1.進入獲取疫情的url
例如:
騰訊新聞的疫情網站 https://news.qq.com/zt2020/page/feiyan.htm#/
網易新聞:https://wp.m.163.com/163/page/news/virus_report/index.html_nw_=1&anw=1
只需要找到網站的url以及user-agent後,進入url查看json數據格式,按照步驟即可訪問。
2.為了避免反爬,偽裝成浏覽器:
找到headers = {‘user-agent’ : ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55’} ,進行浏覽器訪問。
3.分析url,找到數據存放的規律
4.進行數據讀取和存儲
import requests #爬取網頁
import json #json文件可以通過角標索引讀取內容 爬取json文件
import xlwings as xw #導入excel
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=329822670771' #請求URL
headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'} #浏覽器訪問
response = requests.get(url , headers = headers)
#print(response.status_code) #200表示訪問成功
#print(response.json()) # 打印內容
wb = xw.Book() #相當於打開excel操作
sht = wb.sheets('sheet1') #相當於在excel裡加了一個工作表
sht.range('A1').values = '地區'
sht.range('B1').values = '新增確診'
sht.range('C1').values = '累計確診'
sht.range('D1').values = '死亡'
sht.range('E1').values = '治愈'
sht.range('F1').values = '日期'
在進入url分析數據格式後,將數據取出放入excel中。
json_data = response.json()['data']['areaTree']
#print(json_data)
for i in range(206):
earth_data = json_data[i]
#print(earth_data)
name = earth_data['name']
sht.range(f'A{i+2}').value = name
today_confirm = json.dumps(earth_data['today']['confirm'])
sht.range(f'B{i+2}').value = today_confirm
total_confirm = json.dumps(earth_data['total']['confirm'])
sht.range(f'C{i+2}').value = total_confirm
total_dead = json.dumps(earth_data['total']['dead'])
sht.range(f'D{i+2}').value = total_dead
total_heal = json.dumps(earth_data['total']['heal'])
sht.range(f'E{i+2}').value = total_heal
date = earth_data['lastUpdateTime']
sht.range(f'F{i+2}').value = date
#print("地區:"+name, "新增確診:"+today_confirm, "累計確診:"+total_confirm , "死亡"+total_dead,"治愈"+total_heal)
運行結果: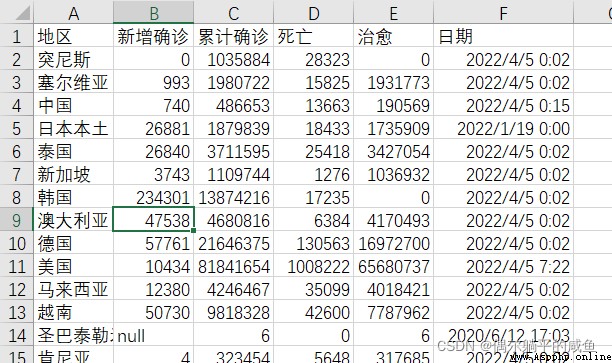
import requests #爬取網頁
import json #爬取數據
import xlwings as xw #導入excel
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=329822670771'
headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'}
response = requests.get(url , headers = headers)
#print(response.status_code) #200表示訪問成功
#print(response.json()) # 打印內容
wb = xw.Book() #相當於打開excel操作
sht = wb.sheets('sheet1') #相當於在excel裡加了一個工作表
sht.range('A1').values = '地區'
sht.range('B1').values = '新增確診'
sht.range('C1').values = '累計確診'
sht.range('D1').values = '死亡'
sht.range('E1').values = '治愈'
sht.range('F1').values = '日期'
json_data = response.json()['data']['chinaDayList']
#print(json_data)
for i in range(59):
earth_data = json_data[i]
#print(earth_data)
#name = earth_data['name']
#sht.range(f'A{i+2}').value = name
today_confirm = json.dumps(earth_data['today']['confirm'])
sht.range(f'B{i+2}').value = today_confirm
total_confirm = json.dumps(earth_data['total']['confirm'])
sht.range(f'C{i+2}').value = total_confirm
total_dead = json.dumps(earth_data['total']['dead'])
sht.range(f'D{i+2}').value = total_dead
total_heal = json.dumps(earth_data['total']['heal'])
sht.range(f'E{i+2}').value = total_heal
date = earth_data['date']
sht.range(f'F{i+2}').value = date
#print("地區:"+name, "新增確診:"+today_confirm, "累計確診:"+total_confirm , "死亡"+total_dead,"治愈"+total_heal)
運行結果: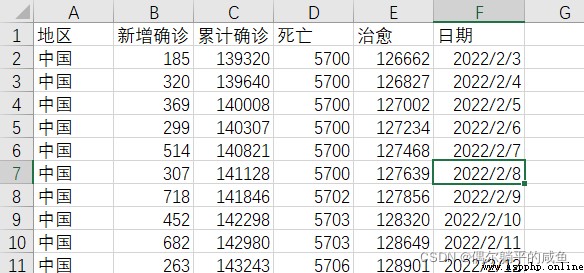
import requests #爬取網頁
import json #爬取數據
import xlwings as xw #導入excel
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=7&t=1649117007316'
headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'}
response = requests.get(url , headers = headers)
wb = xw.Book() #相當於打開excel操作
sht = wb.sheets('sheet1') #相當於在excel裡加了一個工作表
sht.range('A1').values = '地區'
sht.range('B1').values = '新增確診'
sht.range('C1').values = '累計確診'
sht.range('D1').values = '死亡'
sht.range('E1').values = '治愈'
sht.range('F1').values = '日期'
json_data = response.json()['data']['list']
#print(json_data)
for i in range(772):
earth_data = json_data[i]
#print(earth_data)
#name = earth_data['name']
#sht.range(f'A{i+2}').value = name
today_confirm = json.dumps(earth_data['today']['confirm'])
sht.range(f'B{i+2}').value = today_confirm
total_confirm = json.dumps(earth_data['total']['confirm'])
sht.range(f'C{i+2}').value = total_confirm
total_dead = json.dumps(earth_data['total']['dead'])
sht.range(f'D{i+2}').value = total_dead
total_heal = json.dumps(earth_data['total']['heal'])
sht.range(f'E{i+2}').value = total_heal
date = earth_data['date']
sht.range(f'F{i+2}').value = date
運行結果: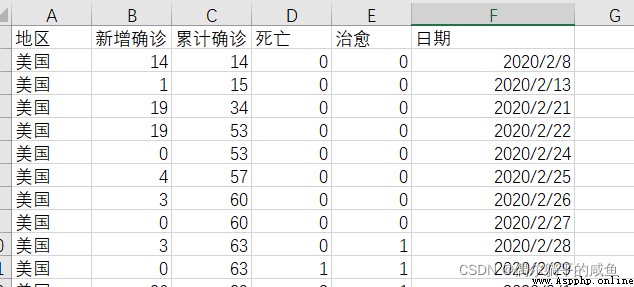
import pandas as pd
import requests
import json
def get_data():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
area = requests.get(url).json()
data = json.loads(area['data'])
update_time = data['lastUpdateTime']
all_counties = data['areaTree']
all_list = []
for country_data in all_counties:
if country_data['name'] != '中國':
continue
else:
all_provinces = country_data['children']
for province_data in all_provinces:
province_name = province_data['name']
all_cities = province_data['children']
for city_data in all_cities:
city_name = city_data['name']
city_total = city_data['total']
province_result = {'province': province_name, 'city': city_name,'update_time': update_time}
province_result.update(city_total)
all_list.append(province_result)
df = pd.DataFrame(all_list)
df.to_csv('data.csv', index=False,encoding="utf_8_sig")
get_data()
運行結果: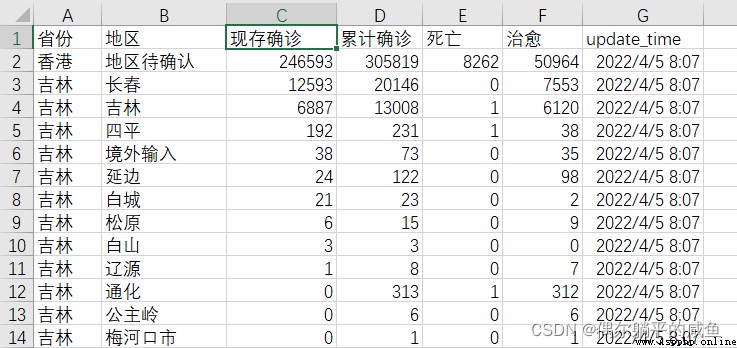
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦







