1、爬蟲的簡單定義
網絡爬蟲,又稱為網頁蜘蛛、螞蟻、蠕蟲、模擬程序,在FOAF社區中,被稱為二王爺追逐者。是一種按照一定的規則,自動抓取萬維網信息的程序或者腳本。簡單來說,網絡爬蟲就是使用事先寫好的程序去抓取網絡上所需要的數據。
2、通用網絡爬蟲
搜索引擎的第一步就是爬蟲,但是搜索引擎中的爬蟲是一種廣泛獲取各種網頁信息的程序,除了HTML文件外,搜索引擎通常還會抓取和索引文字為基礎的多種文件類型,如TXT,WORD,PDF等。但是對於圖片, 視頻,等非文字的內容則一般不會處理,並且對於腳本和一些網頁中的程序也不會處理的。
3、聚焦網絡爬蟲(主要學習方向)
針對某一特定領域的數據進行抓取的程序。比如旅游網站,金融網站,招聘網站等等;特定領域的聚集爬蟲會使用各種技術去處理我們需要的信息,所以對於網站中動態的那些程序,腳本仍會執行,以保證確定能抓取到網站中的數據。
4、爬蟲的用途
5、爬蟲的合法性問題
1)目前還處於不明確的蠻階段,“哪些行為不允許”這種基本秩序還處於建設中。
2)至少目前來看,如果抓取的數據為個人所用,則不存在問題;如果數據用於轉載,那麼抓取數據的類型就很重要了
3)一般來說,當抓取的數據是實現生活中的真實數據(比如,營業地址,電話清單)時,是允許轉載的。但如果是原創數據(文章、意見、評論),通常就會受到版權限制,而不能轉載。
4)不管怎麼樣,作為一個訪客,應當約束自己的抓取行為,這就是說要求下.載請求的速度需要限定在一個合理值之內,並且還需要設定一個專屬的用戶代理來標識自己。
6、robots.txt文檔
就是一個君子協議,記錄了一些網站允許其他網站爬取的范圍(allow允許,disallow不允許),比如: https://www.baidu.com/robots.txt和 https://www.douban.com/robots.txt
7、網站地圖sitemap
sitemap是一個網站所有鏈接的容器,是一個xml文檔。很多網站的連接層次比較深,很難抓取到,網站地圖可以方便搜索引擎蜘蛛抓取網站頁面,通過抓取網站頁面,清晰了解網站的架構,網站地圖一般存放在根目錄下並命名為sitemap,為搜索引擎蜘蛛指路,增加網站重要內容頁面的收錄。網站地圖就是根據網站的結構、框架、內容,生成的導航網頁文件。大多數人都知道網站地圖對於提高用戶體驗有好處:它們為網站訪問者指明方向,並幫助迷失的訪問者找到他們想看的頁面。
比如: https://www.mafengwo.cn/sitemapIndex.xml和 http://www.170hi.com/sitemap.xml
8、深度優先與廣度優先
1)深度優先策略
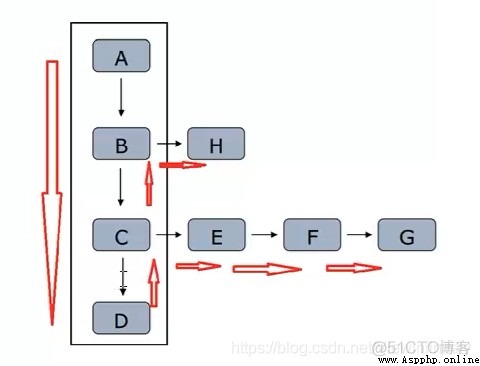
2)廣度優先策略
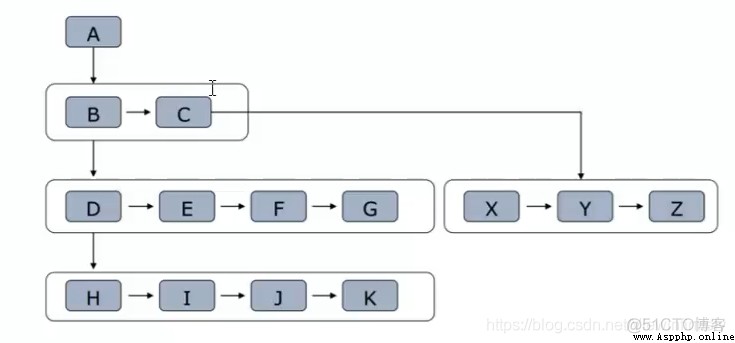
9、HTTP與HTTPS協議
1、Web 前端的知識: HTML,CSS,JavaScript,DOM,DHTML,Ajax,jQuery,json等。
2、正則表達式,能提取正常一般網頁中想要的信息,比如某些特殊的文字,鏈接信息,知道什麼是懶惰,什麼是貪婪型的正則。
3、(重點)會使用re,BeautifulSoup,XPath等獲取一些DOM結構中的節點信息。
4、(算法)知道什麼是深度優先,廣度優先的抓取算法,及實踐中的使用規則。
5、 能分析簡單網站的結構,會使用urllib、requests 庫進行簡單的數據抓取。
1、了解什麼是Hash,會使用簡單的MD5、SHA1等算法對數據進行Hash以便存儲。
2、熟悉HTTP、HTTPS(更安全,使用了應用層加密)協議的基礎知識,了解GET、POST方法,了解HTTP頭中的信息,包括返回狀態碼,編碼,userlagent, cookie, session等。
3、能設置User-Agent進行數據爬取,設置代理等。
4、知道什麼是Request、什麼是Response,會使用Fiddle, Wireshark等工具抓取及分析簡單的網絡數據包;對於動態爬蟲,要學會分析Ajax請求,模擬制造Post數據包請求,抓取客戶端session等信息,對於一些簡單的網站,能夠通過模擬數據包進行自動登錄。
5、對於比較難搞定的網站,學會使用浏覽器+selenium抓取一些動態網頁信息。
6、並發下載,通過並行下載加速數據抓取,多線程的使用。
1、能使用Tesseract, 百度AI、HQG+SVM、CNN等庫進行驗證碼識別。
2、能使用數據挖掘的技術,分類算法等避兔死鏈等。
3、會使用常用的數據庫進行數據存儲,查詢,如Mongodb, Redis(大數據量的緩存)等;下載緩存,學習如何通過緩存避免重復下載的問題; Bloom Filter 的使用。
4、能使用機器學習的技術動態調整爬蟲的爬取策略,從而避免被禁IP封號等。
5、能使用一些開源框架Scrapy、Celery等分布式爬蟲,能部署掌控分布式爬蟲進行大規模的數據抓取。