說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最後獲取。

1.項目背景
隨著互聯網的發展,越來越多的用戶通過互聯網來交流,電子郵件成為人們日常生活交流的重要工具。用戶每星期可能收到成百上千的電子郵件,但是大部分是垃圾郵件。據時代雜志估計,1994年人們發送了7760億封電子郵件,1997年則是26000億封,2000年更是達到了66000億封。電子郵件特別是垃圾郵件的泛濫已經嚴重影響電子商務活動的正常開展。人們通常要花費很多時間對電子郵件進行處理,但效果卻不明顯,嚴重影響了正常的商務活動。對郵件進行合理的分類,為用戶挑選出有意義的電子郵件是所有用戶的迫切要求。
目前的郵件分類方法大多是將郵件分為垃圾郵件與非垃圾郵件,從而實現對郵件的自動過濾。本項目基於詞袋模型特征和TFIDF特征進行支持向量機模型中文郵件分類,郵件類別分為正常郵件和垃圾郵件。
2.數據采集
本次建模數據來源於網絡,數據項統計如下:
數據詳情如下(部分展示):
正常郵件:
垃圾郵件:
每一行代表一封郵件。
3.數據預處理
3.1查看數據
print("總的數據量:", len(labels)) corpus, labels = remove_empty_docs(corpus, labels) # 移除空行 print('樣本之一:', corpus[10]) print('樣本的label:', labels[10]) label_name_map = ["垃圾郵件", "正常郵件"] print('實際類型:', label_name_map[int(labels[10])])結果如圖所示:
4.特征工程
4.1數據集拆分
把數據集分為70%訓練集和30%測試集。
4.2加載停用詞
停用詞列表如下,部分展示:
4.3分詞
import jieba tokens = jieba.lcut(text) tokens = [token.strip() for token in tokens]結果如圖所示:
訓練集分詞展示:
測試集分詞展示:
4.4移除特殊字符
pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # re.escape就能自動處理所有的特殊符號 # string.punctuation返回所有標點符號 filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens]) filtered_text = ' '.join(filtered_tokens)4.5去停用詞
4.6歸整化
結果如圖所示:
歸整化後的訓練集:
歸整化後的測試集:
4.7詞袋模型特征提取
# min_df:在構建詞匯表時,忽略那些文檔頻率嚴格低於給定阈值的術語。 # ngram_range的(1,1)表示僅使用單字符 vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range) features = vectorizer.fit_transform(corpus) # 學習詞匯表字典並返回文檔術語矩陣結果如圖所示:
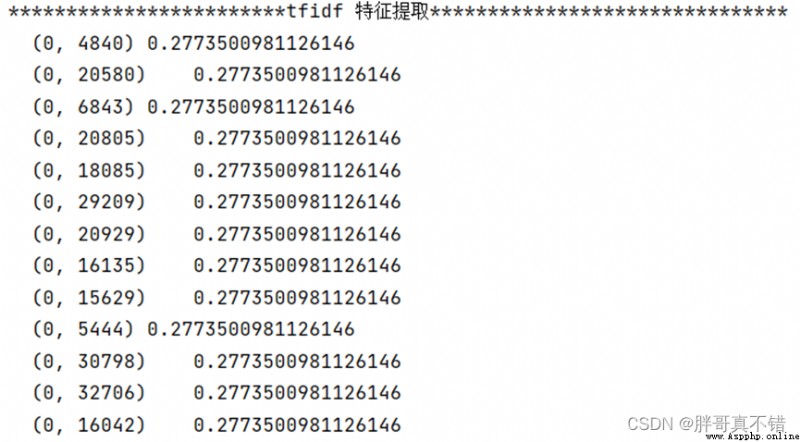
4.8 TFIDF特征提取
結果如圖所示:
5.構建支持向量機分類模型
5.1基於詞袋模型特征的支持向量機
5.2基於TFIDF特征的支持向量機
# 基於tfidf的支持向量機模型 print("基於tfidf的支持向量機模型") svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm, train_features=tfidf_train_features, train_labels=train_labels, test_features=tfidf_test_features, test_labels=test_labels)6.模型評估
6.1評估指標及結果
評估指標主要包括准確率、查准率、查全率(召回率)、F1分值等等。
通過上表可以看到,兩種特征提取的模型的准確率均為97%,F1分值均為0.97,說明模型效果良好。
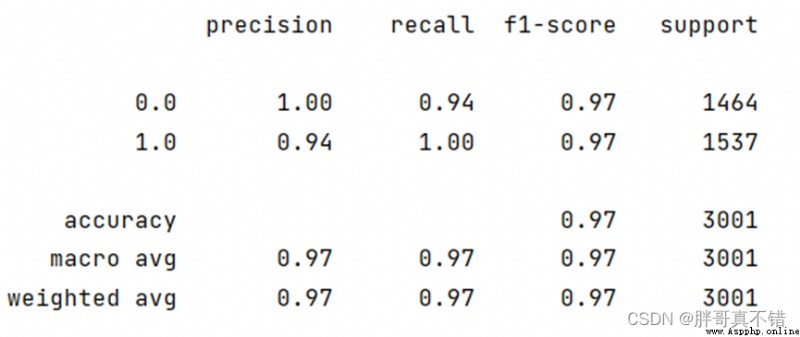
6.2分類報告
結果如圖所示:
基於詞袋模型特征的分類報告:
類型為垃圾郵件的F1分值為0.97;類型為正常郵件的F1分值為0.97。
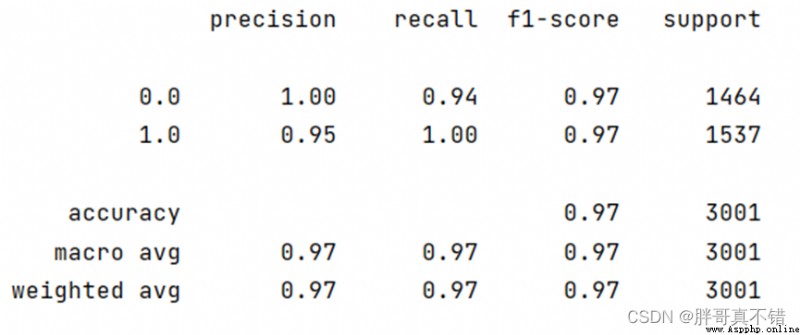
基於TFIDF特征的分類報告:
類型為垃圾郵件的F1分值為0.97;類型為正常郵件的F1分值為0.97。
6.3混淆矩陣
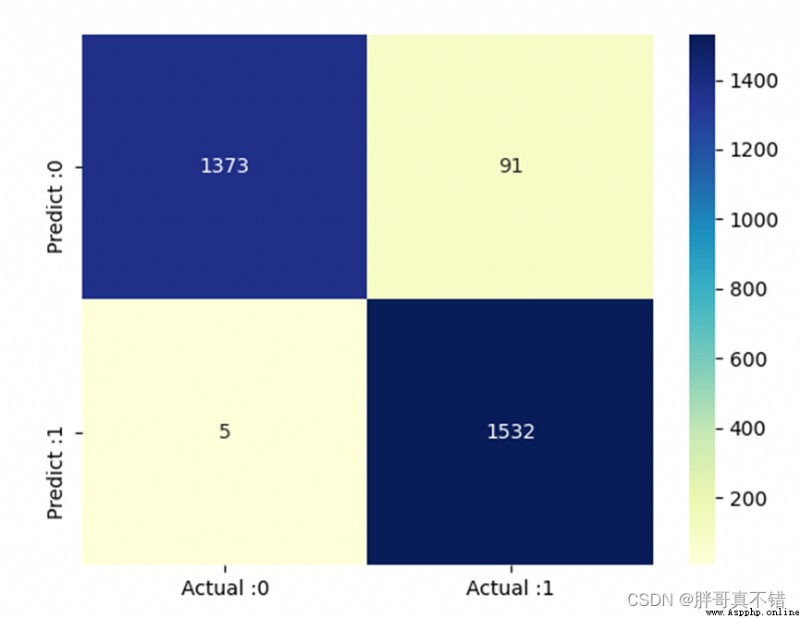
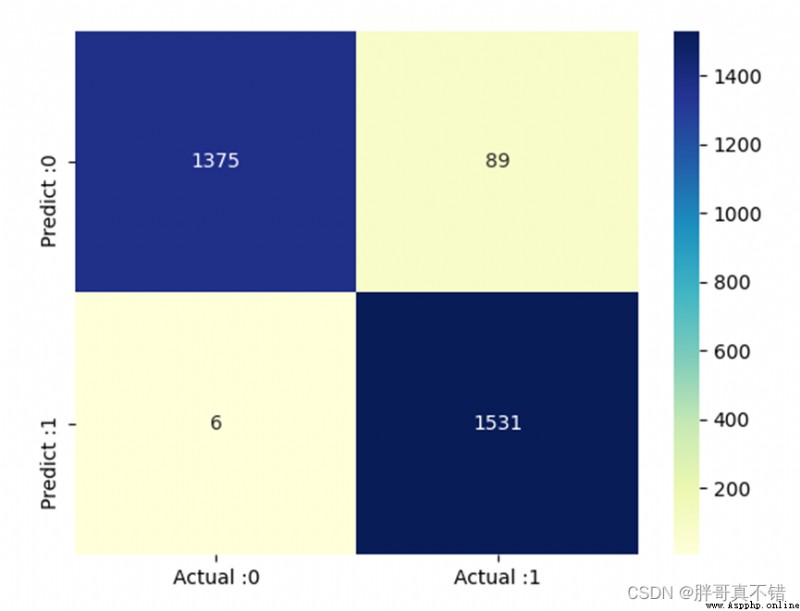
# 構建數據框 cm_matrix = pd.DataFrame(data=cm, columns=['Actual :0', 'Actual :1'], index=['Predict :0', 'Predict :1']) sns.heatmap(cm_matrix, annot=True, fmt='d', cmap='YlGnBu') # 熱力圖展示 plt.show() # 展示圖片結果如圖所示:
基於詞袋模型特征的分類報告:
從上圖可以看到,預測為垃圾郵件 實際為正常郵件的有91封;預測為正常郵件 實際為垃圾郵件的有5封。
基於TFIDF特征的分類報告:
從上圖可以看到,預測為垃圾郵件 實際為正常郵件的有89封;預測為正常郵件 實際為垃圾郵件的有6封。
7.模型預測展示
顯示正確分類的郵件:
顯示錯誤分類的郵件:
8.總結展望
本項目應用應用兩種特征提取方法進行支持向量機模型中文郵件分類研究,通過數據預處理、特征工程、模型構建、模型評估等工作,最終模型的F1分值達到0.97,這在文本分類領域,是非常棒的效果,可以應用於實際工作中。
本次機器學習項目實戰所需的資料,項目資源如下:
項目說明:
鏈接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取碼:bcbp網盤如果失效,可以添加博主微信:zy10178083