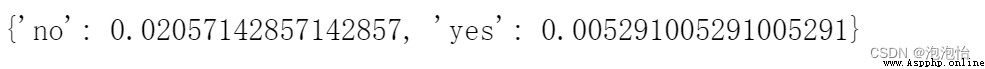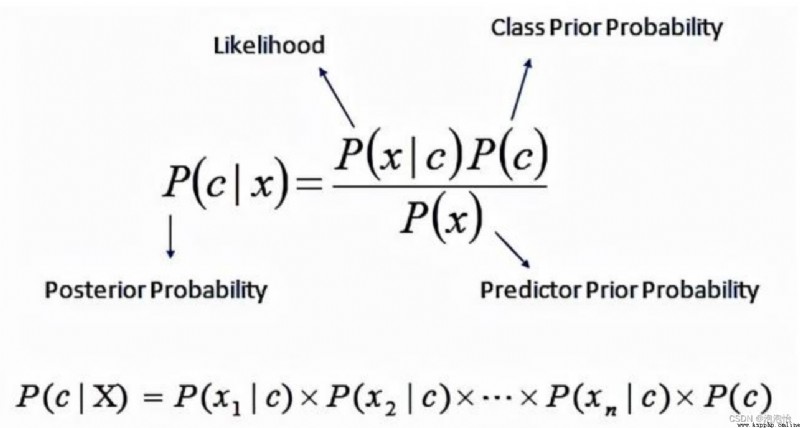
案例:
1.導入package:
import pandas as pd
import numpy as np2.創建實例數據集:
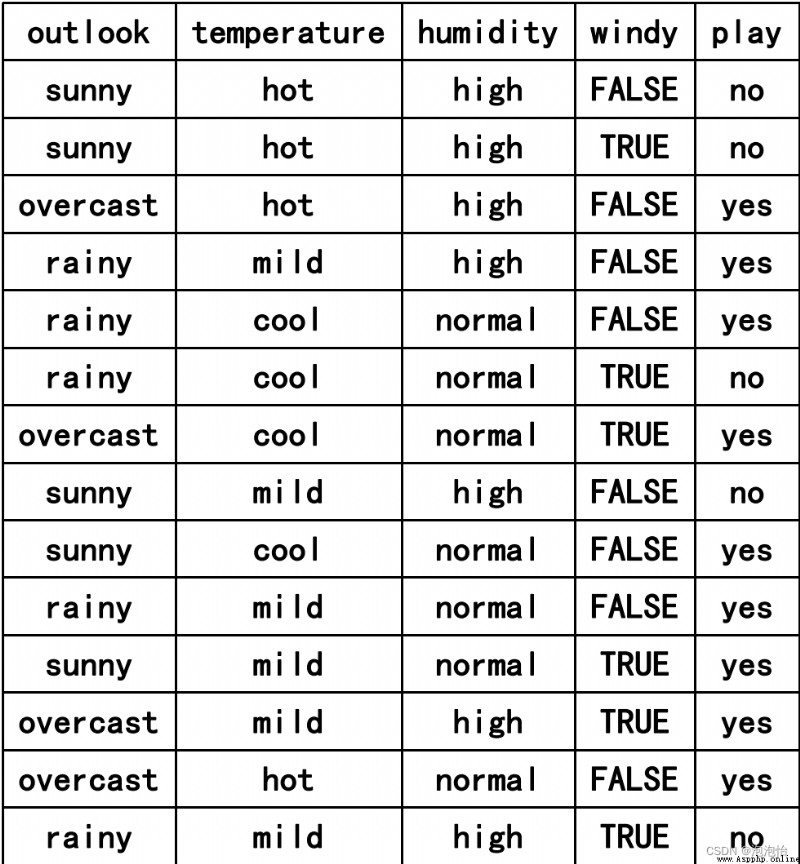
outlook=['sunny','sunny','overcast','rainy','rainy','rainy','overcast','sunny','sunny','rainy','sunny','overcast','overcast','rainy']
temperature=['hot','hot','hot','mild','cool','cool','cool','mild','cool','mild','mild','mild','hot','mild']
humdity=['high','high','high','high','normal','normal','normal','high','normal','normal','normal','high','normal','high']
windy=['FALSE','TRUE','FALSE','FALSE','FALSE','TRUE','TRUE','FALSE','FALSE','FALSE','TRUE','TRUE','FALSE','TRUE']
play=['no','no','yes','yes','yes','no','yes','no','yes','yes','yes','yes','yes','no']
data=pd.DataFrame({'outlook':outlook,'temperature':temperature,'humdity':humdity,'windy':windy,'play':play})
data.head()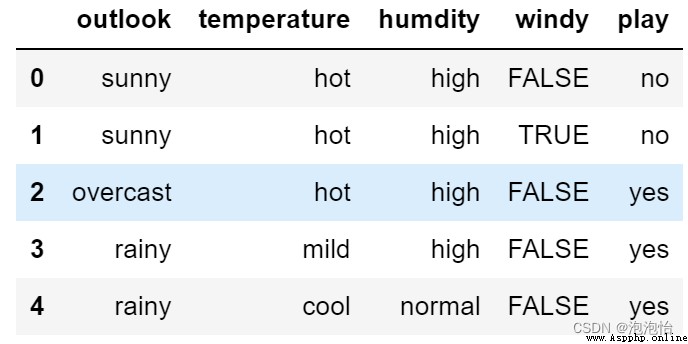
3. 取出特征和標簽:
X=data.drop(['play'],axis=1)
y=data['play']4.定義樸素貝葉斯訓練過程:
def nb_fit(X,y):
classes=y.unique()
class_count=y.value_counts()
class_prior=class_count/len(y)
prior=dict()
for col in X.columns:
for j in classes:
p_x_y=X[(y==j).values][col].value_counts()
for i in p_x_y.index:
prior[(col,i,j)]=p_x_y[i]/class_count[j]
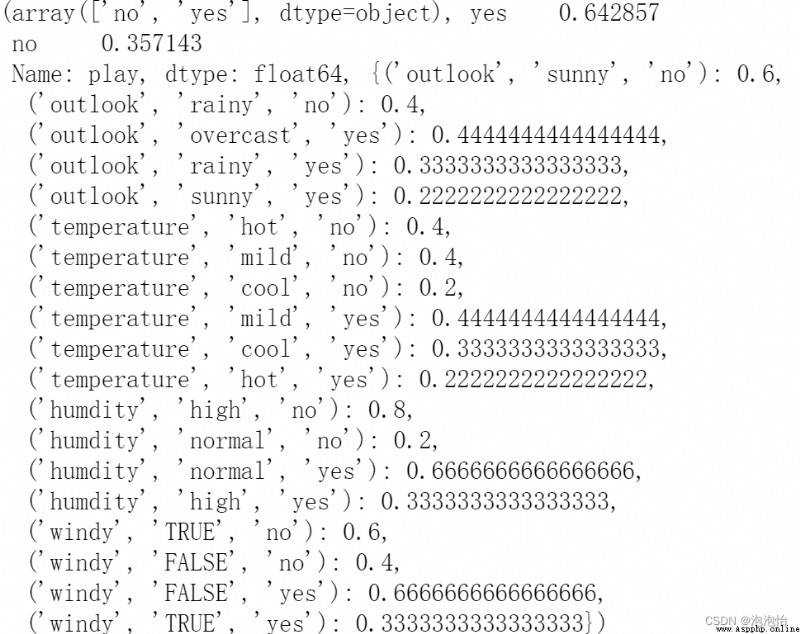
return classes,class_prior,prior擬合示例如下:
nb_fit(X,y)
5.定義預測函數:
def predict(X_test):
result=dict()
for c in classes:
p_y=class_prior[c]
p_x_y=1
for i in X_test.items():
p_x_y*=prior[tuple(list(i)+[c])]
result[c]=p_y*p_x_y
return result6.給定測試實例並進行預測:
X_test={'outlook':'sunny','temperature':'cool','humdity':'high','windy':'TRUE'}
X_test.items()
result=predict(X_test)
result
結果如下: