[email protected]-019 MINGW64 /
$ ipython
Python 3.6.7 (default, Jul 2 2019, 02:21:41) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.8.0 -- An enhanced Interactive Python. Type '?' for help.
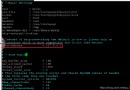
In [1]: import numpy as np
In [2]: import pandas as pd
# 示例數據(常規數據)
In [3]: data = ['peter', 'Paul', 'MARY', 'GuiDO']
# 數據值正常時的操作方法
In [4]: [s.capitalize() for s in data]
Out[4]: ['Peter', 'Paul', 'Mary', 'Guido']
# 實際上, 這才是我們經常碰到的常規數據, 對吧? :)
In [5]: data = ['peter', 'Paul', 'MARY', 'GuiDO', None]
# 這種處理方法就不太友好了
In [6]: [s.capitalize() for s in data]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-bb1b424b25b0> in <module>
----> 1 [s.capitalize() for s in data]
<ipython-input-6-bb1b424b25b0> in <listcomp>(.0)
----> 1 [s.capitalize() for s in data]
AttributeError: 'NoneType' object has no attribute 'capitalize'
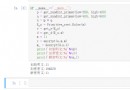
In [7]: names = pd.Series(data)
In [8]: names
Out[8]:
0 peter
1 Paul
2 MARY
3 GuiDO
4 None
dtype: object
# 這是正經的向量化字符串操作, 有沒有很6. 只需要關注操作的方法即可, 不用操心異常數值.
In [9]: names.str.capitalize()
Out[9]:
0 Peter
1 Paul
2 Mary
3 Guido
4 None
dtype: object
In [16]: monte.str.extract('([A-Za-z]+)')
Out[16]:
0
0 Graham
1 John
2 Terry
3 Eric
In [17]: monte.str.findall(r'^[^AEIOU].*[^aeiou]$')
Out[17]:
0 [Graham Chapman]
1 []
2 [Terry Gilliam]
3 []
dtype: object
In [18]: monte.str[:3]
Out[18]:
0 Gra
1 Joh
2 Ter
3 Eri
dtype: object
# 這兩種等效
In [19]: monte.str.slice(0, 3)
Out[19]:
0 Gra
1 Joh
2 Ter
3 Eri
dtype: object
In [20]: monte.str.get(3)
Out[20]:
0 h
1 n
2 r
3 c
dtype: object
# 這兩種操作方法等效
In [21]: monte.str[3]
Out[21]:
0 h
1 n
2 r
3 c
dtype: object
# 綜合運用
In [22]: monte.str.split().str.get(-1)
Out[22]:
0 Chapman
1 Cleese
2 Gilliam
3 idle
dtype: object