???作者介紹:Python領域優質創作者、華為雲享專家、阿裡雲專家博主、2021年CSDN博客新星Top6
???本文已收錄於Python全棧系列專欄:《100天精通Python從入門到就業》
???此專欄文章是專門針對Python零基礎小白所准備的一套完整教學,從0到100的不斷進階深入的學習,各知識點環環相扣
???訂閱專欄後續可以閱讀Python從入門到就業100篇文章;還可私聊進兩百人Python全棧交流群(手把手教學,問題解答); 進群可領取80GPython全棧教程視頻 + 300本計算機書籍:基礎、Web、爬蟲、數據分析、可視化、機器學習、深度學習、人工智能、算法、面試題等。
???加入我一起學習進步,一個人可以走的很快,一群人才能走的更遠!
正則表達式是一個強大的字符串處理工具,幾乎所有的字符串操作都可以通過正則表達式來完成,其本質是一個特殊的字符序列,可以方便的檢查一個字符串是否與我們定義的字符序列的某種模式相匹配。
在Python中經常會用在:爬蟲爬取數據時、數據開發、文本檢索和數據篩選的時候常用正則來檢索字符串等等,正則表達式已經內嵌在Python中,通過import re模塊就可以使用。作為剛學Python的新手大多數都聽說“正則”這個術語,本文將詳細講解從正則表達式的基礎到Python中正則表達式所有語法,保證所有小白從入門到精通!!!
由於正則表達式通常都包含反斜槓,所以你最好使用原始字符串來表示它們。模式元素(如 r' ',等價於 \t )匹配相應的特殊字符。
下表列出了正則表達式模式語法中的特殊元素。如果你使用模式的同時提供了可選的標志參數,某些模式元素的含義會改變。
模式
描述
^
匹配字符串的開頭
$
匹配字符串的末尾。
.
匹配除 “ ” 之外的任何單個字符。要匹配包括 ‘ ’ 在內的任何字符,請使用象 ‘[. ]’ 的模式。
[...]
用來表示一組字符,單獨列出:[amk] 匹配 ‘a’,‘m’或’k’
[^...]
不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
re*
匹配0個或多個的表達式。
re+
匹配1個或多個的表達式。
re?
匹配0個或1個由前面的正則表達式定義的片段,非貪婪方式
re{n}
匹配n個前面表達式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的兩個o。
re{ n,}
精確匹配n個前面表達式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等價於"o+”。"o{0,}“則等價於"o*”。
re{ n, m}
匹配 n 到 m 次由前面的正則表達式定義的片段,貪婪方式
`a
b`
(re)
匹配括號內的表達式,也表示一個組
(?imx)
正則表達式包含三種可選標志:i, m, 或 x 。只影響括號中的區域。
(?-imx)
正則表達式關閉 i, m, 或 x 可選標志。只影響括號中的區域。
(?: re)
類似 (…), 但是不表示一個組
(?imx: re)
在括號中使用i, m, 或 x 可選標志
(?-imx: re)
在括號中不使用i, m, 或 x 可選標志
(?#...)
注釋.
(?= re)
前向肯定界定符。如果所含正則表達式,以 … 表示,在當前位置成功匹配時成功,否則失敗。但一旦所含表達式已經嘗試,匹配引擎根本沒有提高;模式的剩余部分還要嘗試界定符的右邊。
(?! re)
前向否定界定符。與肯定界定符相反;當所含表達式不能在字符串當前位置匹配時成功。
(?> re)
匹配的獨立模式,省去回溯。
w
匹配包括下劃線的任何單詞字符。等價於’[A-Za-z0-9_]'。
W
匹配任何非單詞字符。等價於 ‘[^A-Za-z0-9_]’。
s
匹配任何空白字符,包括空格、制表符、換頁符等等。等價於 [ ]。
S
匹配任何非空白字符。等價於 [^ ]。
d
匹配任意數字,等價於 [0-9]。
D
匹配一個非數字字符。等價於 [^0-9]。
A
匹配字符串開始
Z
匹配字符串結束,如果是存在換行,只匹配到換行前的結束字符串。
z
匹配字符串結束
G
匹配最後匹配完成的位置。
匹配一個單詞邊界,也就是指單詞和空格間的位置。例如, ‘er’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。
B
匹配非單詞邊界。‘erB’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。
, , 等。
匹配一個換行符。匹配一個制表符, 等
...9
匹配第n個分組的內容。
匹配第n個分組的內容,如果它經匹配。否則指的是八進制字符碼的表達式。
PS:上表中re代表自己寫的某一個具體匹配模式
正則表達式可以包含一些可選標志修飾符來控制匹配的模式。修飾符被指定為一個可選的標志。多個標志可以通過按位 OR(|) 它們來指定。如 re.I | re.M 被設置成 I 和 M 標志:
修飾符
描述
re.I
使匹配對大小寫不敏感
re.L
做本地化識別(locale-aware)匹配
re.M
多行匹配,影響 ^ 和 $
re.S
使 . 匹配包括換行在內的所有字符
re.U
根據Unicode字符集解析字符。這個標志影響 w, W, , B.
re.X
該標志通過給予你更靈活的格式以便你將正則表達式寫得更易於理解。
正則表達式從左到右進行計算,並遵循優先級順序,這與算術表達式非常類似。
相同優先級的從左到右進行運算,不同優先級的運算先高後低。下表從最高到最低說明了各種正則表達式運算符的優先級順序:
運算符
描述
轉義符
(), (?:), (?=), []
圓括號和方括號
*, +, ?, {n}, {n,}, {n,m}
限定符
^, $, 任何元字符、任何字符
定位點和序列(即:位置和順序)
`
`
實例
描述
[Pp]ython
匹配 “Python” 或 “python”
rub[ye]
匹配 “ruby” 或 “rube”
[aeiou]
匹配中括號內的任意一個字母
[0-9]
匹配任何數字。類似於 [0123456789]
[a-z]
匹配任何小寫字母
[A-Z]
匹配任何大寫字母
[a-zA-Z0-9]
匹配任何字母及數字
[^aeiou]
除了aeiou字母以外的所有字符
[^0-9]
匹配除了數字外的字符
在Python中需要通過正則表達式對字符串進行匹配的時候,可以使用一個模塊,名字為re
1. re模塊的使用過程
# 導入re模塊
import re
# 使用match方法進行匹配操作
result = re.match(正則表達式,要匹配的字符串)
# 如果上一步匹配到數據的話,可以使用group方法來提取數據
result.group()
2. 示例(匹配以itcast開頭的語句)
>>> import re
>>> result = re.match("itcast","itcast.cn")
>>> result.group()
'itcast'
3. re.match(pattern, string, flags=0)
re.match 嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回none。
參數說明:
pattern: 匹配的正則表達式string: 要匹配的字符串。flags: 標志位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。在上一小節中,了解到通過re模塊能夠完成使用正則表達式來匹配字符串
本小節,將要講解正則表達式的單字符匹配
字符
功能
.
匹配任意1個字符(除了 )
[ ]
匹配[ ]中列舉的字符
d
匹配數字,即0-9
D
匹配非數字,即不是數字
s
匹配空白,即 空格,tab鍵
S
匹配非空白
w
匹配單詞字符,即a-z、A-Z、0-9、_
W
匹配非單詞字符
示例1:.的用法
>>> import re
>>> ret = re.match(".","M")
>>> print(ret.group())
M
>>> ret = re.match("t.o","too")
>>> print(ret.group())
too
>>> ret = re.match("t.o","two")
>>> print(ret.group())
two
示例2:[ ]的用法
>>> import re
>>> # 如果hello的首字符小寫,那麼正則表達式需要小寫的h
>>> ret = re.match("h","hello Python")
>>> print(ret.group())
h
>>> # 如果hello的首字符大寫,那麼正則表達式需要大寫的H
>>> ret = re.match("H","Hello Python")
>>> print(ret.group())
H
>>> # 大小寫h都可以的情況
>>> ret = re.match("[hH]","hello Python")
>>> print(ret.group())
h
>>> ret = re.match("[hH]","Hello Python")
>>> print(ret.group())
H
>>> ret = re.match("[hH]ello Python","Hello Python")
>>> print(ret.group())
Hello Python
>>> # 匹配0到9第一種寫法
>>> ret = re.match("[0123456789]Hello Python","7Hello Python")
>>> print(ret.group())
7Hello Python
>>> # 匹配0到9第二種寫法
>>> ret = re.match("[0-9]Hello Python","7Hello Python")
>>> print(ret.group())
7Hello Python
>>> ret = re.match("[0-35-9]Hello Python","7Hello Python")
>>> print(ret.group())
7Hello Python
>>> # 下面這個正則不能夠匹配到數字4,因此ret為None
>>> ret = re.match("[0-35-9]Hello Python","4Hello Python")
>>> print(ret.group())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
示例3:d用法
>>> import re
>>> # 普通的匹配方式
>>> ret = re.match("嫦娥1號","嫦娥1號發射成功")
>>> print(ret.group())
嫦娥1號
>>> ret = re.match("嫦娥2號","嫦娥2號發射成功")
>>> print(ret.group())
嫦娥2號
>>> ret = re.match("嫦娥3號","嫦娥3號發射成功")
>>> print(ret.group())
嫦娥3號
>>> # 使用d進行匹配
>>> ret = re.match("嫦娥d號","嫦娥1號發射成功")
>>> print(ret.group())
嫦娥1號
>>> ret = re.match("嫦娥d號","嫦娥2號發射成功")
>>> print(ret.group())
嫦娥2號
>>> ret = re.match("嫦娥d號","嫦娥3號發射成功")
>>> print(ret.group())
嫦娥3號
其他的匹配符參見後面章節的講解
匹配多個字符的相關格式
字符
功能
*
匹配前一個字符出現0次或者無限次,即可有可無
+
匹配前一個字符出現1次或者無限次,即至少有1次
?
匹配前一個字符出現1次或者0次,即要麼有1次,要麼沒有
{m}
匹配前一個字符出現m次
{m,n}
匹配前一個字符出現從m到n次
示例1:*用法
需求:匹配出,一個字符串第一個字母為大小字符,後面都是小寫字母並且這些小寫字母可有可無
>>> import re
>>> ret = re.match("[A-Z][a-z]*","M")
>>> print(ret.group())
M
>>> ret = re.match("[A-Z][a-z]*","MnnM")
>>> print(ret.group())
Mnn
>>> ret = re.match("[A-Z][a-z]*","Aabcdef")
>>> print(ret.group())
Aabcdef
示例2:+用法
需求:匹配出,變量名是否有效
import re
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[w]*",name)
if ret:
print("變量名 %s 符合要求" % ret.group())
else:
print("變量名 %s 非法" % name)
輸出結果:
變量名 name1 符合要求
變量名 _name 符合要求
變量名 2_name 非法
變量名 __name__ 符合要求
示例3:?用法
需求:匹配出,0到99之間的數字
>>> import re
>>> ret = re.match("[1-9]?[0-9]","7")
>>> print(ret.group())
7
>>> ret = re.match("[1-9]?d","33")
>>> print(ret.group())
33
>>> ret = re.match("[1-9]?d","09")
>>> print(ret.group())
0 # 這個結果並不是想要的,利用$才能解決
示例4:{m}用法
需求:匹配出,8到20位的密碼,可以是大小寫英文字母、數字、下劃線
>>> import re
>>> ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
>>> print(ret.group())
12a3g4
>>> ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
>>> print(ret.group())
1ad12f23s34455ff66
字符
功能
^
匹配字符串開頭
$
匹配字符串結尾
示例1: ^用法
需要:匹配以135開頭的電話號碼
>>> import re
>>> ret = re.match("^135[0-9]{8}","13588888888")
>>> print(ret.group())
13588888888
>>> ret = re.match("^135[0-9]{8}","13512345678")
>>> print(ret.group())
13512345678
# 136開頭的沒法匹配就會報錯
>>> ret = re.match("^135[0-9]{8}","13688888888")
>>> print(ret.group())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
示例2:$
需求:匹配出163的郵箱地址,且@符號之前有4到20位,例如[email protected]
import re
email_list = ["[email protected]", "[email protected]", "[email protected]"]
for email in email_list:
ret = re.match("[w]{4,20}@163.com$", email)
if ret:
print("%s 是符合規定的郵件地址,匹配後的結果是:%s" % (email, ret.group()))
else:
print("%s 不符合要求" % email)
輸出結果:
[email protected] 是符合規定的郵件地址,匹配後的結果是:[email protected]
[email protected] 不符合要求
.com.xiaowang[email protected] 不符合要求
字符
功能
`
`
(ab)
將括號中字符作為一個分組
um
引用分組num匹配到的字符串
(?P<name>)
分組起別名
(?P=name)
引用別名為name分組匹配到的字符串
示例1:|用法
需求:匹配出0-100之間的數字
>>> import re
>>> ret = re.match("[1-9]?d","8")
>>> print(ret.group())
8
>>> ret = re.match("[1-9]?d","78")
>>> print(ret.group())
78
>>> # 不正確的情況
>>> ret = re.match("[1-9]?d","08")
>>> print(ret.group())
0
>>> # 修正之後的
>>> ret = re.match("[1-9]?d$","08")
>>> if ret:
... print(ret.group())
... else:
... print("不在0-100之間")
...
不在0-100之間
>>> # 添加|
>>> ret = re.match("[1-9]?d$|100","8")
>>> print(ret.group()) # 8
8
>>> ret = re.match("[1-9]?d$|100","78")
>>> print(ret.group()) # 78
78
>>> ret = re.match("[1-9]?d$|100","08")
>>> # print(ret.group()) # 不是0-100之間
>>> ret = re.match("[1-9]?d$|100","100")
>>> print(ret.group()) # 100
100
示例2:()用法
需求:匹配出163、126、qq郵箱
>>> import re
>>> ret = re.match("w{4,20}@163.com", "[email protected]")
>>> print(ret.group())
[email protected]
>>> ret = re.match("w{4,20}@(163|126|qq).com", "[email protected]")
>>> print(ret.group())
[email protected]
>>> ret = re.match("w{4,20}@(163|126|qq).com", "[email protected]")
>>> print(ret.group())
[email protected]
>>> ret = re.match("w{4,20}@(163|126|qq).com", "[email protected]")
>>> if ret:
... print(ret.group())
... else:
... print("不是163、126、qq郵箱")
...
不是163、126、qq郵箱
需求:不是以4、7結尾的手機號碼(11位)
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1d{9}[0-35-68-9]", tel)
if ret:
print(ret.group())
else:
print("%s 不是想要的手機號" % tel)
輸出結果:
18912344321
10086 不是想要的手機號
18800007777 不是想要的手機號
需求:提取區號和電話號碼
>>> import re
>>> ret = re.match("([^-]*)-(d+)","010-12345678")
>>> print(ret.group())
010-12345678
>>> print(ret.group(1))
010
>>> print(ret.group(2))
12345678
示例3:用法
需求:匹配出<html>hh</html>
>>> import re
>>> # 能夠完成對正確的字符串的匹配
>>> ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</html>")
>>> print(ret.group())
<html>hh</html>
>>> # 如果遇到非正常的html格式字符串,匹配出錯
>>> ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
>>> print(ret.group())
<html>hh</htmlbalabala>
# 正確的理解思路:如果在第一對<>中是什麼,按理說在後面的那對<>中就應該是什麼
# 通過引用分組中匹配到的數據即可,但是要注意是元字符串,即類似 r""這種格式
>>> ret = re.match(r"<([a-zA-Z]*)>w*</>", "<html>hh</html>")
>>> print(ret.group())
<html>hh</html>
# 因為2對<>中的數據不一致,所以沒有匹配出來
>>> test_label = "<html>hh</htmlbalabala>"
>>> ret = re.match(r"<([a-zA-Z]*)>w*</>", test_label)
>>> if ret:
... print(ret.group())
... else:
... print("%s 這是一對不正確的標簽" % test_label)
...
<html>hh</htmlbalabala> 這是一對不正確的標簽
示例4:umber用法
需求:匹配出<html><h1>www.itcast.cn</h1></html>
import re
labels = ["<html><h1>www.itcast.cn</h1></html>", "<html><h1>www.itcast.cn</h2></html>"]
for label in labels:
ret = re.match(r"<(w*)><(w*)>.*</></>", label)
if ret:
print("%s 是符合要求的標簽" % ret.group())
else:
print("%s 不符合要求" % label)
輸出結果:
<html><h1>www.itcast.cn</h1></html> 是符合要求的標簽
<html><h1>www.itcast.cn</h2></html> 不符合要求
示例5:(?P<name>) (?P=name)用法
需求:匹配出<html><h1>www.itcast.cn</h1></html>
>>> import re
>>> ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
>>> print(ret.group())
<html><h1>www.itcast.cn</h1></html>
>>> ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")
>>> print(ret.group())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
注意:(?P<name>)和(?P=name)中的字母p大寫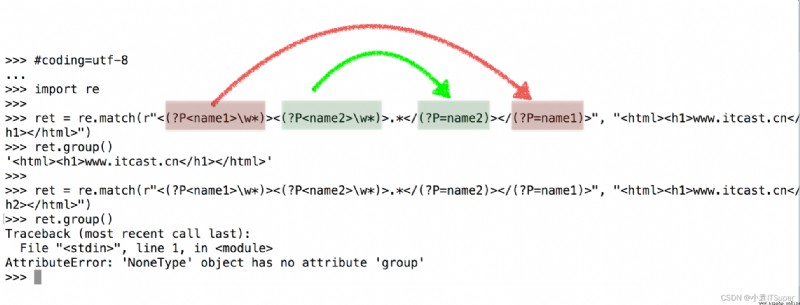
re.search 掃描整個字符串並返回第一個成功的匹配;匹配成功re.search方法返回一個匹配的對象,否則返回None。
函數語法:re.search(pattern, string, flags=0)
參數說明:
pattern: 匹配的正則表達式string: 要匹配的字符串。flags: 標志位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。案例:
import re
line = "Cats are smarter than dogs"
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")
輸出結果:
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarter
re.match與re.search的區別
re.match 只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回 None,而 re.search 匹配整個字符串,直到找到一個匹配。
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
輸出結果:
No match!!
search --> matchObj.group() : dogs
在字符串中找到正則表達式所匹配的所有子串,並返回一個列表,如果有多個匹配模式,則返回元組列表,如果沒有找到匹配的,則返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
函數語法:re.findall(pattern, string, flags=0)
參數說明:
pattern: 匹配的正則表達式string: 要匹配的字符串。flags: 標志位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。案例:統計出python、c、c++相應文章閱讀的次數
>>> import re
>>> ret = re.findall(r"d+", "python = 9999, c = 7890, c++ = 12345")
>>> print(ret)
['9999', '7890', '12345']
案例:多個匹配模式,返回元組列表
>>> import re
>>> result = re.findall(r'(w+)=(d+)', 'set width=20 and height=10')
>>> print(result)
[('width', '20'), ('height', '10')]
將匹配到的數據進行替換
函數語法:re.sub(pattern, repl, string, count=0, flags=0)
參數說明(前三個為必選參數,後兩個為可選參數。):
pattern : 正則中的模式字符串。repl : 替換的字符串,也可為一個函數。string : 要被查找替換的原始字符串。count : 模式匹配後替換的最大次數,默認 0 表示替換所有的匹配。flags : 編譯時用的匹配模式,數字形式。案例:
>>> import re
>>>
>>> phone = "2004-959-559 # 這是一個電話號碼"
>>>
>>> # 刪除注釋
>>> num = re.sub(r'#.*$', "", phone)
>>> print ("電話號碼 : ", num)
電話號碼 : 2004-959-559
>>>
>>> # 移除非數字的內容
>>> num = re.sub(r'D', "", phone)
>>> print ("電話號碼 : ", num)
電話號碼 : 2004959559
repl 參數是一個函數
案例:將字符串中的匹配的數字乘於 2
import re
# 將匹配的數字乘於 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>d+)', double, s))
輸出結果:
A46G8HFD1134
根據匹配進行切割字符串,並返回一個列表
函數語法:re.split(pattern, string[, maxsplit=0, flags=0])
參數說明:
pattern: 匹配的正則表達式string: 要匹配的字符串。maxsplit:分割次數,maxsplit=1 分割一次,默認為 0,不限制次數。flags: 標志位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。案例:以:或者空格切割字符串“info:xiaoZhang 33 shandong”
>>> import re
>>> ret = re.split(r":| ","info:xiaoZhang 33 shandong")
>>> print(ret)
['info', 'xiaoZhang', '33', 'shandong']
案例:對於一個找不到匹配的字符串而言,split 不會對其作出分割
>>> import re
>>> re.split('a', 'hello world')
['hello world']
()表示捕獲分組,()會把每個分組裡的匹配的值保存起來,從左向右,以分組的左括號為標志,第一個出現的分組的組號為1,第二個為2,以此類推。而(?:)表示非捕獲分組,和捕獲分組唯一的區別在於,非捕獲分組匹配的值不會保存起來。
>>> import re
>>> a = "123abc456"
# 捕獲所有分組
>>> ret = re.search("([0-9]*)([a-z]*)([0-9]*)",a)
>>> print(ret.group(1))
123
>>> print(ret.group(2))
abc
>>> print(ret.group(3))
456
# 僅捕獲後兩個分組
>>> ret = re.search("(?:[0-9]*)([a-z]*)([0-9]*)",a)
>>> print(ret.group(1))
abc
>>> print(ret.group(2))
456
>>> print(ret.group(3)) # 因為第一個括號中的分組並未捕獲所有只有兩個分組數據
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
說明:(?:pattern)匹配 pattern 但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行存儲供以後使用。
正向肯定預查(look ahead positive assert),匹配pattern前面的位置。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。
>>> import re
>>> ret = re.search("Windows(?=95|98|NT|2000)","Windows2000")
>>> print(ret.group())
Windows
>>> ret = re.search("Windows(?=95|98|NT|2000)","Windows3.1")
>>> print(ret.group())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
說明:"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的 Windows,但不能匹配"Windows3.1"中的 Windows。預查不消耗字符,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字符之後開始。
(?:pattern)和(?=pattern)的區別:
(:pattern) 匹配得到的結果包含pattern,(=pattern) 則不包含。如:
>>> import re
# (?:pattern)
>>> ret = re.search("industr(?:y|ies)","industry abc")
>>> print(ret.group())
industry
# (?=pattern)
>>> ret = re.search("industr(?=y|ies)","industry abc")
>>> print(ret.group())
industr
(:pattern) 消耗字符,下一字符匹配會從已匹配後的位置開始。(=pattern) 不消耗字符,下一字符匹配會從預查之前的位置開始,如: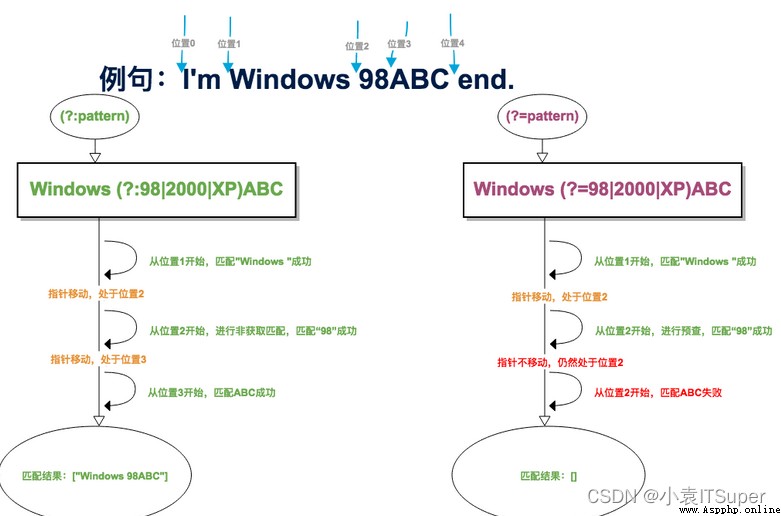
正向否定預查(negative assert),在任何不匹配pattern的字符串開始處匹配查找字符串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。
>>> import re
>>> ret = re.search("Windows(?!95|98|NT|2000)","Windows2000")
>>> print(ret.group())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> ret = re.search("Windows(?!95|98|NT|2000)","Windows3.1")
>>> print(ret.group())
Windows
說明:"Windows(?=95|98|NT|2000)"不能匹配"Windows2000"中的 Windows,但能匹配"Windows3.1"中的 Windows。預查不消耗字符,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字符之後開始。與(=pattern)相反
正則表達式模式中使用到通配字,那它在從左到右的順序求值時,會盡量“抓取”滿足匹配最長字符串。Python裡數量詞默認是貪婪的(在少數語言裡也可能是默認非貪婪),總是嘗試匹配盡可能多的字符;非貪婪則相反,總是嘗試匹配盡可能少的字符。在
"*","?","+","{m,n}"後面加上?,使貪婪變成非貪婪。
>>> import re
>>> str = 'www.baidu.com/path'
# ‘+’貪婪模式,匹配1個或多個
>>> ret = re.match(r'w+', str)
>>> print(ret.group())
www
# ‘+?’非貪婪模式,匹配1個
>>> ret = re.match(r'w+?', str)
>>> print(ret.group())
w
# {2,5}貪婪模式最少匹配2個,最多匹配5個
>>> ret = re.match(r'w{2,5}', str)
>>> print(ret.group())
www
# {2,5}?非貪婪模式,匹配兩個
>>> ret = re.match(r'w{2,5}?', str)
>>> print(ret.group())
ww
與大多數編程語言相同,正則表達式裡使用
""作為轉義字符,這就可能造成反斜槓困擾。假如你需要匹配文本中的字符"",那麼使用編程語言表示的正則表達式裡將需要4個反斜槓"\":前兩個和後兩個分別用於在編程語言裡轉義成反斜槓,轉換成兩個反斜槓後再在正則表達式裡轉義成一個反斜槓。
Python裡的原生字符串
r'很好地解決了這個問題,有了原生字符串,你再也不用擔心是不是漏寫了反斜槓,寫出來的表達式也更直觀。
>>> import re
>>> mm = "c:\a\b\c"
>>> mm
'c:\a\b\c'
>>> print(mm)
c:ac
>>> re.match("c:\\",mm).group()
'c:\'
>>> ret = re.match("c:\\",mm).group()
>>> print(ret)
c:
>>> ret = re.match("c:\\a",mm).group()
>>> print(ret)
c:a
>>> ret = re.match(r"c:\a",mm).group()
>>> print(ret)
c:a
>>> ret = re.match(r"c:a",mm).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>>
說明:Python中字符串前面加上 r 表示原生字符串,
>>> ret = re.match(r"c:\a",mm).group()
>>> print(ret)
c:a
練習1:從下面的字符串中取出文本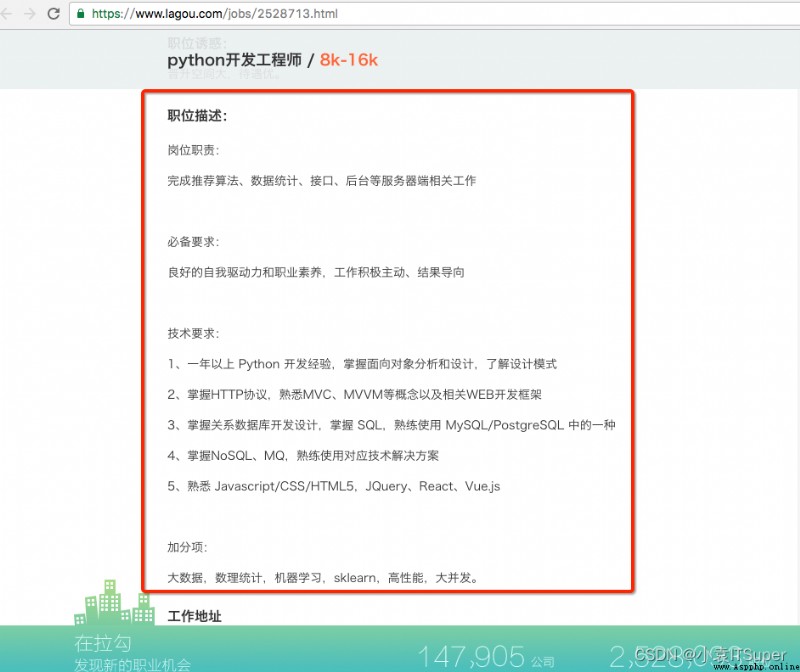
字符串:
<div>
<p>崗位職責:</p>
<p>完成推薦算法、數據統計、接口、後台等服務器端相關工作</p>
<p><br></p>
<p>必備要求:</p>
<p>良好的自我驅動力和職業素養,工作積極主動、結果導向</p>
<p> <br></p>
<p>技術要求:</p>
<p>1、一年以上 Python 開發經驗,掌握面向對象分析和設計,了解設計模式</p>
<p>2、掌握HTTP協議,熟悉MVC、MVVM等概念以及相關WEB開發框架</p>
<p>3、掌握關系數據庫開發設計,掌握 SQL,熟練使用 MySQL/PostgreSQL 中的一種<br></p>
<p>4、掌握NoSQL、MQ,熟練使用對應技術解決方案</p>
<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>
<p> <br></p>
<p>加分項:</p>
<p>大數據,數理統計,機器學習,sklearn,高性能,大並發。</p>
</div>
參考答案:re.sub(r"<[^>]*>| | ", "", test_str)
練習2:提取img標簽中的圖片鏈接地址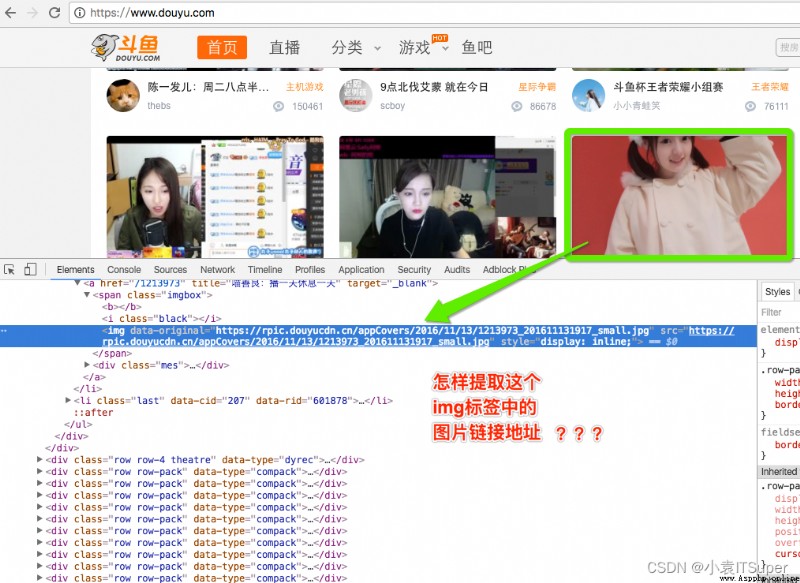
字符串為:
<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" >
參考答案:re.search(r"https://.*?.jpg", test_str)
練習3:排除指定字符串
使用^(?!.*abc).*$,其中的abc為要排除的字符串
import re
partten = r'^(?!.*abc).*$'
strs = ['abc222', '111abc222', '111abc', 'defg']
for i in strs:
print(re.findall(partten, i))
輸出結果:
[]
[]
[]
['defg']
分析:
^和$表示從字符串開頭開始,匹配到結尾(?!.*)表示排除形如’…abc’的部分.*表示’abc’後面還可以有內容先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦