???作者介紹:Python領域優質創作者、華為雲享專家、阿裡雲專家博主、2021年CSDN博客新星Top6
???本文已收錄於Python全棧系列專欄:《100天精通Python從入門到就業》
???此專欄文章是專門針對Python零基礎小白所准備的一套完整教學,從0到100的不斷進階深入的學習,各知識點環環相扣
???訂閱專欄後續可以閱讀Python從入門到就業100篇文章;還可私聊進兩百人Python全棧交流群(手把手教學,問題解答); 進群可領取80GPython全棧教程視頻 + 300本計算機書籍:基礎、Web、爬蟲、數據分析、可視化、機器學習、深度學習、人工智能、算法、面試題等.
???加入我一起學習進步,一個人可以走的很快,一群人才能走的更遠!
Selenium 是一個用於測試 Web 應用程序的框架,該框架測試直接在浏覽器中運行,就像真實用戶操作一樣.在爬蟲領域 selenium 同樣是一把利器,能夠解決大部分的網頁的反爬問題.Selenium 可以根據我們的指令,讓浏覽器自動加載頁面,獲取需要的數據,甚至頁面截屏,或者判斷網站上某些動作是否發生.
1. window電腦點擊win鍵+ R,輸入:cmd
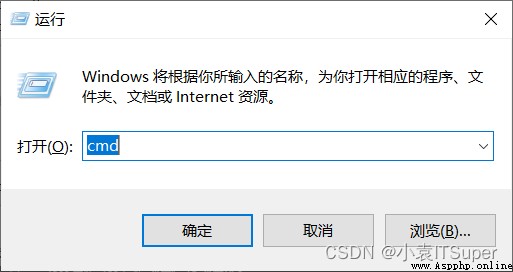
2. 安裝selenium,輸入對應的pip命令:pip install selenium
Selenium 庫裡有個叫 WebDriver 的 API.WebDriver 有點兒像可以加載網站的浏覽器,但是它也可以像 BeautifulSoup 或者其他 Selector 對象一樣用來查找頁面元素,與頁面上的元素進行交互 (發送文本、點擊等),以及執行其他動作.
Chrome浏覽器驅動下載地址:http://chromedriver.storage.googleapis.com/index.html
Firefox浏覽器驅動下載地址:https://github.com/mozilla/geckodriver/releases/
Edge浏覽器驅動下載地址::https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/#downloads
PhantomJS安裝教程(無界面浏覽器,它會把網站加載到內存並執行頁面上的 JavaScript,因為不會展示圖形界面,所以運行起來比完整的浏覽器要高效):PhantomJS浏覽器下載安裝、配置環境變量及使用教程
注意:需要下對應浏覽器版本的驅動,下載安裝步驟如下:
1. 確定浏覽器的版本: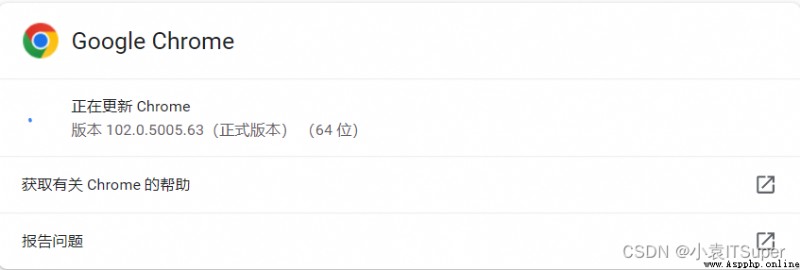
2. 找到最相近的那個點擊,下載對應的Chrome驅動版本:
3. 選擇合適的操作系統: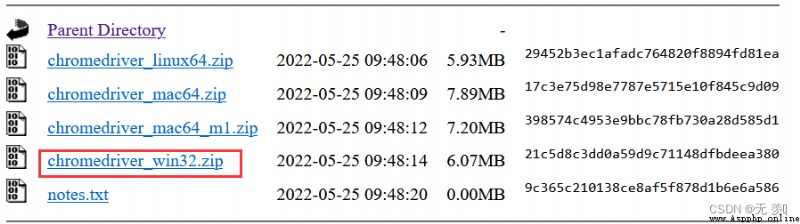
4. 安裝包解壓後放進Python安裝路徑下:
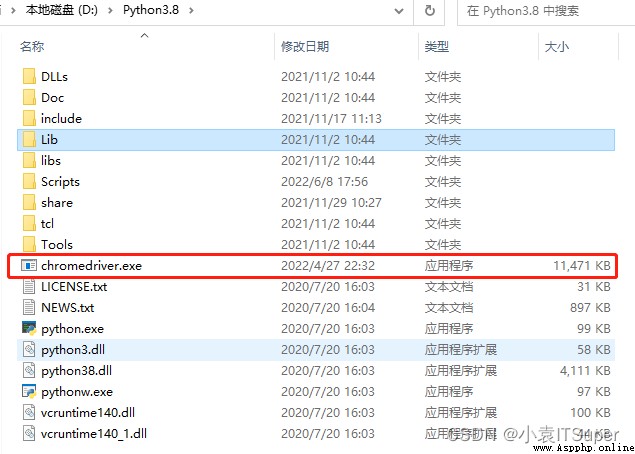
操作 Chrome 浏覽器:
from selenium import webdriver
# 浏覽器的初始化
browser = webdriver.Chrome()
# 發送請求
browser.get('https://www.baidu.com/')
# 打印頁面的標題
print(browser.title)
# 退出模擬浏覽器
browser.quit() # 一定要退出!不退出會有殘留進程
操作 Firefox 浏覽器:
from selenium import webdriver
# 浏覽器的初始化
browser = webdriver.Firefox()
# 發送請求
browser.get('https://www.baidu.com/')
# 打印頁面的標題
print(browser.title)
# 退出模擬浏覽器
browser.quit() # 一定要退出!不退出會有殘留進程
操作 Edge 浏覽器:
from selenium import webdriver
# 浏覽器的初始化
browser = webdriver.Edge()
# 發送請求
browser.get('https://www.baidu.com/')
# 打印頁面的標題
print(browser.title)
# 退出模擬浏覽器
browser.quit() # 一定要退出!不退出會有殘留進程
操作 PhantomJS 浏覽器:
from selenium import webdriver
# 初始化浏覽器
browser = webdriver.PhantomJS()
# 發送請求
browser.get('https://www.baidu.com/')
# 打印頁面的標題
print(browser.title)
# 退出模擬浏覽器
browser.quit() # 一定要退出!不退出會有殘留進程
Headless 模式是 Chrome 浏覽器的無界面形態,可以在不打開浏覽器的前提下,使用所有 Chrome 支持的特性運行我們的程序
from selenium import webdriver
# 1. 實例化配置對象
chrome_options = webdriver.ChromeOptions()
# 2. 配置對象添加開啟無界面命令
chrome_options.add_argument('--headless')
# 3. 配置對象添加禁用gpu命令
chrome_options.add_argument('--disable-gpu')
# 4. 實例化帶有配置對象的browser 對象
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.baidu.com/')
# 查看請求的數據
print(browser.page_source) # 查看渲染後的數據,就可以Xpath進行解析獲取數據了
print(browser.get_cookies()) # 查看請求頁面後的cookies值
print(browser.current_url) # 查看請求url
# 關閉頁面
browser.close()
# 關閉浏覽器
browser.quit()
通過selenium的基本使用可以簡單操作浏覽器了,接下來我們再來學習下定位元素的其他方法
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.xxx.com/'
browser.get(url)
html_str = browser.page_source
假設訪問地址某網址,返回 html_str 為如下內容:
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel_body">
<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<a href="https://www.baidu.com">百度官網</a>
<li class="element">Bar</li>
</ul>
</div>
</div>
1.根據 id 屬性值獲取元素列表:
from selenium.webdriver.common.by import By
# 獲取第一個元素
browser.find_element(by=By.ID, value="list-1")
# 獲取多個元素
browser.find_elements(by=By.ID, value="list-1")
2. 根據 class 獲取元素列表:
# 獲取第一個元素
browser.find_element(by=By.CLASS_NAME, value="element")
# 獲取多個元素
browser.find_elements(by=By.CLASS_NAME, value="element")
3. 根據Xpath獲取元素列表:
# 返回標簽為li,id為element的所有元素
browser.find_element(by=By.XPATH, value="//li[@id='element']")
browser.find_elements(by=By.XPATH, value="//li[@id='element']")
4. 根據標簽的文本獲取元素列表(精確定位):
# 獲取一個元素
browser.find_element(by=By.LINK_TEXT, value="Foo")
# 獲取多個元素
browser.find_elements(by=By.LINK_TEXT, value="Foo")
5. 根據標簽包含的文本獲取元素列表(模糊定位):
# 獲取一個元素
browser.find_element(by=By.PARTIAL_LINK_TEXT, value="Fo")
# 獲取多個元素
browser.find_elements(by=By.PARTIAL_LINK_TEXT, value="Fo")
6. 根據標簽名獲取元素列表:
# 獲取一個元素
browser.find_element(by=By.TAG_NAME, value="li")
# 獲取多個元素
browser.find_elements(by=By.TAG_NAME, value="li")
1. 獲取文本(通過定位獲取的標簽對象的text屬性,獲取文本內容):element.text
ret = browser.find_element_by_class_name('element')
print(ret[0].text)
2. 獲取屬性值(通過定位獲取的標簽對象的get_ attribute 函數,傳入屬性名,來獲取屬性的值):
ret = browser.find_element_by_tag_name('a')
print(ret[0].get_attribute('href'))
# 前進
browser.forward()
# 後退
browser.back()
selenium可以讓浏覽器執行我們規定的js代碼:
browser.execute_script(js)
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.baidu.com/'
browser.get(url)
js = 'window.scrol1To(O,document.body.scrollHeight)' # js語句
browser.execute_script(js) # 執行js的方法
browser.quit()
現在的網頁越來越多采用了 Ajax 技術,這樣程序便不能確定何時某個元素完全加載出來了.如果實際頁面等待時間過長導致某個dom元素還沒出來,但是你的代碼直接使用了這個WebElement,那麼就會拋出NullPointer的異常.
為了避免這種元素定位困難而且會提高產生 ElementNotVisibleException 的概率.所以 Selenium 提供了兩種等待方式,一種是隱式等待,一種是顯式等待.
隱式等待是等待特定的時間,顯式等待是指定某一條件直到這個條件成立時繼續執行.
隱式等待針對的是元素定位,隱式等待設置了一個時間,在一段時間內判斷元素是否定位成功,如果完成了,就進行下一步.在設置的時間內沒有定位成功,則會報超時加載
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 隱式等待10秒
driver.get('https://www.baidu.com/')
myDynamicElement = driver.find_element_by_id("input")
顯式確定等待指定某個元素,然後設置最長等待時間.如果在這個時間還沒有找到元素,那麼便會拋出異常了.
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 庫,負責循環等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 類,負責條件出發
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
try:
# 頁面一直循環,直到 id="input" 出現
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "input"))
)
finally:
driver.quit()
selenium控制浏覽器也是可以使用代理ip的.
from selenium import webdriver
import time
# 1. 實例化配置對象
options = webdriver.ChromeOptions()
# 2. 配置對象添加使用代理ip的命令
options.add_argument('--proxy-server=http://ip地址') # 代理IP:端口號
# 3. 實例化帶有配置對象的driver對象
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://www.baidu.com")
# 獲取頁面內容
print(driver.page_source)
# 延遲3秒後關閉當前窗口,如果是最後一個窗口則退出
time.sleep(3)
driver.close()
selenium可以修改請求頭,偽裝不同浏覽器
from selenium import webdriver
import time
agent = 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1'
# 1. 實例化配置對象
options = webdriver.ChromeOptions()
# 2. 配置對象修改請求頭
options.add_argument('--user-agent=' + agent)
# 3. 實例化帶有配置對象的driver對象
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://www.baidu.com")
# 獲取頁面內容
print(driver.page_source)
# 延遲3秒後關閉當前窗口,如果是最後一個窗口則退出
time.sleep(3)
driver.close()
selenium 操作浏覽器,有幾十個特征可以被網站檢測到,輕松的識別出你是爬蟲.
正常情況手動打開浏覽器,輸入網址https://bot.sannysoft.com/: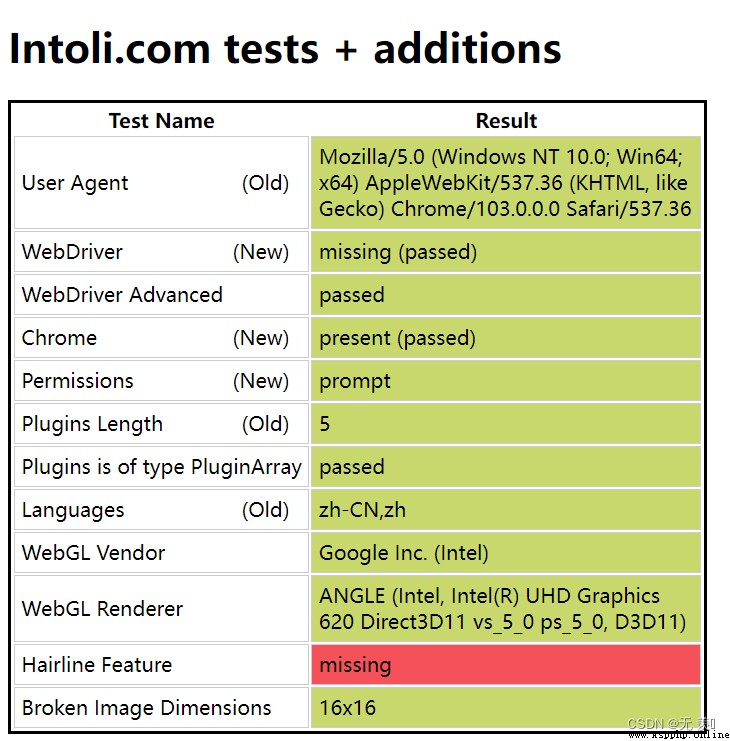
selenium 無界面模式打開浏覽器:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get('https://bot.sannysoft.com/')
# 對當前頁面進行截圖
driver.save_screenshot('1.png')
生成圖片: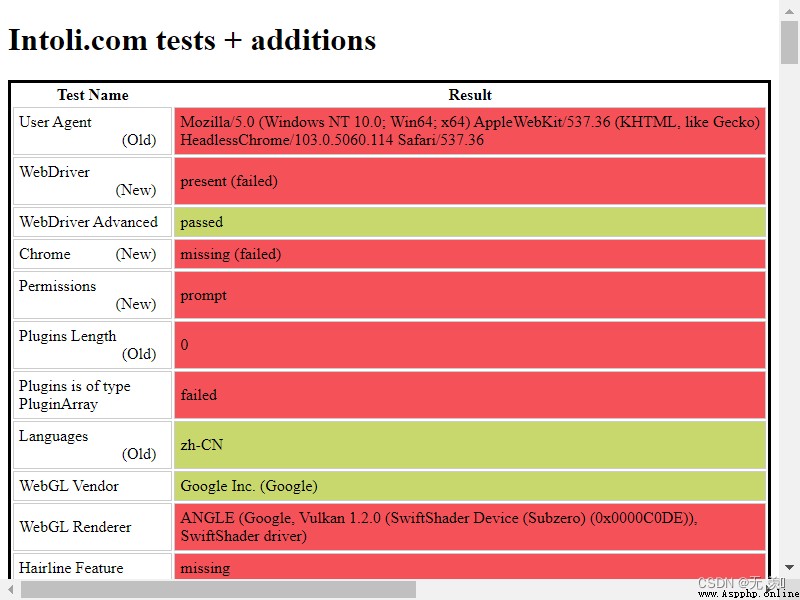
很明顯就已經被網站發現是爬蟲了!
解決浏覽器指紋特征關鍵,實際就是一個 stealth.min.js 文件,通過Python執行這個js文件可以隱藏浏覽器指紋
stealth.min.js文件下載地址:關注文末公眾號,回復:隱藏浏覽器指紋
添加請求頭 + 執行 stealth.min.js 文件進行隱藏浏覽器指紋:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 添加請求頭偽裝浏覽器
chrome_options.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
driver = webdriver.Chrome(chrome_options=chrome_options)
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('2.png')
運行結果: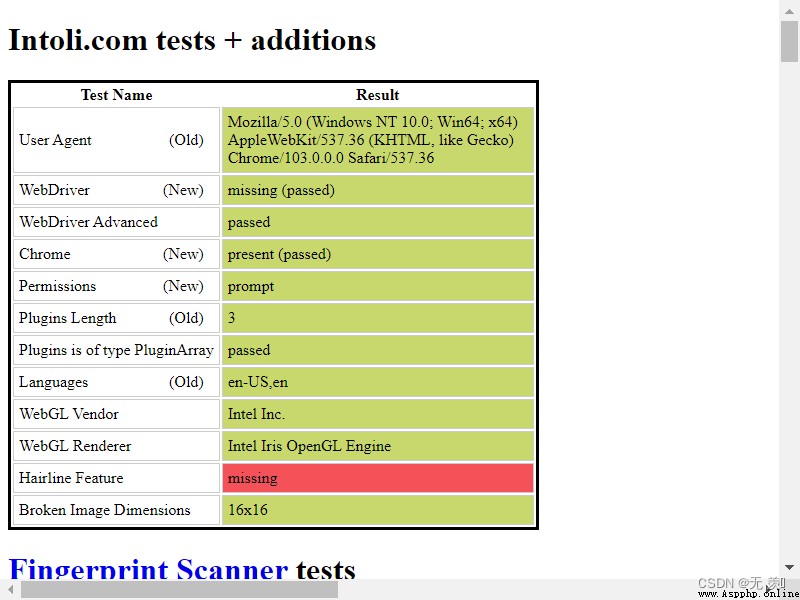
通過執行 stealth.min.js 進行隱藏浏覽器指紋,已經和正常訪問一樣了!
書籍展示:《人工智能原理與實踐 》

【書籍內容簡介】
- 涵蓋人工智能和數據科學各個重要體系,通過算法中最重要的理論推導和精華分析+六大典型AI和數據科學應用場景,深入淺出地講解和展示機器學習應用的具體流程.
全面:涵蓋人工智能和數據科學各個重要體系經典:世界名校AI專業深造,國際大行實戰經驗系統:重要理論和公式層層推導,闡述深入淺出實戰:六大典型AI和數據科學應用場景,透徹分析和代碼實現
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在.深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小.自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前.因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔.添加下方名片,即可獲取全套學習資料哦
 Python learning notes (27) -- basic operations of extracting text and table content from pdfplumber Library
Python learning notes (27) -- basic operations of extracting text and table content from pdfplumber Library
pdfplumber Library installatio
 [Python] use the PAHO mqtt library to realize mqtt listening and sending / receiving
[Python] use the PAHO mqtt library to realize mqtt listening and sending / receiving
Reprinted from : How to be in
 Popular short video recommendation for computer graduation design Python+django (source code + system + mysql database + Lw document)
Popular short video recommendation for computer graduation design Python+django (source code + system + mysql database + Lw document)
Project IntroductionThe system