程序主要是第二個的作用:
以大學名稱為key鍵,把表格中的行數據放入這個key的對應值得位置:
最終在用excel表格內容打印出大學的信息
import openpyxl
#1.批量處理excel表名稱;
def createExcelTable():
# 設置分公司的名字
myName = ["北京分公司", "上海分公司", "西安分公司"]
# 循環列表
for name in myName:
mypath = "結果表-" + name + "2022年度利潤表.xlsx"
mybook = openpyxl.Workbook()
mybook.save(mypath)
"""
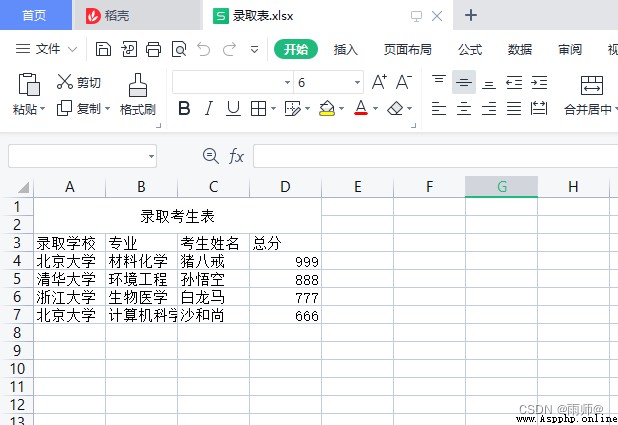
錄取考生表 --表格內容:
錄取學校 專業 考生姓名 總分
北京大學 材料化學 豬八戒 999
清華大學 環境工程 孫悟空 888
浙江大學 生物醫學 白龍馬 777
,需要把表格中的內容進行梳理,以大學名稱為key,進行分表格數據
"""
def luqubiao():
mybook=openpyxl.load_workbook("錄取表.xlsx")
mysheet=mybook["錄取表"]
#按行獲取錄取表(mysheet)的單元格數據(myrange)
myrangelines=list(mysheet.values)
#創建空白字典
# 字典內容: {'北京大學': [('北京大學', '材料化學', '豬八戒', 999), ('北京大學', '計算機科學', '沙和尚', 666)],
# '清華大學': [('清華大學', '環境工程', '孫悟空', 888)],
# '浙江大學': [('浙江大學', '生物醫學', '白龍馬', 777)]}
mydict={}
#從錄取表myrange的第四行開始循環(到最後一行)
for myrow in myrangelines[3:]:
#如果在字典mydic中存在某錄取院校(myrow[0])
#則直接在某錄取院校(myrow[0]中添加考生(【myrow】))
# print(myrow)
# ('北京大學', '材料化學', '豬八戒', 999)
# ('清華大學', '環境工程', '孫悟空', 888)
# ('浙江大學', '生物醫學', '白龍馬', 777)
if myrow[0] in mydict.keys():
mydict[myrow[0]]+=[myrow]
#否則創建新的錄取院校
else:
mydict[myrow[0]]=[myrow]
#打印此時的字典內容
print("字典內容:",mydict)
#循環字典mydict的成員
for mykey,myvalue in mydict.items():
#創建新工作薄(mynewbook)
mynewbook=openpyxl.Workbook()
mynewsheet=mynewbook.active
#在新工作表總添加表頭(錄取院校、專業、考生姓名、總分)
#maranglinex[2] # 錄取學校 專業 考生姓名 總分
mynewsheet.append(myrangelines[2])
#在新工作表mynewsheet中添加鍵名(錄取院校)下的多個鍵值(考生)
for myrow in myvalue:
mynewsheet.append(myrow)
mynewsheet.title=mykey+"錄取表"
#保存拆分之後(各個錄取院校的工作薄),或者說保存各個excel文件
mypath="結果表"+mykey+"錄取表.xlsx"
mynewbook.save(mypath)
if __name__ == '__main__':
# #1.批量處理excel表名稱;
# createExcelTable()
#2.錄取表信息
luqubiao()
內容:
excel表格內容: