bananas all day, bananas are my favorite fruit')
1、maketrans()方法
maketrans() 方法用於創建字符映射的轉換表,對於接受兩個參數的最簡單的調用方式,第一個參數是字符串,表示需要轉換的字符,第二個參數也是字符串表示轉換的目標。
兩個字符串的長度必須相同,為一一對應的關系。
語法
string.maketrans(x[, y[, z]])
參數值
2、translate()方法
translate() 返回被轉換的字符串。
實例
txt = "www.Baidu.com"
url = txt.maketrans('B', 'b')
print(txt.translate(url))
www.baidu.com
x = "aeiou"
y = "12345"
trans = str.maketrans(x, y)
str1 = "this is a string"
print(str1.translate(trans))
th3s 3s 1 str3ng
txt = "baidu z alibaba Z tencent"
x = "bat"
y = "BAT"
z = "zZ" # 設置刪除的字符
trans = txt.maketrans(x, y, z)
print(txt.translate(trans))
print(trans)
BAidu AliBABA TencenT
{
98: 66, 97: 65, 116: 84, 122: None, 90: None
join()方法
join() 方法用於將序列中的元素以指定的字符連接生成一個新的字符串。
語法
string.join(iterable)
參數值
實例
tuple_1 = ("baidu", "alibaba", "tencent")
x = "#".join(tuple_1)
print(x)
baidu#alibaba#tencent
dict_1 = {
"name": "Bill", "country": "USA"}
separator = "TEST"
x = separator.join(dict_1)
print(x)
nameTESTcountry
replace()方法
replace() 方法把字符串中的 old(舊字符串) 替換成 new(新字符串),如果指定第三個參數max,則替換不超過 max 次。
語法
string.replace(oldvalue, newvalue, count)
參數值
實例
txt = "I like bananas"
x = txt.replace("bananas", "apples")
print(x)
I like apples
txt = "one one was a race horse, two two was one too."
x = txt.replace("one", "three")
print(x)
three three was a race horse, two two was three too.
txt = "one one was a race horse, two two was one too."
x = txt.replace("one", "three", 2)
print(x)
three three was a race horse, two two was one too.
expandtabs()方法
expandtabs() 方法把字符串中的 tab 符號 \t 轉為空格,tab 符號 \t 默認的空格數是 8,在第 0、8、16…等處給出制表符位置,如果當前位置到開始位置或上一個制表符位置的字符數不足 8 的倍數則以空格代替。
語法
string.exandtabs(tabsize)
參數值
實例
txt = "H\te\tl\tl\to"
x = txt.expandtabs(2)
print(x)
H e l l o
txt = "H\te\tl\tl\to"
print(txt)
print(txt.expandtabs())
print(txt.expandtabs(2))
print(txt.expandtabs(4))
print(txt.expandtabs(10))
H e l l o
H e l l o
H e l l o
H e l l o
H e l l o
以上就是本文的全部內容啦!如果對您有幫助,麻煩點贊啦!收藏啦!歡迎各位評論區留言!!!
最後編輯於:2022/7/31 16:27