目錄
3.數據庫的查詢
3.1.基本查詢
1 基本查詢
2 過濾查詢
3.2.F和Q對象
3.3 .聚合函數和排序函數
1. 聚合函數
2. 排序
3.4.關聯查詢
關聯無過濾查詢
關聯過濾查詢
3.5查詢集QuerySet
1 概念
2 兩大特性
3 限制查詢集
4.分頁
查詢的的數據庫數據有:
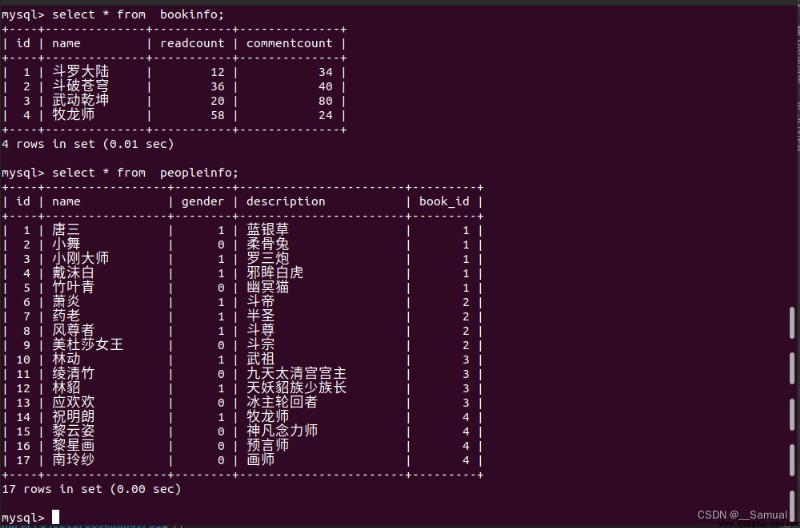
get查詢單一結果,如果不存在會拋出模型類.DoesNotExist異常。
all查詢多個結果。
count查詢結果數量。
示例:
# 打開shell,導入相關的模塊
>>> from book.models import BookInfo,PeopleInfo
# get方法的使用,通過id來查詢
>>> BookInfo.objects.get(id=1)
<BookInfo: 斗羅大陸>
# get方法的使用,通過主鍵來查詢
>>> BookInfo.objects.get(pk=4)
<BookInfo: 牧龍師>
# all方法的使用
>>> BookInfo.objects.all()
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 斗破蒼穹>, <BookInfo: 武動乾坤>, <BookInfo: 牧龍師>]>
# 當查詢的結果不存在時,會報錯,錯誤類型是:DoesNotExist
>>> BookInfo.objects.get(id=10)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/home/samual/.virtualenvs/py_django/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/home/samual/.virtualenvs/py_django/lib/python3.8/site-packages/django/db/models/query.py", line 415, in get
raise self.model.DoesNotExist(
book.models.BookInfo.DoesNotExist: BookInfo matching query does not exist.
# 使用count方法查詢結果數量
>>> BookInfo.objects.count()
4
實現SQL中的where功能,包括
對於過濾條件的使用,上述三個方法相同,故僅以filter進行講解。
過濾條件的表達語法如下:
屬性名稱__比較運算符=值
# 屬性名稱和比較運算符間使用兩個下劃線,所以屬性名不能包括多個下劃線1)相等
exact:表示判等。
示例:查詢編號為1的圖書。
>>> BookInfo.objects.filter(id__exact = 1)
<QuerySet [<BookInfo: 斗羅大陸>]>
# 可以簡寫為:(exact為等於,可以省略不寫)
>>> BookInfo.objects.filter(id = 1)
<QuerySet [<BookInfo: 斗羅大陸>]>
2)模糊查詢
contains:是否包含。
說明:如果要包含%無需轉義,直接寫即可。
示例:查詢書名包含'斗'的圖書。
>>> BookInfo.objects.filter(name__contains = '斗')
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 斗破蒼穹>]>
startswith、endswith:以指定值開頭或結尾。
示例:查詢書名以‘武’開頭的圖書,以‘師’結尾的圖書
>>> BookInfo.objects.filter(name__startswith = '武')
<QuerySet [<BookInfo: 武動乾坤>]>
>>> BookInfo.objects.filter(name__endswith = '師')
<QuerySet [<BookInfo: 牧龍師>]>
以上運算符都區分大小寫,在這些運算符前加上i表示不區分大小寫,如iexact、icontains、istartswith、iendswith.
3) 空查詢
isnull:是否為null。
示例:查詢書名為空的圖書
>>> BookInfo.objects.filter(name__isnull = True)
<QuerySet []>
4) 范圍查詢
in:是否包含在范圍內。
示例:查詢編號為1或3或5的圖書
>>> BookInfo.objects.filter(id__in = [1,3,5])
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 武動乾坤>]>
5)比較查詢
示例:查詢編號大於2的圖書
>>> BookInfo.objects.filter(id__gt = 2)
<QuerySet [<BookInfo: 武動乾坤>, <BookInfo: 牧龍師>]>
不等於的運算符,使用exclude()過濾器。
例:查詢編號不等於2的圖書
>>> BookInfo.objects.exclude(id__exact = 2)
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 武動乾坤>, <BookInfo: 牧龍師>]>
F對象:兩個屬性之間的比較使用F對象,F對象被定義在django.db.models中。
語法如下:
F('屬性名')示例:查詢閱讀量大於等於評論量的圖書。
# 使用前先導入
>>> from django.db.models import F
>>> BookInfo.objects.filter(readcount__gt = F('commentcount'))
<QuerySet [<BookInfo: 牧龍師>]>
可以在F對象上使用算數運算。
示例:查詢評論量大於2倍閱讀量的圖書。
>>> BookInfo.objects.filter(commentcount__gt = F('readcount') * 2)
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 武動乾坤>]>
Q對象:多個過濾器逐個調用表示邏輯與關系,同sql語句中where部分的and關鍵字,Q對象被義在django.db.models中。
語法如下:
Q(屬性名__運算符=值)示例:如果查詢閱讀量大於20,並且編號小於3的圖書。
>>> BookInfo.objects.filter(readcount__gt = 20, id__exact = 2)
<QuerySet [<BookInfo: 斗破蒼穹>]>
或者
>>> BookInfo.objects.filter(readcount__gt = 20).filter( id__exact = 2)
<QuerySet [<BookInfo: 斗破蒼穹>]>
但如果需要實現邏輯或or的查詢,需要使用Q()對象結合 | 運算符
例:查詢閱讀量大於20的圖書,改寫為Q對象如下。
BookInfo.objects.filter(Q(readcount__gt=20))Q對象可以使用&、|連接,&表示邏輯與,|表示邏輯或。
例:查詢閱讀量大於30,或編號小於3的圖書,只能使用Q對象實現
>>> BookInfo.objects.filter(Q(readcount__gt=30)|Q(id__lt=3))
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 斗破蒼穹>, <BookInfo: 牧龍師>]>
Q對象前可以使用~操作符,表示非not。
例:查詢編號不等於3的圖書。
>>> BookInfo.objects.filter(~Q(id = 3))
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 斗破蒼穹>, <BookInfo: 牧龍師>]>
使用aggregate()過濾器調用聚合函數。聚合函數包括:Avg平均,Count數量,Max最大,Min最小,Sum求和,被定義在django.db.models中。
示例:查詢圖書的總閱讀量。
>>> from django.db.models import Sum
>>> BookInfo.objects.aggregate(Sum('readcount'))
{'readcount__sum': 126}
注意:aggregate的返回值是一個字典類型,格式如下:
{'屬性名__聚合類小寫':值}
如:{'readcount__sum': 126}使用count時一般不使用aggregate()過濾器。
示例:查詢圖書總數。
BookInfo.objects.count()
注意count函數的返回值是一個數字。
使用order_by對結果進行排序
# 默認升序
>>> BookInfo.objects.all().order_by('readcount')
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 武動乾坤>, <BookInfo: 斗破蒼穹>, <BookInfo: 牧龍師>]>
# 降序
>>> BookInfo.objects.all().order_by('-readcount')
<QuerySet [<BookInfo: 牧龍師>, <BookInfo: 斗破蒼穹>, <BookInfo: 武動乾坤>, <BookInfo: 斗羅大陸>]>
關聯查詢相當於MySQL中的多表查詢 。
由一到多的訪問語法:
一對應的模型類對象.多對應的模型類名小寫_set
示例:查詢書籍id為1的所有人物:
>>> book = BookInfo.objects.get(id=1)
>>> book.peopleinfo_set.all()
<QuerySet [<PeopleInfo: 唐三>, <PeopleInfo: 小舞>, <PeopleInfo: 小剛大師>, <PeopleInfo: 戴沫白>, <PeopleInfo: 竹葉青>]>
由多到一的訪問語法:
多對應的模型類對象.多對應的模型類中的關系類屬性名
示例:查詢人物id為9所對應的書籍名
>>> person = PeopleInfo.objects.get(id=9)
>>> person.book
<BookInfo: 斗破蒼穹>
訪問一對應的模型類關聯對象的id語法:
多對應的模型類對象.關聯類屬性_id
示例:查看人物id為1對應的書籍id
>>> person = PeopleInfo.objects.get(id=1)
>>> person.book_id
1
由多模型類條件查詢一模型類數據:
語法如下:
關聯模型類名(小寫)__屬性名__條件運算符=值
注意:如果沒有"__運算符"部分,表示等於。
示例:查詢圖書,要求圖書人物為"小舞"
>>> book = BookInfo.objects.filter(peopleinfo__name='小舞')
>>> book
<QuerySet [<BookInfo: 斗羅大陸>]>
示例:查詢圖書,要求圖書中人物的描述包含"斗"
>>> book = BookInfo.objects.filter(peopleinfo__description__contains='斗')
>>> book
<QuerySet [<BookInfo: 斗破蒼穹>, <BookInfo: 斗破蒼穹>, <BookInfo: 斗破蒼穹>]>
由一模型類條件查詢多模型類數據:
語法如下:
一模型類關聯屬性名__一模型類屬性名__條件運算符=值
注意:如果沒有"__運算符"部分,表示等於。
例:查詢書名為“牧龍師”的所有人物。
>>> people = PeopleInfo.objects.filter(book__name = '牧龍師')
>>> people
<QuerySet [<PeopleInfo: 祝明朗>, <PeopleInfo: 黎雲姿>, <PeopleInfo: 黎星畫>, <PeopleInfo: 南玲紗>]>
示例:查詢圖書閱讀量大於50的所有人物
>>> people = PeopleInfo.objects.filter(book__readcount__gt = 50)
>>> people
<QuerySet [<PeopleInfo: 祝明朗>, <PeopleInfo: 黎雲姿>, <PeopleInfo: 黎星畫>, <PeopleInfo: 南玲紗>]>
Django的ORM中存在查詢集的概念。
查詢集,也稱查詢結果集、QuerySet,表示從數據庫中獲取的對象集合。
當調用如下過濾器方法時,Django會返回查詢集(而不是簡單的列表):
對查詢集可以再次調用過濾器進行過濾,如
>>> books = BookInfo.objects.filter(readcount__gt=30).order_by('id')
>>> books
<QuerySet [<BookInfo: 斗破蒼穹>, <BookInfo: 牧龍師>]>
也就意味著查詢集可以含有零個、一個或多個過濾器。過濾器基於所給的參數限制查詢的結果。
從SQL的角度講,查詢集與select語句等價,過濾器像where、limit、order by子句。
判斷某一個查詢集中是否有數據:
1)惰性執行
創建查詢集不會訪問數據庫,直到調用數據時,才會訪問數據庫,調用數據的情況包括迭代、序列化、與if合用
例如,當執行如下語句時,並未進行數據庫查詢,只是創建了一個查詢集books
books = BookInfo.objects.all()繼續執行遍歷迭代操作後,才真正的進行了數據庫的查詢
for book in books:
print(book.name)2)緩存
使用同一個查詢集,第一次使用時會發生數據庫的查詢,然後Django會把結果緩存下來,再次使用這個查詢集時會使用緩存的數據,減少了數據庫的查詢次數。
可以對查詢集進行取下標或切片操作,等同於sql中的limit和offset子句。
注意:不支持負數索引。
對查詢集進行切片後返回一個新的查詢集,不會立即執行查詢。
如果獲取一個對象,直接使用[0],等同於[0:1].get(),但是如果沒有數據,[0]引發IndexError異常,[0:1].get()如果沒有數據引發DoesNotExist異常。
示例:獲取第1、2項,運行查看
>>> books = BookInfo.objects.all()[0:2]
>>> books
<QuerySet [<BookInfo: 斗羅大陸>, <BookInfo: 斗破蒼穹>]>
具體內容請查看django官方文檔:https://docs.djangoproject.com/en/1.11/topics/pagination/
#查詢數據
books = BookInfo.objects.all()
#導入分頁類
from django.core.paginator import Paginator
#創建分頁實例
paginator=Paginator(books,2)
#獲取指定頁碼的數據
page_skus = paginator.page(1)
#獲取分頁數據
total_page=paginator.num_pages