目錄
編輯
目標網站:
Lead environmental needs
爬取需求:The first five pages of the following
File save demand:
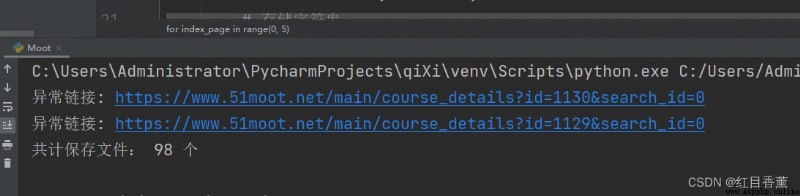
If there is abnormal links:內容為空的try:except:跳過
The page number logic:page_index=[0-4]
HTML-CSS拆解:
The sample code:
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=0
pip3 config set global.index-url https://repo.huaweicloud.com/repository/pypi/simple
pip3 config list
pip3 install --upgrade pip
pip3 install requests
pip3 install scrapy
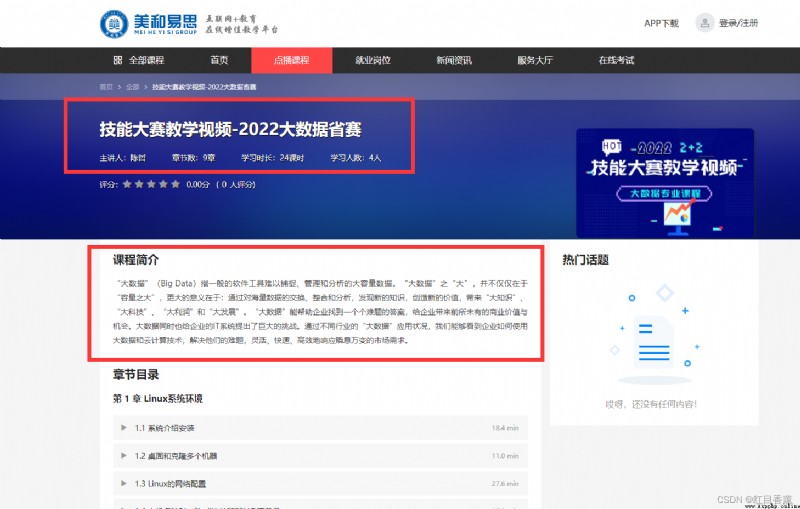
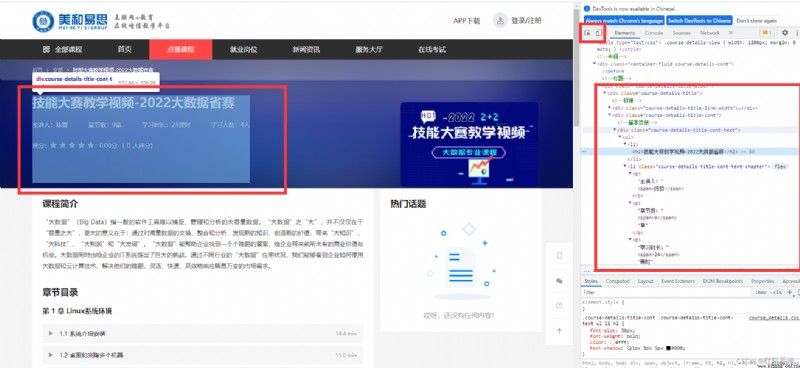
1、課程標題
2、主講人
3、章節數
4、學習時長
5、學習人數
6、課程簡介
將5Page content of all the courses in each course a【課程名稱.txt】File to save.
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=0
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=1
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=2
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=3
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=4
So a loop done.
第一層CSS拆解
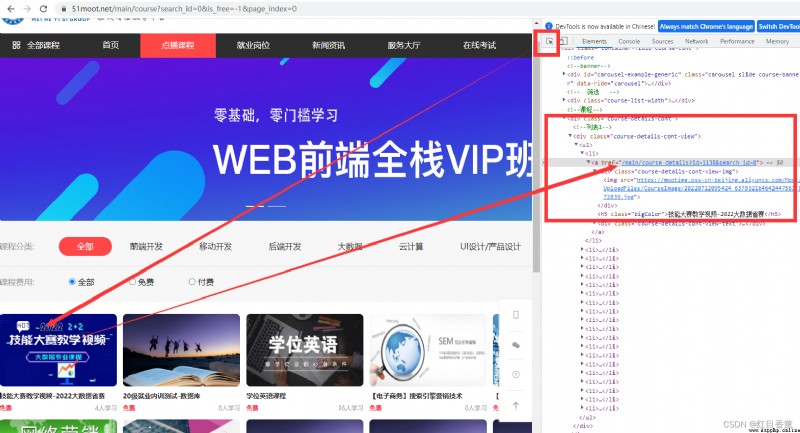
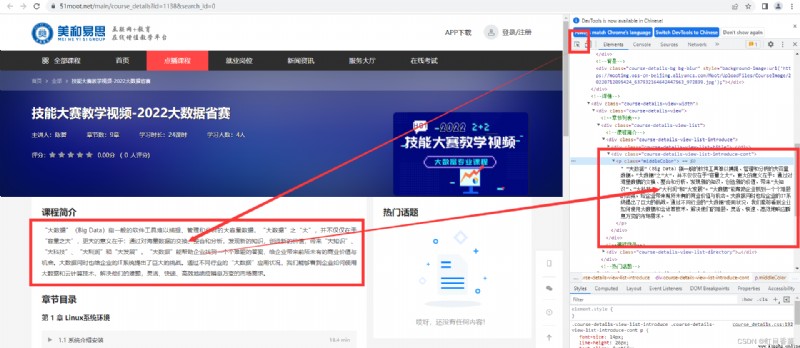
第二層CSS拆解
import pathlib
import uuid
from requests import get
from scrapy.selector import Selector
# 域名
urlHttp = "https://www.51moot.net"
# Effective link statistics
count = 0
for index_page in range(0, 5):
html = get(
"https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index={0}".format(index_page)).content.decode(
"utf-8")
sel = Selector(text=html)
result = sel.css("div.course-details-cont-view ul li a::attr(href)").extract()
for x in result:
# 添加域名
x = urlHttp + x
html = get(x).content.decode("utf-8")
sel = Selector(text=html)
# 存儲字符串
strInfo = ""
title = sel.css("div.course-details-title-cont-text h2::text").extract()[0]
infos = sel.css(
"div.course-details-title-cont-text li.course-details-title-cont-text-chapter span::text").extract()
introduce = sel.css(
"div.course-details-view-list div.course-details-view-list-introduce-cont p::text").extract()[0]
strInfo += title + "\n"
strInfo += "主講人:{0}\t章節數:{1}\t學習時長:{2}課時\t學習人數:{3}人\n".format(infos[0], infos[1], infos[2], infos[3])
strInfo += "課程簡介:{0}".format(introduce)
# There are abnormal directly to continue
try:
saveUrl = str.format("D:/save51Moot/{0}{1}", title, ".txt")
path = pathlib.Path(saveUrl)
if path.exists():
saveUrl = str.format("D:/save51Moot/{0}{1}{2}", title, uuid.uuid4(), ".txt")
file = open(saveUrl, "w", encoding="utf-8")
file.write(strInfo)
file.close()
count += 1
except:
print("異常鏈接:", x)
print("A total of save the file:", count, "個")
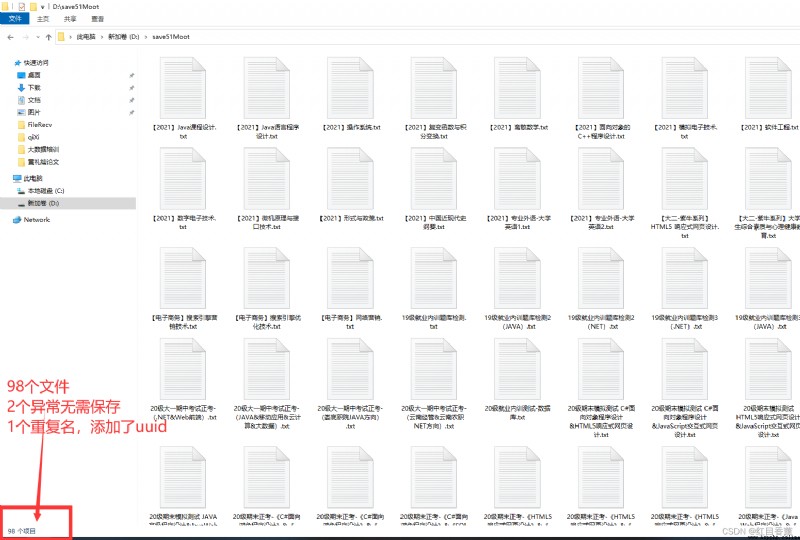 Can see there are more than an addeduuid這樣簡單一些,我沒做set去重.
Can see there are more than an addeduuid這樣簡單一些,我沒做set去重.
提交需求:
1、項目壓縮包
2、截圖,Capture requirements as follows: