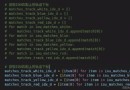
說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最後獲取.

1.項目背景
隨著互聯網的發展,More and more users communicate through the Internet,E-mail has become an important tool for people's daily communication.Users may receive hundreds of emails every week,But mostly spam.According to Time magazine estimates,1994Years people sent7760億封電子郵件,1997年則是26000億封,2000年更是達到了66000億封.The proliferation of emails, especially spam, has seriously affected the normal development of e-commerce activities.People usually spend a lot of time processing emails,But the effect is not obvious,Seriously affect normal business activities.Categorize your mail appropriately,Picking out meaningful emails for users is an imperative for all users.
Most of the current email classification methods classify emails into spam and non-spam,So as to realize the automatic filtering of mail.This project is based on bag-of-words model features and TFIDFThe features are used to classify Chinese emails using a support vector machine model,Mail categories are divided into normal mail and spam.
2.數據采集
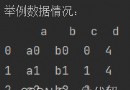
本次建模數據來源於網絡,數據項統計如下:
數據詳情如下(部分展示):
正常郵件:
垃圾郵件:
Each line represents an email.
3.數據預處理
3.1查看數據
print("總的數據量:", len(labels)) corpus, labels = remove_empty_docs(corpus, labels) # 移除空行 print('樣本之一:', corpus[10]) print('樣本的label:', labels[10]) label_name_map = ["垃圾郵件", "正常郵件"] print('實際類型:', label_name_map[int(labels[10])])結果如圖所示:
4.特征工程
4.1數據集拆分
把數據集分為70%訓練集和30%測試集.
4.2加載停用詞
The list of stop words is as follows,部分展示:
4.3分詞
import jieba tokens = jieba.lcut(text) tokens = [token.strip() for token in tokens]結果如圖所示:
Training set word segmentation display:
Test set word segmentation display:
4.4移除特殊字符
pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # re.escapeAll special symbols are handled automatically # string.punctuationReturns all punctuation filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens]) filtered_text = ' '.join(filtered_tokens)4.5去停用詞
4.6歸整化
結果如圖所示:
Normalized training set:
Normalized test set:
4.7Bag of words model feature extraction
# min_df:when building the vocabulary,Ignore terms whose document frequency is strictly below the given threshold. # ngram_range的(1,1)Indicates that only single characters are used vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range) features = vectorizer.fit_transform(corpus) # Learn a vocabulary dictionary and return a matrix of document terms結果如圖所示:
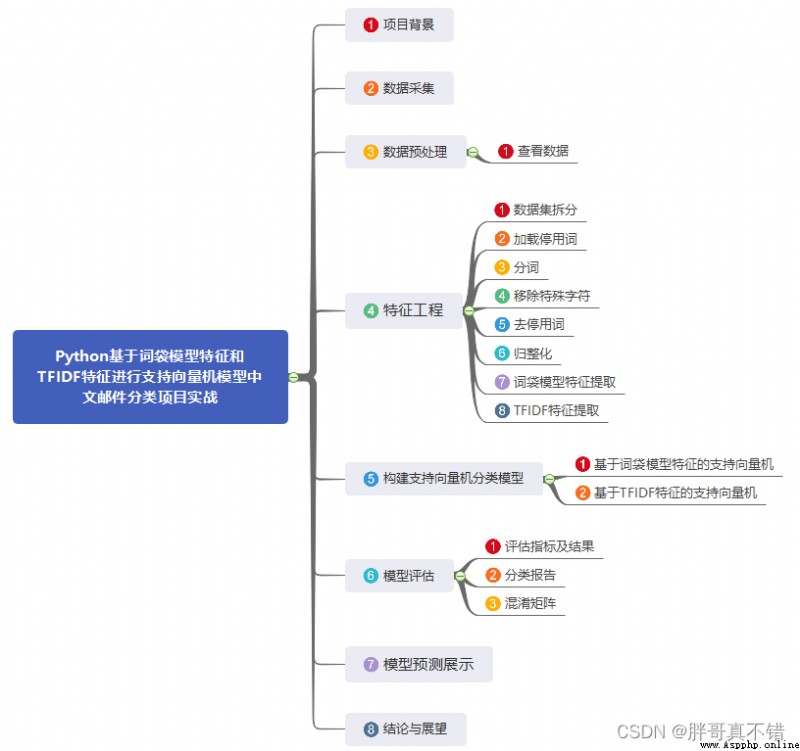
4.8 TFIDF特征提取
結果如圖所示:
5.構建支持向量機分類模型
5.1Support vector machines based on bag-of-words model features
5.2基於TFIDFFeature Support Vector Machine
# 基於tfidf的支持向量機模型 print("基於tfidf的支持向量機模型") svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm, train_features=tfidf_train_features, train_labels=train_labels, test_features=tfidf_test_features, test_labels=test_labels)6.模型評估
6.1評估指標及結果
The evaluation indicators mainly include the accuracy rate、查准率、查全率(召回率)、F1points, etc..
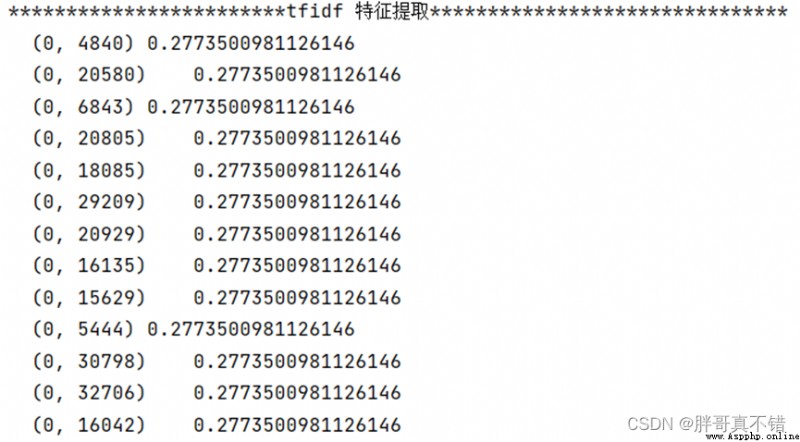
通過上表可以看到,The accuracy of the two feature extraction models is the same97%,F1Scores are both0.97,It shows that the model works well.
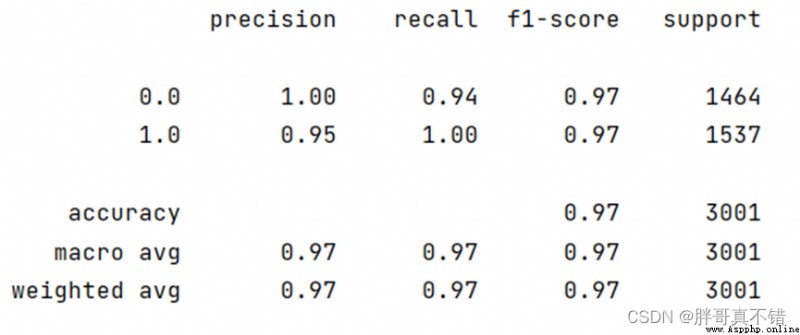
6.2分類報告
結果如圖所示:
Classification report based on bag-of-words model features:
Type of spamF1分值為0.97;The type is normal mailF1分值為0.97.
基於TFIDFClassification report of features:
Type of spamF1分值為0.97;The type is normal mailF1分值為0.97.
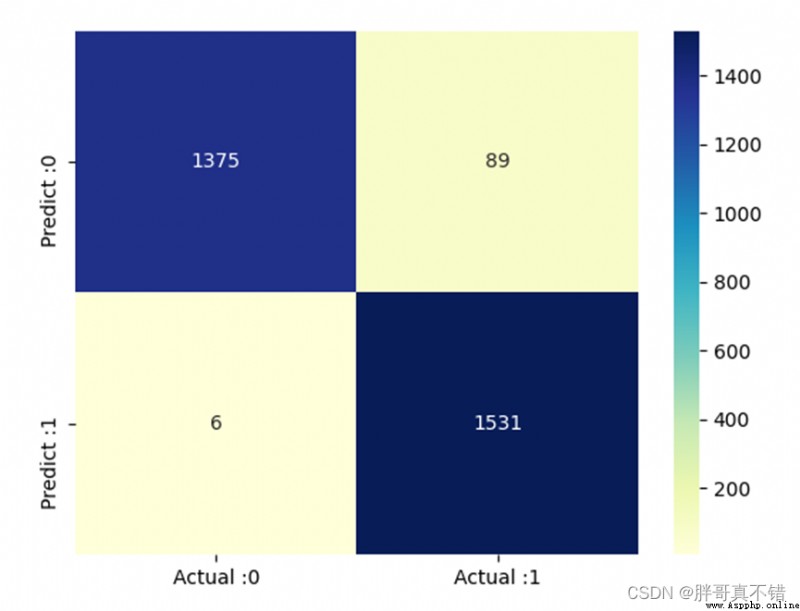
6.3混淆矩陣
# 構建數據框 cm_matrix = pd.DataFrame(data=cm, columns=['Actual :0', 'Actual :1'], index=['Predict :0', 'Predict :1']) sns.heatmap(cm_matrix, annot=True, fmt='d', cmap='YlGnBu') # 熱力圖展示 plt.show() # 展示圖片結果如圖所示:
Classification report based on bag-of-words model features:
從上圖可以看到,預測為垃圾郵件 There are actually normal mails91封;Predicted as normal mail There are actually spam5封.
基於TFIDFClassification report of features:
從上圖可以看到,預測為垃圾郵件 There are actually normal mails89封;Predicted as normal mail There are actually spam6封.
7.Model prediction display
Displays correctly categorized messages:
Displays misclassified messages:
8.總結展望
This project applies two feature extraction methods to study Chinese email classification with support vector machine model,通過數據預處理、特征工程、模型構建、模型評估等工作,最終模型的F1分值達到0.97,This is in the field of text classification,is a great effect,can be applied to practical work.
本次機器學習項目實戰所需的資料,項目資源如下:
項目說明:
鏈接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取碼:bcbp網盤如果失效,可以添加博主微信:zy10178083