目前測試用例使用excel整理後,後期需要變成word文件。采用手工粘貼賦值整理費時費力,隨采用python程序處理,從工具人解放出來。
excel的用例如下,一般會有很多模塊,且至少包含所屬模塊,用例標題,前置條件,步驟,預期結果等內容 。
需要生成Word的內容如下,就是將excel的內容填充到以下。
1.使用pandas讀取excel中列的內容
2.將同模塊的用例保存到同一個對象(用來生成一個word文件)
3.采用DocxTemplate根據模板生成word文件
def creatData(file):
""" :param file: 需要生成數據的excle文件 :return: 序列號數據 """
df = pd.read_excel(file)
test_data = []
for i in df.index.values:
# 根據i來獲取每一行指定的數據 並利用to_dict轉成字典
row_data = df.loc[i, excelCol].to_dict()
test_data.append(row_data)
return test_data
excelCol = ['所屬模塊', '用例標題', '步驟', '預期', '前置條件']
# 獲取excel中列的去重內容
data_moudle = pd.read_excel(excelFile)
moudle = pd.DataFrame(data_moudle['所屬模塊']).drop_duplicates(subset=None, keep='first', inplace=False).to_dict('list')[
"所屬模塊"]
allData = []
# 聲明拼接的數組,用來生成文件內容
for i in moudle:
item = {
"SSMK": i, "table": []}
allData.append(item)
for name in test_data:
for index, key in enumerate(moudle):
if name[excelCol[0]] == key:
allData[index]["table"].append(
{
"YLBT": zhaunyi(name[excelCol[1]]), "BZ": zhaunyi(name[excelCol[2]]), "YQ": zhaunyi(name[excelCol[3]]),
"QZTJ": zhaunyi(name[excelCol[4]])})
模板文件tem.docx如下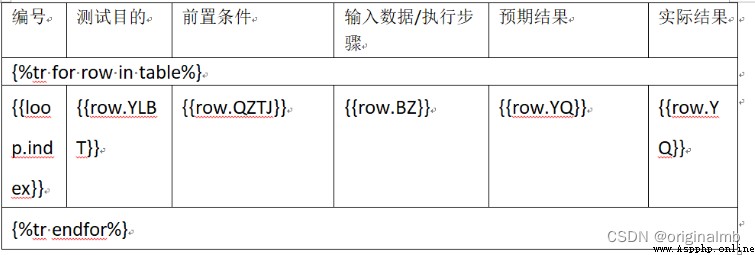
def createDoc(contexts):
""" :param contexts: 生成文件的內容 :return: 生成文件 """
for index, context in enumerate(contexts):
doc = DocxTemplate("template/tem.docx")
# 執行替換
doc.render(context)
# #保存新的文檔
doc.save("./case/%s.docx" % (str(index) ))
會根據excel中的模塊生成對應的docx文件,此文章有三個模塊,則會生成三個文件。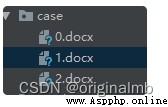
# -*- coding:utf-8 -*-
import pandas as pd
from docxtpl import DocxTemplate
import os
import shutil
# 聲明需要生成的所屬模塊
# 讀取excel的文件包括路徑和名稱以及後綴名稱
excelFile = 'excelCase/test.xlsx'
# 讀取excel中的列,順序不能變,列名稱要跟excel的名稱對應
excelCol = ['所屬模塊', '用例標題', '步驟', '預期', '前置條件']
# 獲取excel中列的去重內容
data_moudle = pd.read_excel(excelFile)
moudle = pd.DataFrame(data_moudle['所屬模塊']).drop_duplicates(subset=None, keep='first', inplace=False).to_dict('list')[
"所屬模塊"]
print(moudle)
def zhaunyi(str):
# 由於excel中某些單元格為空,因此處理為無
# AttributeError: 'float' object has no attribute 'replace'
if (type(str) == float):
return '無';
""" :param str: 需要轉義的內容 :return: 將特殊字符轉義 """
return str.replace("&", "&").replace("<", "<").replace(">", ">")
def createDoc(contexts):
""" :param contexts: 生成文件的內容 :return: 生成文件 """
for index, context in enumerate(contexts):
doc = DocxTemplate("template/tem.docx")
# 執行替換
print(context)
print(index)
doc.render(context)
# #保存新的文檔
# doc.save("./case/%s.docx" % (str(index) + "-" + str(context.get("SSMK")).replace("/", "-")))
doc.save("./case/%s.docx" % (str(index) ))
def cleanDoc(file):
""" :param file: 傳入需要清空的文件目錄 :return: 從新生成文件目錄 """
if os.path.exists(file):
# 刪除case目錄
shutil.rmtree(file)
# 創建目錄
os.mkdir(file)
allData = []
# 聲明拼接的數組,用來生成文件內容
for i in moudle:
item = {
"SSMK": i, "table": []}
allData.append(item)
def creatData(file):
""" :param file: 需要生成數據的excle文件 :return: 序列號數據 """
df = pd.read_excel(file)
test_data = []
for i in df.index.values:
# 根據i來獲取每一行指定的數據 並利用to_dict轉成字典
row_data = df.loc[i, excelCol].to_dict()
test_data.append(row_data)
return test_data
test_data = creatData(excelFile)
for name in test_data:
for index, key in enumerate(moudle):
if name[excelCol[0]] == key:
allData[index]["table"].append(
{
"YLBT": zhaunyi(name[excelCol[1]]), "BZ": zhaunyi(name[excelCol[2]]), "YQ": zhaunyi(name[excelCol[3]]),
"QZTJ": zhaunyi(name[excelCol[4]])})
cleanDoc("./case")
createDoc(allData)
 Can Python crawlers be a sideline? At which level can I take orders? Parsing the ways Python crawlers make money
Can Python crawlers be a sideline? At which level can I take orders? Parsing the ways Python crawlers make money
Many friends asked me to learn