https://house.leju.com/as/new/#wt_source=pc_csss_mf_zxlp
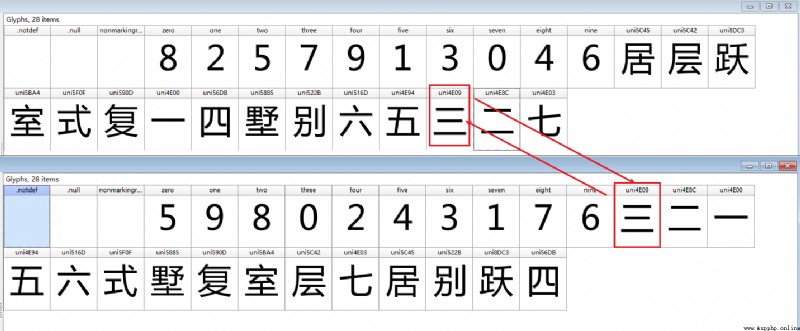
import requests
import io
from lxml import etree
import base64
from fontTools.ttLib import TTFont
detail_url = 'https://house.leju.com/as/new/#wt_source=pc_csss_mf_zxlp'
res = requests.get(detail_url)
tree = etree.HTML(res.text)
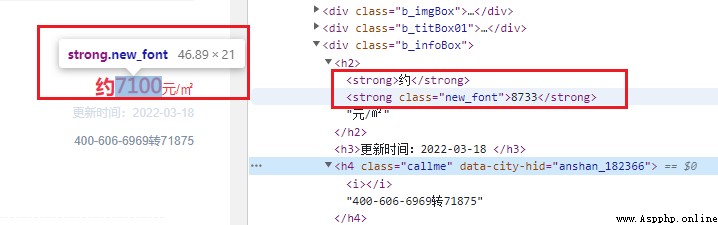
style = tree.xpath("//style/text()")
font_face = style[0]
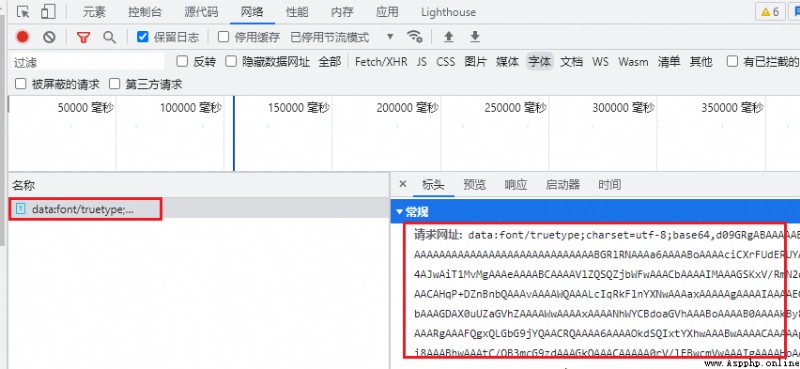
font_char = font_face.split("src: url(data:font/truetype;charset=utf-8;base64,")[1].split(") format('woff');")[0]
# print(font_char)
# 轉換為字體文件
font_file_io = base64.b64decode(font_char)
print(type(font_file_io))
# 加載字體二進制流
font = TTFont(io.BytesIO(font_file_io))
print(font)
# 測試一下字體文件
font_map = font['cmap'].getBestCmap()
print(font_map)

 Tensorflow C++ deployment practice - python environment establishment on linux platform (2)
Tensorflow C++ deployment practice - python environment establishment on linux platform (2)
1. Virtual environment install