目錄
1 項目背景
2 項目目標
3 項目分析
3.1數據獲取
3.1.1分析網站
3.1.2找到數據所在url
3.1.3獲取數據
3.1.4解析數據
3.1.5保存數據
3.2數據可視化
3.2.1讀取數據
3.2.2各地區確診人數與死亡人數情況條形圖
3.2.3各地區現有確診人數地圖
3.2.4各地區現有確診人數分布環形圖
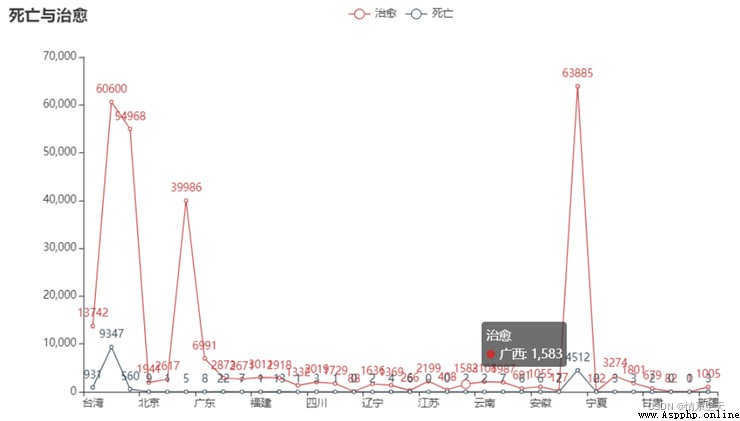
3.2.4各地區現有確診人數分布折線圖
項目源碼:
2019年底,肺炎(COVID-19)在全球爆發,後來被確認為新型冠狀病毒(SARS-CoV-2)所引發的。
我們在爬取到公開數據的條件下,開展了一些可視化工作希望能夠幫助大家更好理解現在疫情的發展情況,更有信心一起戰勝肆虐的病毒。
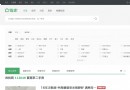
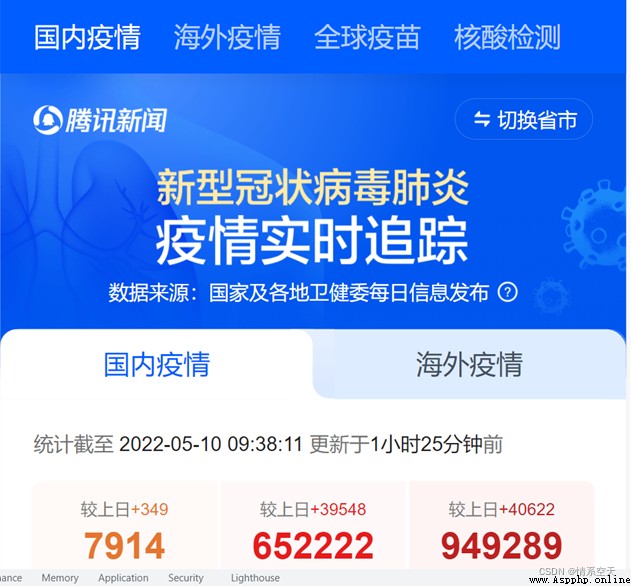
先去先找到今天要爬取的目標數據:
https://news.qq.com/zt2020/page/feiyan.htm#/
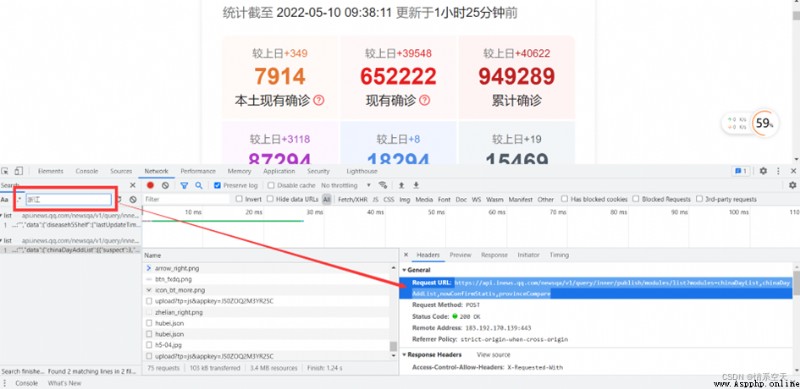
url點擊跳轉查看
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
通過爬蟲獲取它的json數據:
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
response = requests.get(url, verify=False)
json_data = response.json()['data']
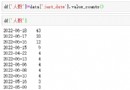
china_data = json_data['diseaseh5Shelf']['areaTree'][0]['children'] # 列表
通過一個for循環對我們的列表進行取值然後再存入到我們的字典中
data_set = []
for i in china_data:
?data_dict = {}
?# 地區名稱
?data_dict['province'] = i['name']
?# 新增確認
?data_dict['nowConfirm'] = i['total']['nowConfirm']
?# 死亡人數
?data_dict['dead'] = i['total']['dead']
??? # 治愈人數
? data_dict['heal'] = i['total']['heal']
data_set.append(data_dict)
df = pd.DataFrame(data_set)
df.to_csv(‘yiqing_data.csv’)
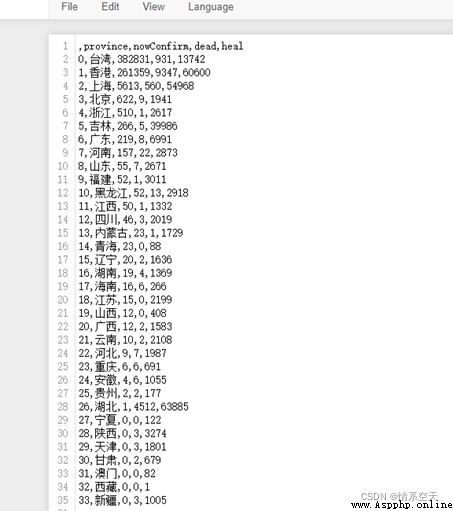
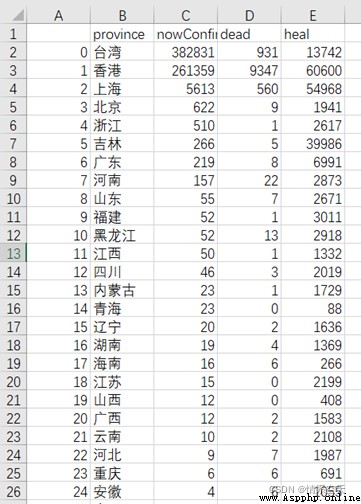
df2 = df.sort_values(by=[‘nowConfirm’],ascending=False)[:9]
df2
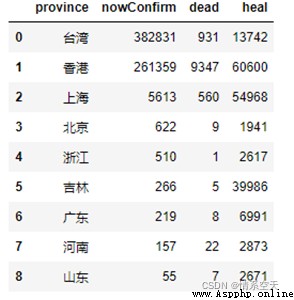
bar = (
??? Bar()
??? .add_xaxis(list(df['province'].values)[:6])
??? .add_yaxis("死亡", df['dead'].values.tolist()[:6])
??? .add_yaxis("治愈", df['heal'].values.tolist()[:6])
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="各地區確診人數與死亡人數情況"),
??????? datazoom_opts=[opts.DataZoomOpts()],
??????? )
)
bar.render_notebook()
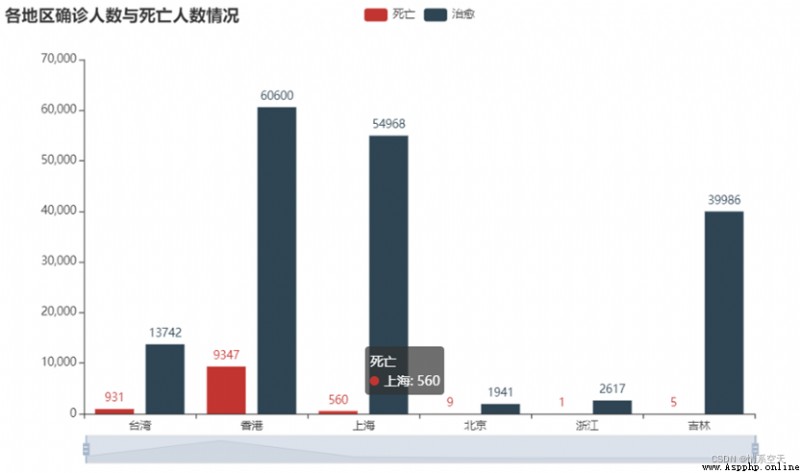
china_map = (
??? Map()
??? .add("現有確診", [list(i) for i in zip(df['province'].values.tolist(),df['nowConfirm'].values.tolist())], "china")
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="各地區確診人數"),
??????? visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=True),
??? )
)
china_map.render_notebook()
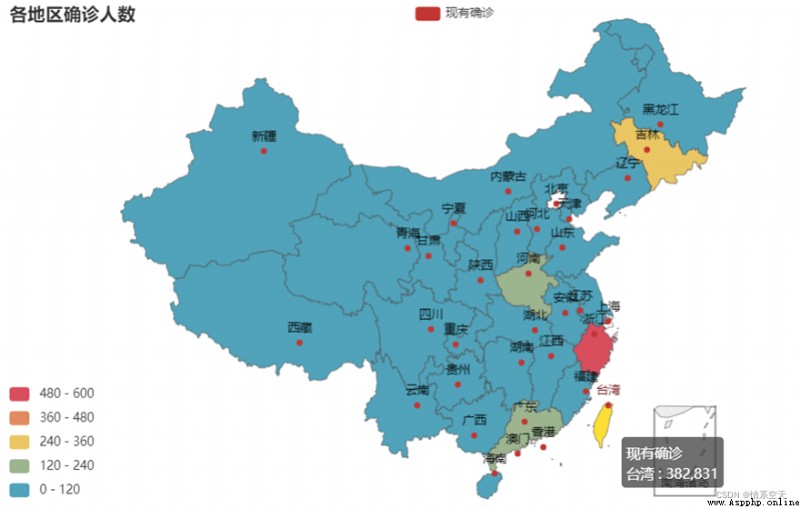
pie = (
??? Pie()
??? .add(
??????? "",
??????? [list(i) for i in zip(df2['province'].values.tolist(),df2['nowConfirm'].values.tolist())],
??????? radius = ["10%","30%"]
??? )
??? .set_global_opts(
??????????? legend_opts=opts.LegendOpts(orient="vertical", pos_top="70%", pos_left="70%"),
??? )
??? .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()
line = (
??? Line()
??? .add_xaxis(list(df['province'].values))
??? .add_yaxis("治愈", df['heal'].values.tolist())
??? .add_yaxis("死亡", df['dead'].values.tolist())
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="死亡與治愈"),
??? )
)
line.render_notebook()
import requests # 發送網絡請求模塊
import json
import pprint # 格式化輸出模塊
import pandas as pd # 數據分析當中一個非常重要的模塊
from pyecharts import options as opts
from pyecharts.charts import Bar,Line,Pie,Map,Grid
import urllib3
from pyecharts.globals import CurrentConfig, NotebookType
# 配置對應的環境類型
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_NOTEBOOK
CurrentConfig.ONLINE_HOST='https://assets.pyecharts.org/assets/'
urllib3.disable_warnings()#解決InsecureRequestWarning: Unverified HTTPS request is being made to host 'api.inews.qq.com'. 問題
url = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
response = requests.get(url, verify=False)
json_data = response.json()['data']
china_data = json_data['diseaseh5Shelf']['areaTree'][0]['children'] # 列表
data_set = []
for i in china_data:
data_dict = {}
# 地區名稱
data_dict['province'] = i['name']
# 新增確認
data_dict['nowConfirm'] = i['total']['nowConfirm']
# 死亡人數
data_dict['dead'] = i['total']['dead']
# 治愈人數
data_dict['heal'] = i['total']['heal']
data_set.append(data_dict)
df = pd.DataFrame(data_set)
df.to_csv('yiqing_data.csv')
df2 = df.sort_values(by=['nowConfirm'],ascending=False)[:9]
df2
# bar = (
# Bar()
# .add_xaxis(list(df['province'].values)[:6])
# .add_yaxis("死亡", df['dead'].values.tolist()[:6])
# .add_yaxis("治愈", df['heal'].values.tolist()[:6])
# .set_global_opts(
# title_opts=opts.TitleOpts(title="各地區確診人數與死亡人數情況"),
# datazoom_opts=[opts.DataZoomOpts()],
# )
# )
# bar.render_notebook()
# china_map = (
# Map()
# .add("現有確診", [list(i) for i in zip(df['province'].values.tolist(),df['nowConfirm'].values.tolist())], "china")
# .set_global_opts(
# title_opts=opts.TitleOpts(title="各地區確診人數"),
# visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=True),
# )
# )
# china_map.render_notebook()
# pie = (
# Pie()
# .add(
# "",
# [list(i) for i in zip(df2['province'].values.tolist(),df2['nowConfirm'].values.tolist())],
# radius = ["10%","30%"]
# )
# .set_global_opts(
# legend_opts=opts.LegendOpts(orient="vertical", pos_top="70%", pos_left="70%"),
# )
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# )
# pie.render_notebook()
line = (
Line()
.add_xaxis(list(df['province'].values))
.add_yaxis("治愈", df['heal'].values.tolist())
.add_yaxis("死亡", df['dead'].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="死亡與治愈"),
)
)
line.render_notebook()
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦