應用場景:數據處理、網絡應用的後端編寫、自動化腳本
基礎學習:1.python能做什麼;2.變量算法解釋器、基本數據類型、列表元組字符串字典操作方法;3.條件,循環和相關執行語句(if else elif while for continue bresk 列表推導式 異常處理);4.面向對象OOP,程序結構
、代碼重用避免代碼冗余打包代碼
Alt+Enter 快速修復當前代碼,沒有import進模塊,自動導入模塊
ctrl+X 刪除整行代碼
Ctrl+Alt+L PEP8的代碼標准將當前代碼格式化
# print可以輸出數字、字符串、數字表達式;(輸出在控制台上)
print(3.14)
print(56)
print('人生苦短,我用python')
print(3+4)
# print將文件輸出到文件中;
# 運行幾次就輸出幾次
fe = open('E:/(network)/python資料及練習/test.txt','a+') # a+表示如果文件不存在就創建,存在就在文件內容後面追加
print('hello world!',file = fe)
fe.close()
# print輸出內容在一行當中,用逗號,輸出以空格相隔
print('hello','world','python')
輸出結果:3.14
56
人生苦短,我用python
7
hello world python
注意:print函數的括號裡有判斷的話返回值為布爾值!
# 轉義字符:\ 加轉義功能的首字母
print('hello\nworld') # 換行--newline
print('hello\tworld') # tab,一個tab鍵四個空格
print('helloooo\tworld')
print('hello\rworld') # 回車,world將hello覆蓋
print('hello\bworld') # 退一格
print('http:\\\\www.baidu.com')
print('她說:’我要學習python‘') #python3支持中文,python2的話這樣寫:print('她說:’我要學習python‘')
# 元字符,不希望字符串中的轉義字符起作用,就使用元字符,在字符串之前加上r,或R
print(r'hello\nworld')
print(r'hello\nworld') # 注意末尾不能加反斜槓\:print(r'hello\nworld\')
輸出結果:
hello
world
hello world
helloooo world
world
hellworld
http:\www.baidu.com
她說:’我要學習python‘
hello\nworld
hello\nworld
# 字符編碼:GBK unicode--utf-8
print(chr(0b100111001011000))
print(ord('乘'))
# 標識符和保留字
import keyword
print(keyword.kwlist) #輸出的就為保留字
# 標識符規則:不能以數字、保留字開頭,區分大小寫;變量、函數、類、模塊和其它對象起的名字為標識符
輸出結果:
乘
20056
['False', 'None', 'True', 'peg_parser', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
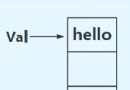
# 變量:內存中一個帶標簽的盒子;name(變量名)=(賦值運算符)馬麗榮(值)
# 變量由三部分組成:ID,type,value;
name = "馬麗榮"
print(name)
print('標識:',id(name))
print('類型:',type(name))
print('值:',name)
輸出結果:
馬麗榮
標識: 2080713636240
類型: <class 'str'>
值: 馬麗榮
當變量多次賦值之後,變量名會指向新的空間;
name = '馬麗亞'
name = '出溜冰'
print(name)
輸出結果:出溜冰
name = '馬麗亞'
print(name)
name = '出溜冰'
print(name)
輸出結果:
馬麗亞
出溜冰
# 可以表示為正數、負數、零;
n1 = 90
n2 = -76
n3 = 0
print(n1,type(n1))
print(n2,type(n2))
print(n3,type(n3))
輸出結果:
90 <class 'int'>
-76 <class 'int'>
0 <class 'int'>
# 可以表示為二進制、八進制、十六進制,默認為十進制
print('十進制',118) # 范圍0-9
print('八進制',0o176) # 范圍0-7 以0o開頭
print('十六進制',0x0AF6) # 范圍0-9 A-F 以0x開頭
print('二進制',0b11111111) # 范圍0-1,以0b開頭
輸出結果:
十進制 118
八進制 126
十六進制 2806
二進制 255
a = 3.14159
print(a,type(a))
# 使用浮點數進行計算,可能會出現位數不確定的情況
n = 1.1
n1 = 2.2
n2 = 3.3
print(n+n1)
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))
輸出結果:
3.14159 <class 'float'>
3.3000000000000003
3.3
# 表示真或假的值
f1 = True
f2 = False
print(f1,type(f1))
print(f2,type(f2))
print(f1+1) # 1+1=2,f1為真表示1
print(f2+1) # 0+1=1,f2為假表示0
輸出結果:
True <class 'bool'>
False <class 'bool'>
2
1
# 稱為不可變的字符序列
str = '人生苦短,我用python' #單引號與雙引號都可表示一行的字符串
str1 = "人生苦短,我用python"
str2 = '''
人生苦短,我用python1
人生苦短,我用python2
人生苦短,我用python3
''' # 三引號定義的字符串可以分布在連續的多行
print(str,type(str))
print(str1,type(str1))
print(str2,type(str2))
輸出結果:
人生苦短,我用python <class 'str'>
人生苦短,我用python <class 'str'>
人生苦短,我用python1
人生苦短,我用python2
人生苦短,我用python3
<class 'str'>
# 數據類型轉化,將不同的數據類型的數據拼接在一起;
name = '張三'
age = 20
print(type(name),type(age)) # 數據類型不同
# print('我叫'+name+'今年,'+age+'歲') # 報錯,類型轉化
print('我叫'+name+',今年'+str(age)+'歲') # 加號為連接符
輸出結果:
<class 'str'> <class 'int'>
我叫張三,今年20歲
print('--------------str()函數將其他類型轉化成str類型----------')
a = 10
b = 198.9
c = False
print(type(a),type(b),type(c))
print(type(str(a)),type(str(b)),type(str(c)))
輸出結果:
--------------str()函數將其他類型轉化成str類型----------
<class 'int'> <class 'float'> <class 'bool'>
<class 'str'> <class 'str'> <class 'str'>
print('-----------int()函數將其他類型轉化為int類型--------')
# 文字類與小數類的字符串不能轉化為int;浮點數轉化為int,末尾為0
s1 = '128'
f1 = 1.595
s2 = '77.889'
ff = True
s3 = 'hello'
print(type(s1),type(f1),type(s2),type(ff),type(s3))
print(int(s1),type(int(s1))) # 將字符串轉化為整形,字符串為整數
print(int(f1),type(int(f1))) # 將float轉成int類型,截取整數
# print(int(s2),type(int(s2))) # 報錯,字符串內為小數串
print(int(ff),type(int(ff)))
# print(int(s3),type(int(s3))) # 字符串內為字母,不能轉為int
輸出結果:
-----------int()函數將其他類型轉化為int類型--------
<class 'str'> <class 'float'> <class 'str'> <class 'bool'> <class 'str'>
128 <class 'int'>
1 <class 'int'>
1 <class 'int'>
print('-----------float()函數將其他類型轉化為float型------------')
#文字類無法轉化為浮點型;整數轉成浮點數,末尾為.0
ss1 = 128
ff1 = 1.595
ss2 = '77.889'
fff = False
ss3 = 'hello'
print(type(ss1),type(ff1),type(ss2),type(fff),type(ss3))
print(float(ss1),type(float(ss1)))
print(float(ff1),type(float(ff1)))
print(float(ss2),type(float(ss2)))
print(float(fff),type(float(fff)))
# print(float(ss3),type(float(ss3)))
輸出結果:
-----------float()函數將其他類型轉化為float型------------
<class 'int'> <class 'float'> <class 'str'> <class 'bool'> <class 'str'>
128.0 <class 'float'>
1.595 <class 'float'>
77.889 <class 'float'>
0.0 <class 'float'>
python中的注釋:中文編碼注釋-->在文件開頭加上中文聲明注釋,用以指定源碼文件的編碼格式!
#coding:utf-8 或者 gbk
介紹:接收來自用戶的輸入;返回類型為str;對輸入的值進行存儲;
present = input('大聖想要神魔禮物:')
print(present,type(present))
輸出結果:
大聖想要神魔禮物:金箍棒
金箍棒 <class 'str'>
# 練習:輸入兩個整數,並對其求和;
nu1 = int(input('輸入第一2個數:'))
nu2 = int(input('輸入第二個數:'))
sum = nu1+nu2
print(sum)
輸出結果:
輸入第一個數:2
輸入第二個數:2
4
加(+)、減(-)、乘(*)、除(/)、整除(//)
取余運算符:%
冪運算符:**
print(1+1) # 加法運算
print(2-1) # 減法運算
print(2*4) # 乘法運算
print(11/2) # 除法運算
print(6%4) # 取余運算:6除4取余數
print(9//8) # 整除運算:9除8取整商
print(2**3) #冪運算:2的3次方
輸出結果:
2
1
8
5.5
2
1
8
算數運算符:
print(12%8) #4
print(12%-8) # 12-(-8)*(-2)=-4
print(-12%8) # -12-8*(-2)=4
print(-12%-8) # -4
# 輸出結果為
4
-4
4
-4
執行順序為從右-->左;
支持鏈式賦值;a=b=c=20
支持參數賦值;+=、-=、*=、//=、%=
a = 10
a += 12 # a=a+12,a=10
print(a)
# 輸出結果為:22
支持系列解包賦值;a,b,c,=20,30,40
# 交換兩個變量的值
a,b=10,20
print('交換之前:a,b',(a,b))
a,b=b,a
print('交換之後:a,b',(a,b))
輸出結果:
交換之前:a,b (10, 20)
交換之後:a,b (20, 10)
對變量或表達式的結果進行大小、真假等比較;
# 運算符:>,<,>=,<=,!=
# == 對象vlaue的比較,
# is,is not 對象的id比較
”==“比較的是值,而“=”是賦值;比較對象的標識使用的是“is”或“is not”
a=10
b=10
print(a==b) # 返回為True,說明a與b的vlaue相等
print(a is b) # 返回為True,說明a與b的標識相等
print(a,id(a))
輸出結果:
True
True
10 2242092362320
lis1 = [11,22,33,44]
lis2 = [11,22,33,44]
print(lis1==lis2)
print(lis1 is lis2) # id不同
print(lis1,id(lis1))
print(lis2,id(lis2))
print(lis1 is not lis2)
# 輸出結果:
True
False
[11, 22, 33, 44] 2212795138368
[11, 22, 33, 44] 2212795125696
True
比較運算符的結果為布爾類型
a,b = 10,20
print('a>b?',a>b)
輸出結果:
a>b? False
對於布爾值之間的運算;
都有and、or、not in、in;
and:一假則假
a,b = 1,2
print(a==1 and b==2) # True and True 為True
print(a==1 and b<1) # True and Flase 為Flase
print(a!=1 and b==2) # Flase and True 為Flase
print(a!=1 and b<1) # Flase and Flase 為Flase
or:一真則真
print(a==1 or b==2) # True and True 為True
print(a==1 or b<1) # True and Flase 為True
print(a!=1 or b==2) # Flase and True 為FTrue
print(a!=1 or b<1) # Flase and Flase 為Flase
in與not in
f = True
ff = False
print(not f) #對布爾類型操作數進行取反-----Flase
s = 'helloworld'
print('w' in s) # True
print('k' not in s) # True
將數據轉成二進制計算;
1.位與&:對應位數都是1,結果位數才是1,否則為零
print(4&8) # 按位與&,同為1時結果為1(兩個十進制轉化為二進制按位計算)
輸出結果:0
0000 0100
0000 1000
2.位或|:對應位數都是0,結果位數才是0,否則為1
print(4|8) #按位或|,同為0時結果為0
輸出結果:12
0000 0100
0000 1000
0000 1100
3.左移位<<:高位溢出,低位補零(乘以2)
print(4<<1) # 向左移動1位(4乘以2)
輸出結果:8
4.右移位>>:高位補零,低位丟棄(移一位除以2---2的冪)
print(4>>2) # 向右移動2位(4除以2**2)
輸出結果為:1
補:二進制原碼+1=補碼
算數運算符>位運算>比較運算符>布爾運算>賦值運算;
有括號會先計算括號裡的 ;
程序從上到下順序地執行代碼,中間沒有任何的判斷和跳轉,直到程序結束;
對象的布爾值:在python中一切皆對象,所有對象都有一個布爾值,獲取對象的布爾值,使用內置函數bool();
print(bool(False))
print(bool(0))
print(bool(0.0))
print(bool(''))
print(bool(None))
print(bool(""))
print(bool([]))
print(bool(list()))
print(bool(()))
print(bool(tuple()))
print(bool({}))
print(bool(dict()))
print(bool(set()))
print('--以上的對象布爾值為False,其余都為True--')
print(bool(18))
print(bool("hello world"))
False、數值0、None、空字符串、空列表、空元組、空字典、空集合的布爾值為False;
程序根據判斷條件的布爾值選擇性的執行部分代碼,明確的讓計算機知道在神魔的條件下,該去做什麼;
單分支結構:如果...就
money = 1000
je = int(input('取款金額:'))
if je<=money: # if 條件表達式:(條件表達式為布爾值)
money = money-je
print('取款成功,余額為:',money)
# 輸出結果:
取款金額:920
取款成功,余額為: 80
雙分支結構:如果不滿足...就
語法結構:
if 條件表達式:
條件執行體1
else:
條件執行體2
zs = int(input('輸出一個整數:'))
if zs%2==0:
print('此數為偶數!')
else:
print('此數為奇數!')
# 鍵盤中輸入一個數,判斷是否為奇數還是偶數;
輸出結果:
輸出一個整數:100
此數為偶數!
多分支結構:...是...? 是或不是
if 條件表達式1:
條件執行體1
elif 條件表達式2:
條件執行體2
elif 條件表達式N:
條件執行體N
[else:] # 可寫可不寫
條件執行體N+1
# 從鍵盤中錄入一個“整數”成績,判斷它的范圍
# 90-100:A 80-90:B 70-80:C 60-70:及格 60以下不及格
score = int(input('請輸入一個整數成績:'))
if score>=90 and score<=100:# 可以寫成90<=score<=100
print('A')
elif score>=80 and score<90:
print('B')
elif score>=70 and score<80:
print('良好')
elif score>=60 and score<70:
print('合格')
elif score<60 and score>=0:
print('不及格')
else:
print('對不起,輸入的成績不在范圍之內!')
輸出結果:
請輸入一個整數成績:88
B
嵌套if
語法結構:
if 條件表達式1:
if 內層條件表達式:
內層條件執行體1
else:
內層條件執行體2
else:
條件執行體
'''
會員 >=200 8折
>=100 9折
不打折
非會員 >=200 9.5折
不打折
'''
huiyuan = input('是否為會員y/n:')
money = float(input('請輸入錢:'))
if huiyuan=='y': # 判斷為會員
if money>=200:
print('會員最後金額為:',money*0.8)
elif money>=100:
print('會員最後金額為:',money*0.9)
else:
print('會員最後金額為:',money)
else: # 判斷不會為會員
if money>=200: # 大於等於號前後注意空格,空格也有影響;
print('最後非會員金額為:',money*0.95)
else:
print('最後非會員金額為:',money)
# 輸出結果:
是否為會員y/n:n
請輸入錢:1000
最後非會員金額為: 950.0
從鍵盤中輸入兩個數,比較兩個數的大小(兩種表達方法):
num = float(input('輸入第一個數:'))
numm = float(input('輸入第二個數:'))
if num>=numm:
print(num,'大於等於',numm)
else:
print(num,'小余等於',numm)
或 條件表達式
num = float(input('輸入第一個數:'))
numm = float(input('輸入第二個數:'))
print((str(num)+'大於等於'+str(numm)) if num>=numm else (str(num)+'小余等於'+str(numm)))
# 如果if後的條件為True就執行前面的語句,為Flase就執行後面的語句;
條件表達式:是if....else的簡寫
語法結構:x if 判斷條件 else y
運算規則:如果判斷條件的布爾值為True,條件表達式的返回值為x,否則條件表達式的返回值為Flase;
pass語句
是:語句什麼都不做,只是一個占位符,用在語法上需要語句的地方;
什麼時候用:先搭建語法結構,還沒想好代碼怎麼寫的時候
與哪些語句一起使用:if 語句的條件執行體、for-in語句循環體、定義函數的函數體
內置函數range()函數(內置函數:前面不用加任何前綴,可以直接使用的函數):用於生成一個整數序列;將range函數作為循環遍歷的對象!
創建range對象的三種方式:
range(stop) 創建一個(0,stop)之間的整數序列,步長為1;
range(start,stop) 創建一個(start,stop)之間的整數序列,步長為1;
range(start,stop,step)
range類型的優點:不管range對象表示的序列有多長,所有range對象占用的內存空間是相同的,因為僅僅需要存儲start和step,只有當用到range對象時,才會計算序列中的相關元素;
'''第一種創建方式:只有一個參數(括號裡只給一個數)'''
rr = range(10) # 默認從0開始,默認步長為1,不包括10
print(rr) # range(0,10) 返回值是一個迭代對象
print(list(rr)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 查看range對象中的整數隊列
'''第二種創建方式:給了兩個參數(括號裡給了兩個數)'''
rr1 = range(1,10) # 指定了起始值,從1開始,到10結束不包括10,默認步長為1
print(rr1) # range(1, 10)
print(list(rr1)) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
'''第三種創建方式:給三個參數'''
rr2 = range(2,11,2)
print(rr2)
print(list(rr2))
'''判斷指定的整數,在序列中是否存在 in 或 not in'''
print(2 in list(rr2))
print(10 not in rr2)
range()函數產生一個整數序列,是一個可迭代對象;
in 與 not in 判斷整數序列中是否存在(不存在)指定的指數;
循環結構:
**while **
語法結構:
while 條件表達式:
條件執行體(循環體)
選擇結構的if與循環結構while的區別:
if是判斷一次,條件為True執行一行;while是判斷N+1次,條件為True執行N次;
while循環的執行流程:
四步循環法:初始變量、條件判斷、條件執行體(循環體)、改變變量
# 計算0-4之間的累加和
sum = 0
'''初始化變量為0'''
i = 0
while i<=4: # 條件判斷
sum = sum + i # 條件執行體(循環體)
i = i+1 # 改變變量
print(sum)
# 計算1-100之間的偶數和
i = 1
sum = 0
while i<=100:
if i%2==0:
sum+=i
i+=1
print(sum)
# 2550
# 計算1-100之間的偶數和
i = 1
sum = 0
while i<=100:
if not bool(i%2): # 為0的布爾值為false,not false=true---執行;1的布爾值為true,not true=false--不執行!
sum+=i
i+=1
print(sum)
for in循環
in表達從(字符串、序列等)中一次取值,又稱為遍歷;
for in遍歷的對象必須是可迭代對象;
語法結構:
for 自定義變量 in 可迭代對象
循環體
for i in range(1,10):
print(i) # 循環的次數
輸出結果:
1
2
3
4
5
6
7
8
9
執行了10次,循環次數
for item in "Python":
print(item)
輸出結果:
P
y
t
h
o
n
如果在循環體中不需要自定義變量,可將自定義變量寫為下劃線 “_”;
for _ in range(5):
print('人生苦短,我用python')
輸出結果:
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
'''輸出100-999之間的水仙花數;
舉例:153=3**3+5**3+1**3
'''
for i in range(100,1000):
ge=i%10
shi=i//10%10
bai=i//100
# print(bai,shi,ge)
if ge**3+shi**3+bai**3==i:
print(i)
輸出結果:
153
370
371
407
break語句用來結束循環結構,通常與分支結構if一起使用;舉例用“for in”
# 從鍵盤錄入密碼,最多輸入三次,如果正確就結束循環;
for i in range(3): # 0 1 2
secret = int(input('請輸入密碼:'))
if secret==258096:
break
else:
print('密碼錯誤,請重新輸入!')
輸出結果:
請輸入密碼:123456
密碼錯誤,請重新輸入!
請輸入密碼:258096
舉例用while:
i=1 # 初始化變量
while i<3: # 條件判斷
secreat = int(input('請輸入密碼:')) # 條件執行體
if secreat==123456:
break
else:
print('密碼錯誤,請重新輸入')
i+=1 # 改變變量
輸出結果:
請輸入密碼:45689
密碼錯誤,請重新輸入
請輸入密碼:123456
用於結束當前循環,進入下一次循環通常與分支結構中的if一起使用;break是跳出當前循環
# 輸入1-50之間的所有的5的倍數
for i in range(1,51):
i*=5
if i>50:
break
else:
print(i)
我寫的:嘻嘻
輸出結果:
5
10
15
20
25
30
35
40
45
50
注意:在涉及到數字運算時要想到標准算數運算符!
for i in range(1,51):
if not bool(i%5):
print(i)
else:
continue
在視屏的啟發下寫的:嘻嘻 上面這個是錯誤的!,按照以下這樣寫:
for i in range(1,51):
if not bool(i%5):
print(i)
但是必須使用continue,那麼就要轉化種思路:什麼樣的數不是5的倍數
for i in range(1,51):-----
if i%5!=0: |
continue----------
print(i)
解釋:當i為1時,判斷1與5相除取余是否為0,不為0,continue,再到for i in range 循環判斷...直到為0輸出i
else語句:
與else語句配合使用的三種情況:
第一種情況:
if...:
...
else:
...
第二種情況:
while ...:
...
else:
...
第三種情況:
for ...:
...
else:
...
while 與 for使用在有break或continue時,沒有else
for i in range(3):
secret = int(input('請輸入密碼:'))
if secret==258096:
break
else:
print('密碼錯誤,請重新輸入!')
else:
print('對不起,三次密碼均輸入錯誤')
輸出結果:
請輸入密碼:123
密碼錯誤,請重新輸入!
請輸入密碼:456
密碼錯誤,請重新輸入!
請輸入密碼:4789
密碼錯誤,請重新輸入!
對不起,三次密碼均輸入錯誤
i=0
while i<=2:
pwd = int(input('請輸入密碼'))
if pwd == 123456:
break
else:
print('密碼錯誤')
i+=1
else:
print('對不起,均錯誤')
請輸入密碼123
密碼錯誤
請輸入密碼456
密碼錯誤
請輸入密碼789
密碼錯誤
對不起,均錯誤
循環結構中又嵌套了另外的完整的循環結構,其中內層循環作為外層循環的循環體執行
# 打印三行四列的矩形
'''
****
****
****
'''
for i in range(1,4): # 行數3行
for j in range(1,5): # 列數4列
print('*',end=' ') # 不換行輸出
print()
輸出結果:
* * * *
* * * *
* * * *
解釋:
1 2 3 4 j列
1 * * * *
2 * * * *
3 * * * *
i行
說明:當執行程序第一、二、三行時,i為1--j為1---打印 *
當執行程序第一、二、三行時,i為1--j為2---打印 * *
... * * * *
i為2--j為1---打印 * * * *
*
'''打印九九乘法表,首先試著先把直角三角形打印出來'''
# 打印直角三角形
for i in range(1,10): # 行數
for j in range(1,i+1): # 列數
print(str(i)+'*'+str(j)+'='+str(i * j),end=' ') # 不換行
print() # 換行
解釋:
執行第一行時,i=1,
執行第二行時,j在(1,2)取1
執行第三行時,不換行輸出第一行、第二行執行結果;為 *
執行第四行時,換行;* 之後換行,進行第二行的打印輸出;
i=2 第二行輸出
j(1,3)---j=1,j=2 第二行的第一列與第二列
不換行輸出--* *
換行輸出* *,進行第三行...
輸出結果:
1x1=1
2x1=2 2x2=4
3x1=3 3x2=6 3x3=9
4x1=4 4x2=8 4x3=12 4x4=16
5x1=5 5x2=10 5x3=15 5x4=20 5x5=25
6x1=6 6x2=12 6x3=18 6x4=24 6x5=30 6x6=36
7x1=7 7x2=14 7x3=21 7x4=28 7x5=35 7x6=42 7x7=49
8x1=8 8x2=16 8x3=24 8x4=32 8x5=40 8x6=48 8x7=56 8x8=64
9x1=9 9x2=18 9x3=27 9x4=36 9x5=45 9x6=54 9x7=63 9x8=72 9x9=81
用於控制本層循環;
break跳出本層循環,不影響後續的程序運行;continue
以下舉例沒看懂:
for i in range(5): # 循環次數0-4 5次
for j in range(1,11):---------
if j%2==0: |----
break |----內循環,輸出的內容
print(j,end=' ')----------
print()
1
1
1
1
1
沒看懂在j取(1-10),為什麼在這裡是1與2!
for i in range(5):
for j in range(1,11):<----
if j%2==0: |
continue----------
print(j,end=' ')
print()
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
總結:循環結構中的while用於次數不固定的循環,初始條件不成立,一次都執行;for in用於遍歷可迭代對象;
break結束當前循環結構;continue結束當前循環進入下一次循環;
變量可以存儲一個元素,而列表可以存儲N多個元素,程序可以方便的對這些數據進行整體性操作;列表相當於其他語言中的數組
書包---列表 書本、筆盒...---對象
lst = ['hello','world',89]
print(id(lst))
print(type(lst))
print(lst)
輸出結果:
2625645986112
<class 'list'>
['hello', 'world', 89]
解釋:
lst 的id是112,類型是列表,value是'hello','world',89
那麼,每一個對象也都有id,type,value
'''創建列表的第一種方式---中括號[],元素之間用英文逗號相隔'''
lst = ['hello','world',90]
'''創建列表的第二種方式---使用內置函數list()'''
lst1 = list(['hello','world',90])
解釋:內存示意圖
-------->|hello(id,type,value)
(id,type,value)lst------->|world(id,type,value)
------->|90(id,type,value)
空列表創建:
lst=[]
lst=list() 與lst=list([]) 輸出一樣,但id不一樣
列表元素按順序有序排序;
索引映射唯一一個數據
索引 -7 -6 -5 -4 -3 -2 -1
數據 'hello' 'world' 123 88.6 'world' 125 world
索引 0 1 2 3 4 5 6
列表可以存儲重復數據;
任意數據類型混存;
根據需要動態分配和回收內存
(元素-->索引)
lst = ['hello','world',98,'hello']
# 查詢列表中存在N個相同元素,默認只返回相同元素的第一個元素
print(lst.index('hello')) # 輸出結果0
# 如果查詢的元素在列表中不存在,則會報錯
# print(lst.index('99')) # ValueError
# 在指定的start與stop之間尋找
print(lst.index('hello',1,4)) # 1-4 不包括4 輸出結果3
獲取列表中的單個元素:索引---->元素
正向索引從0到N-1
逆向索引從-N到-1
指定的索引不存在,IndexError
lst = ['hello','world',98,'hello','wwe',789]
# 獲取索引為2的元素
print(lst[2]) # 98
# 獲取索引為-3的元素
print(lst[-3]) # hello
# 獲取的索引元素超出范圍
# print(lst[-10]) # IndexError
獲取列表中的多個元素:切片
語法格式:
列表名[start : stop : step]
切片操作:
切片的結果----原列表切片的拷貝
切片范圍:(start : stop) 前包後不包
step 默認為1,簡寫(start : stop)
step 為正數:
( : stop : step) 切片的第一個元素默認是列表的第一個元素
(start : : step) 切片的最後一個元素默認是列表的最後一個元素
(從start開始往後計算切片)
lst = [10,20,30,40,50,60,70,80,90]
# start=1,stop=6(不包括索引6的元素),step=1
print('原列表',id(lst))
lst1 = lst[1:6:1] # 默認步長為1,lst[1:6:]
print(lst1)
print('切片後:',id(lst1))
print(lst[1:6]) # 默認步長為1
print(lst[1:6:])
print(lst[1:6:2])
print(lst[:6:2])
print(lst[1::2]) # 從索引為1的到列表元素最後
輸出結果:
原列表 1878149972288
[20, 30, 40, 50, 60]
切片後: 1878149975552
[20, 30, 40, 50, 60]
[20, 30, 40, 50, 60]
[20, 40, 60]
[10, 30, 50]
[20, 40, 60, 80]
step為負數:
( : stop:step ) 切片的第一個元素默認是列表的最後一個元素
(start ::step) 切片的最後一個元素默認是列表中的第一個元素
(從stop開始往前計算切片)
舉例:
lst = [10,20,30,40,50,60,70,80,90]
print('------step為負數-----')
print('原列表',lst)
print(lst[::-1])
print(lst[7::-1])
print(lst[6:0:-2])
輸出結果:
------step為負數-----
原列表 [10, 20, 30, 40, 50, 60, 70, 80, 90]
[90, 80, 70, 60, 50, 40, 30, 20, 10]
[80, 70, 60, 50, 40, 30, 20, 10]
[70, 50, 30]
遍歷:將列表中的元素依次輸出。
判斷指定元素在列表中是否存在---in與not in
元素 in 列表名
元素 not in 列表名
舉例:
lst = [10,20,'python','world']
print(10 in lst)
print('hello' not in lst)
輸出結果:
True
True
列表元素的遍歷:
for 迭代變量 in 列表名: # 目前學習的可迭代對象有列表與字符串。
操作
lst = [10,20,'python','world']
for i in lst:
print(i)
輸出結果:
10
20
python
world
列表元素添加:
append():在列表末尾添加一個元素
# 在列表末尾添加一個元素
lst=[123,'rrt','hello',99]
print('原列表',id(lst))
lst.append(100)
print('添加後的列表',lst,id(lst))
# lst2=['hello','world']
# lst.append(lst2) # 將lst2作為整個列表加在lst裡的最後一個元素後面
# print(lst) # [123, 'rrt', 'hello', 99, 100, ['hello', 'world']]
輸出結果:
原列表 1503804080448
添加後的列表 [123, 'rrt', 'hello', 99, 100] 1503804080448
[123, 'rrt', 'hello', 99, 100, ['hello', 'world']]
extend():在列表元素末尾以此添加多個元素
# 在列表末尾至少添加一個元素--extend()
lst=[123,'rrt','hello',99,100]
lst2=['hello','world']
lst.extend(lst2) # 將lst2裡的元素分別加在lst元素後面
print(lst) # [123, 'rrt', 'hello', 99, 100, 'hello', 'world']
輸出結果:
[123, 'rrt', 'hello', 99, 100, 'hello', 'world']
insert():通過索引在列表的任意位置添加一個元素
lst = ['hello','world',99,23,'pwd']
lst.insert(2,'不要學我') # 在指定所以之前添加元素
print(lst)
輸出結果:
['hello', 'world', '不要學我', 99, 23, 'pwd']
切片:在列表的任意位置添加至少一個元素
lst=['hello', 'world', '不要學我', 99, 23, 'pwd']
lst2=[True,False,'hello']
lst[3:]=lst2 # 索引為3(包括)切開之後的不要,加上lst2的
print(lst)
輸出結果:
['hello', 'world', '不要學我', True, False, 'hello']
列表元素刪除:remove()、pop()、切片、del
remove():根據元素刪除
一次刪除一個指定元素;
lst = [10,20,10,20,50,60,30]
lst.remove(50)
print(lst)
輸出結果:
[10, 20, 10, 20, 60, 30]
重復元素只刪除第一個;
lst = [10,20,10,20,50,60,30]
lst.remove(20)
print(lst)
輸出結果:
[10, 10, 20, 50, 60, 30]
元素不存在的話ValueError
lst = [10,20,10,20,50,60,30]
lst.remove(70)
print(lst)
輸出結果:
ValueError: list.remove(x): x not in list
pop():根據索引刪除
刪除一個指定索引位置上的元素
lst = [10,20,10,20,50,60,30]
lst.pop(0)
print(lst)
輸出結果:
[20, 10, 20, 50, 60, 30]
不指定索引,默認刪除列表中中最後一個元素
lst = [10,20,10,20,50,60,30]
lst.pop()
print(lst)
輸出結果:
[10, 20, 10, 20, 50, 60]
指定索引不存在,ValueError
切片:一次至少刪除一個元素,將產生一個新的列表元素
# 刪除至少一個元素,產生一個新的列表對象
lst = [10,20,10,20,50,60,30]
new_lst = lst[1:3]
print('原列表',id(lst),lst)
print('新列表',id(new_lst),new_lst)
# 不產生新的列表,而是刪除原有列表中的內容
lst[1:3]=[]
print(lst,id(lst))
輸出結果:
原列表 2727795245376 [10, 20, 10, 20, 50, 60, 30]
新列表 2727795190080 [20, 10]
[10, 20, 50, 60, 30] 2727795245376
clear():清楚列表中的所有元素
lst = [10,20,10,20,50,60,30]
lst.clear()
print(lst)
輸出結果:
[]
del:刪除列表
列表元素修改:
為指定索引的元素賦予一個新值(一次修改一個值)
lst = [10,20,10,20,50,60,30]
lst[5]=200
print(lst)
輸出結果:
[10, 20, 10, 20, 50, 200, 30]
為指定的切片賦予一個新值(賦予多個新值)
lst = [10,20,10,20,50,60,30]
lst[:4]=[100,200,100]
print(lst)
輸出結果:
[100, 200, 100, 50, 60, 30]
列表元素排序:
1.調用sort()方法,列表中的所有元素默認按照從小到大(升序)順序進行排序,可以指定reverse=True,進行降序排序;
lst = [20,50,98,69,45,60,30]
print('排序前:',lst,id(lst))
lst.sort() # 默認升序,reverse=False
print('排序後:',lst,id(lst))
lst.sort(reverse=True) # 降序
print('再排序後:',lst,id(lst))
輸出結果:
排序前: [20, 50, 98, 69, 45, 60, 30] 1996126241088
排序後: [20, 30, 45, 50, 60, 69, 98] 1996126241088
再排序後: [98, 69, 60, 50, 45, 30, 20] 1996126241088
2.調用內置函數sorted()升序,可以指定reverse=True,進行降序排序,原列表不發生變化;(產生一個新的列表對象)
lst = [20,50,98,69,45,60,30]
print('排序前:',lst,id(lst))
lst1=sorted(lst) # 默認升序,reverse=False
print('排序後:',lst1,id(lst1))
jixu=sorted(lst,reverse=True) # 降序
print('再排序後:',jixu,id(jixu))
輸出結果:
排序前: [20, 50, 98, 69, 45, 60, 30] 2350573895936
排序後: [20, 30, 45, 50, 60, 69, 98] 2350576623040
再排序後: [98, 69, 60, 50, 45, 30, 20] 2350573896512
語法格式:
[i*i for i in range(1,10)]
i*i 表示列表元素的表達式;
i 自定義變量
range(1,10) 可迭代對象
# 注意事項:“表示列表元素的表達式”中通常包含自定義變量
舉例:
lst = [i for i in range(1,10)] # 將1-9的序列賦值給i,在以列表的格式輸出
print(lst)
輸出結果:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
輸入2 4 6 8 10的列表
lst = [i*2 for i in range(1,6)] # 將1-9的序列賦值給i,在以列表的格式輸出
print(lst)
輸出結果:
[2, 4, 6, 8, 10]
是python內置的數據結構之一,與列表一樣是一個可變序列(數據結構可執行增刪改操作);不可變序列:整數、字符串(不進行增刪改操作)
以鍵值對的方式存儲數據,字典是一個無序的序列;鍵不可重復。
實現原理:數據在字典中存儲的時候會進行哈希算法,將key進行哈希計算存儲位置,所以key必須是一個不可變序列,根據key查找value所在的位置
1.使用花括號{}
score = {'張三':100,'李四':98,'王五':45}
空字典:
dcc = {}
2.使用內置函數dict()
dic(name='jack',age=20)
字典中元素的獲取:根據鍵獲取值
1.[] 舉例:score['張三']
2.get()方法 舉例:score.get('張三',66)# 如果張三不存在則返回默認值66
二者取值的區別:
[]如果字典中不存在指定的key,拋出keyError異常
get()方法取值,如果字典中不存在指定的key,並不會拋出KeyError,而是返回None,可以通過參數設置默認的value,以便指定的key不存在返回
key值判斷:
in 指定的key在字典中存在返回True;
not in 指定的key在字典中不存在返回True
score = {'張三':100,'李四':98,'王五':45}
print('張三' in score)
print('張三' not in score)
輸出結果:
True
False
獲取字典視圖的三種方法:
1.keys()----獲取字典中所有的key
score = {'張三':100,'李四':98,'王五':45}
key = score.keys()
print(key)
print(type(key))
print(list(key))
輸出結果:
dict_keys(['張三', '李四', '王五'])
<class 'dict_keys'>
['張三', '李四', '王五']
2.values()-----獲取字典中所有的value
score = {'張三':100,'李四':98,'王五':45}
value = score.values()
print(value)
print(type(value))
輸出結果:
dict_values([100, 98, 45])
<class 'dict_values'>
3.items()------獲取字典中所有的key,value對
score = {'張三':100,'李四':98,'王五':45}
ii = score.items()
print(ii)
print(type(ii))
輸出結果:
dict_items([('張三', 100), ('李四', 98), ('王五', 45)])
<class 'dict_items'>
字典元素的遍歷:
for item in score:# 獲取的是鍵,其中item是自定義變量
print(item)
score = {'張三':100,'李四':98,'王五':45}
for item in score:
print(item) # 獲取的是鍵
輸出結果:
張三
李四
王五
score = {'張三':96,'李四':100,'麻七':100}
for item in score:
# print(item)
# print(score[item]) 根據key獲取vlaue
print(score.get(item))
輸出結果:
96
100
100
字典元素的刪除:
del score['張三']
score.clear() # 清空字典中的元素 {}
score = {'張三':100,'李四':98,'王五':45}
del score['張三'] # 刪除指定的鍵值對
print(score)
輸出結果:
{'李四': 98, '王五': 45}
字典元素的新增:
score['jack']=90
也可以修改元素的值:score['李四']=60
score = {'張三':100,'李四':98,'王五':45}
score['小二'] = 90
print(score)
輸出結果:
{'張三': 100, '李四': 98, '王五': 45, '小二': 90}
字典的特點:
1.字典中的所有元素都是一個key-value對,key不可以重復,value可以重復;
2.字典中的元素是無序的;
3.字典中的key必須是不可變對象;
4.字典也可以根據需要動態地伸縮
5.字典會浪費較大的內存,是一種使用空間換時間的數據結構
字典生成式:
內置函數zip():用於將可迭代的對象(可以使用for in循環遍歷的對象)作為參數,將對象中對應的元素打包成一個元組,然後返回由這些元組組成的列表
items = ['Fruits','Book','Other']
prices = [96,78,85]
zz = zip(items,prices)
print(list(zz))
輸出結果:
[('Fruits', 96), ('Book', 78), ('Other', 85)]
tool = ['Fruits','Book','Others']
prace = [98,56,78]
di={kes:vaus for kes,vaus in zip(tool,prace)}
print(di)
輸出結果:
{'Fruits': 98, 'Book': 56, 'Others': 78}
items = ['Fruits','Book','Other']
prices = [96,78,85]
pz={items.upper():prices for items,prices in zip(items,prices)}
# 解釋:
items.upper():prices
items,prices
zip(items,prices)
print(pz)
輸出結果:
{'FRUITS': 96, 'BOOK': 78, 'OTHER': 85}
python內置的數據結構之一,是一個不可變序列;
不可變序列與可變序列:
不可變序列:字符串、元組(沒有增刪改操作)
'''不可變序列:字符串,元組...內存地址在增刪改之後發生變化'''
s = '哈哈'
s1 = s+'hello'
print(s,id(s)) # 2426108766224
print(s1,id(s1)) # 2426108766416
輸出結果:
哈哈 2426108766224
哈哈hello 2426108766416
可變序列:列表、字典(可以對序列執行增刪改操作,對象地址不發生更改)
'''可變序列:列表,字典...內存地址在增刪改之後沒發生變化'''
lst = [50,'hello',56,80]
print(lst,id(lst)) # 1847814275392
lst.append(99)
print(lst,id(lst)) # 1847814275392
輸出結果:
[50, 'hello', 56, 80] 1847814275392
[50, 'hello', 56, 80, 99] 1847814275392
tup = ('python','world',90)
print(tup,type(tup))
tup1 = tuple(('python','world',90))
print(tup1,type(tup1))
輸出結果:
('python', 'world', 90) <class 'tuple'>
('python', 'world', 90) <class 'tuple'>
# 注意
tup = ('python','world',90) # 也可以寫成tup='python','world',90
如果是一個元素,比如:tt = ('poop'),輸出的類型是str,所以“只包含一個元組的元素需要使用逗號和小括號” ,逗號不能省略!!!
tt=('poop')
print(tt,type(tt)) # poop <class 'str'>
tt=('poop',)
print(tt,type(tt)) # ('poop',) <class 'tuple'>
# 創建空元組
tt=()
tt=tuple()
# 創建空字典
dd={}
dd=dic()
元組是可迭代對象,所以可以使用for...in進行遍歷(走一遍)
ttp=('python',980,'world')
print(ttp[0]) # 獲取元組方式
for i in ttp:
print(i)
輸出結果:
python
python
980
world
集合是什麼:
Python語言提供的內置數據結構;
與列表、字典一樣都屬於可變類型(增刪改查)的序列;
集合是沒有value的字典;
向集合裡放數據元素會通過哈希函數計算存儲位置,所以第一個放進的元素未必在第一位。(集合元素是無序的)
集合的創建方式:
1.直接{} s={'python','hello',90},存儲單個元素,不允許重復.
s={6,6,7,4,5,6,4,3,4,3} # 將重復元素去掉
print(s)
輸出結果:
{3, 4, 5, 6, 7}
2.使用內置函數
s = set(range(6))
print(s) # {0, 1, 2, 3, 4, 5}
s = set([2,5,6,2,4,6,3,2])
print(s,type(s)) # {2, 3, 4, 5, 6} <class 'set'>
s = set((34,6,78,90))
print(s,type(s)) # {78, 34, 90, 6} <class 'set'>
s = set('python')
print(s,type(s)) # {'y', 'o', 'p', 'n', 'h', 't'} <class 'set'>
s = set({34,56,78,11,22,22})
print(s,type(s)) # {34, 22, 56, 11, 78} <class 'set'>
s = set() # 定義一個空集合,如果是s={}的話數據類型是字典!
print(s,type(s)) # set() <class 'set'>
集合元素的判斷操作:in或not in
s = {1,2,5,9,80,100}
print(1 in s)
print(100 not in s)
True
False
集合元素的新增操作:
1.調用add()方法,一次添加一個元素
2.調用update()方法至少添加一個元素
s = {1,2,5,9,80,100}
s.add(12)
print(s) # {1, 2, 100, 5, 9, 12, 80}
s = {1,2,5,9,80,100}
s.update({300,20,800,70})
print(s) # {800, 1, 2, 100, 5, 70, 9, 300, 80, 20}
s = {1,2,5,9,80,100}
s.update(['op',78,66])
print(s) # {1, 2, 'op', 100, 5, 66, 9, 78, 80}
s = {1,2,5,9,80,100}
s.update((65,88,99,'oh'))
print(s) # {1, 2, 65, 100, 5, 99, 9, 80, 88, 'oh'}
集合元素的刪除操作:
調用remove()方法,一次刪除一個指定的元素,如果指定的元素不存在拋出keyerror;
s = {1,2,5,9,80,100}
s.remove(100)
print(s) # {1, 2, 5, 9, 80}
s = {1,2,5,9,80,100}
s.remove(90)
print(s) # KeyError
調用discard()方法,一次刪除一個指定的元素,如果指定的元素不存在不拋出異常;
s = {1,2,5,9,80,100}
s.discard(90)
print(s) # {1, 2, 100, 5, 9, 80} 有就刪除,沒有不報錯
調用pop()方法,一次只刪除一個任意的元素;
s = {1,2,5,9,80,100,11}
s.pop() # 不能添加參數,規定無參;TypeError
print(s) # {2, 100, 5, 9, 11, 80}
調用clear()方法,清空集合;
s = {1,2,5,9,80,100,11}
s.clear() #無參,清空
print(s) # set()
兩個集合是否相等:可以使用運算符==或!=進行判斷
s1={10,20,30,40}
s2={40,30,10,20}
print(s1==s2) # True
print(s1!=s2) # False
集合裡的元素是無序列,輸出的順序不會決定存儲順序(元素內容相同集合即可)
一個集合是否是另一個集合的子集:可以調用方法issubset進行判斷;B是A的子集
s1={10,20,30,40}
s2={40,30,10,20,60,100}
s3={10,20,30,90,100}
se=s1.issubset(s2)
see=s3.issubset(s1)
print(se) # True
print(see) # False
一個集合是否是另一個集合的超集:可以調用方法issuperset進行判斷;A是B的超級
s1={10,20,30,40}
s2={40,30,10,20,60,100}
s3={10,20,30,90,100}
se=s2.issuperset(s1)
see=s2.issuperset(s3)
print(se) # True
print(see) # False
兩個集合是否沒有交集:可以調用方法isdisjoint進行判斷
s1={10,20,30,40}
s2={40,30,10,20,60,100}
s3={400,500,45}
se=s2.isdisjoint(s1)
see=s2.isdisjoint(s3)
print(se) # Flase 有交集為flase
print(see) # True 無交集為True
集合的數學關系:
交集:
s1={50,45,89,40,10}
s2={40,89,50,10,30}
print(s1.intersection(s2))
print(s1 & s2) # intersection()與&都是交集操作
輸出結果:
{40, 89, 10, 50}
{40, 89, 10, 50}
並集:
s1={50,45,89,40,10}
s2={40,89,50,10,3099,66}
print(s1.union(s2))
print(s1 | s2) # union()與|都是並集操作
輸出結果:
{66, 40, 10, 45, 50, 89, 3099}
{66, 40, 10, 45, 50, 89, 3099}
差集:
s1={50,45,89,40,10}
s2={40,89,50,10,3099,66}
print(s1.difference(s2)) # s1-s2 {45}
print(s2.difference(s1)) # s2-s1 {66, 3099} 在s2的集合裡將s1的元素全部去掉
print(s1 - s2) # difference()與-都是差集操作
輸出結果:
{45}
{45}
對稱差集:
s1={50,45,89,40,10}
s2={40,89,50,10,3099,66}
print(s1.symmetric_difference(s2)) # 去掉相同的元素,余留下來的元素
print(s1 ^ s2) # symmetric_difference()與^都是對稱差集操作
輸出結果:
{66, 3099, 45}
{66, 3099, 45}
用於生成集合的公式:
{i*i for i in range(10)}
i*i表示集合元素的表達式
i自定義變量
range(10)可迭代對象(迭代:輪流代替)、
將{}修改為[]就是列表生產式
沒有元組生成式,因為元組是不可變數據類型;
sett = {i*i for i in range(10)} # for i in range(10) 默認0-9
print(sett) # 集合元素是無序的
輸出結果:
{0, 1, 64, 4, 36, 9, 16, 49, 8125}
列表、字典、元組、集合總結
字符串:在python中字符串是基本數據類型,是一個不可變的字符序列;
a='python'
aa="python"
aaa='''python'''
print(a,id(a))
print(a,id(aa))
print(a,id(aaa))
輸出結果:
python 1481882442352
python 1481882442352
python 1481882442352
解釋:
創建aa字符串的時候,發現存儲中有相同的字符串,不會再開辟新的存儲空間,而是把該字符的地址付給新創建的變量。
字符串的駐留機制:僅保存一份相同的且不可變的字符串方法,不同的值被存放在字符串的駐留池中,python的駐留機制對相同的字符串只保存一份拷貝,後續創建相同字符串時,不會開辟新空間,而是把該字符的地址賦給新創建的變量。
駐留機制的幾種情況(交互模式):
字符串的長度為0或1時;
>>> s1='' # 字符長度為0
>>> s2=''
>>> s1 is s2
True
>>> s1='%' # 字符長度為1
>>> s2='%'
>>> s1 is s2
True
符合標識符的字符串(字母,數字,下滑線);
>>> s1='abc%' # 不符合字符串
>>> s2='abc%'
>>> s1==s2
True
>>> s1 is s2
False
>>> id(s1)
2277190557360 ----------- 內存地址不一樣!
>>> id(s2)
2277190557424 -----------
>>> s1='abcx'
>>> s2='abcx'
>>> s1==s2
True
>>> s1 is s2 ---------內存地址一樣!
True
字符串只在編譯時進行駐留,而非運行時;
>>> a='abc'
>>> b='ab'+'c' # b的值在連接之前就完成了
>>> c=''.join(['ab','c']) # c是程序運行的時候對列表中的數據進行連接的
>>> a is b
True
>>> a is c
False ----------------注意這裡!!!
>>> c
'abc'
>>> type(c)
<class 'str'>
>>> type(a)
<class 'str'>
[-5,256]之間的整數數字;
>>> a=-5
>>> b=-5
>>> a is b
True
>>> a=-6
>>> b=-6
>>> a is b
False
sys中的inter方法強制2個字符串指向同一個對象;
>>> import sys
>>> a='abc%'
>>> b='abc%'
>>> a is b
False
>>> a=sys.intern(b)
>>> a is b
True
pycharm對字符串進行了優化處理;
字符串駐留機制的優缺點:
當需要值相同的字符串時可以直接從字符串池裡拿來使用,避免頻繁的創建和銷毀,提升雄安率和節約內存,因此拼接字符串和修改字符串是會比較影響性能的;
在需要進行字符串拼接時建議使用str類型的join方法,而非+join()方法是先計算出所有字符串的長度,然後再拷貝,只new一次對象,效率要比“+”效率高。
查詢操作方法:
兩者的區別就是:找不到出現的位置時,報錯結果不一樣;
s='hello,hello'
print(s.index('lo'))
print(s.rindex('lo')) # 逗號也是一個索引值
輸出結果:
3
9
s='hello,hello'
print(s.find('p'))
print(s.rfind('lo'))
輸出結果:
-1
9
解釋:
大小寫轉換操作的方法:
s='hello,python'
a=s.upper()
print(a,id(a))
print(s,id(s))
輸出函數:
HELLO,PYTHON 1845603946160
hello,python 1845603572336
解釋:字符串是不可變數據類型,轉換成大寫內存位置不一樣,開辟了另一個存儲空間,產生新的字符串對象。
s='hello,python'
a=s.lower() # 轉換之後會產生一個新的字符串對象
print(a,id(a))
print(s,id(s))
print(a==s)
print(a is s) # 內存位置不一致;
輸出結果:
hello,python 2168620011248
hello,python 2168619974384
True
False
s2='hello,Python'
print(s2.swapcase()) # HELLO,pYTHON
print(s2.title()) # Hello,Python
print(s2.capitalize()) # Hello,python
內容對齊操作的方法:
s='hello,python'
print(s.center(20,'*')) # ****hello,python****
print(s.ljust(20,"*")) # hello,python********
print(s.center(10,'*')) # hello,python
print(s.center(20))
輸出結果:
****hello,python****
hello,python********
hello,python
hello,python
print(s.rjust(20,'*'))
print(s.rjust(20))
print(s.ljust(10,'*'))
輸出結果:
********hello,python
hello,python
hello,python
print(s.zfill(20))
print(s.zfill(10))
print('-8901'.zfill(8))
輸出結果:
00000000hello,python
hello,python
-0008901
劈分操作的方法:
s='hello world Python'
lst=s.split()
print(lst)
輸出結果:
['hello', 'world', 'Python']
s1='hello|world|python'
lst1=s1.split(sep='|')
print(lst1)
輸出結果:
['hello', 'world', 'Python']
s1='hello|world|python'
lst1=s1.split(sep='|',maxsplit=1)
print(lst1)
輸出結果:
['hello', 'world|python']
s='hello world Python'
lst=s.rsplit()
print(lst)
輸出結果:
['hello', 'world', 'Python']
s1='hello|world|python'
lst1=s1.rsplit('|')
print(lst1)
輸出結果:
['hello', 'world', 'python']
s1='hello|world|python'
lst1=s1.rsplit(sep='|',maxsplit=1)
print(lst1)
輸出結果:
['hello|world', 'python']
判斷字符串操作的方法
s='hello,python'
print(s.isidentifier()) # False
print( 'hello'.isidentifier()) # True
print('張三_'.isidentifier()) # True
print('張三_123'.isidentifier()) # True
print('\t'.isspace()) # True
print('abc'.isalpha()) # True
print('張三'.isalpha()) # True
print('張三1'.isalpha()) # Flase
print('123'.isdecimal()) # True
print('123四'.isdecimal()) # Flase
print('ⅡⅡⅡ'.isdecimal()) # Flase
print('123'.isnumeric()) # True
print('123四'.isnumeric()) # True
print('ⅡⅡⅡ'.isnumeric()) # True
print('abc1'.isalnum()) # True
print('張三123'.isalnum()) # True
print('abc!'.isalnum()) # False
字符串操作的其它方法
s='hello,Python'
print(s.replace('Python','java'))
s1='hello,Python,Python,Python'
print(s1.replace('Python','java'))
print(s1.replace('Python','java',2))
輸出結果:
hello,java
hello,java,java,java
hello,java,java,Python
lst=['hello','java','python']
print('|'.join(lst))
輸出結果:
hello|java|python
lst=['hello','java','python'] -----列表
print(' '.join(lst))
輸出結果:
hello java python
tup=('hello','java','python') -------元組
print(' '.join(tup))
輸出結果:
hello java python
print('*'.join('python'))
輸出結果:
p*y*t*h*o*n
字符串的比較操作:
運算符:>,<=,<,<=,==,!=
比較規則:首先比較兩個字符串中的第一個字符,如果相等則繼續比較下一個字符,以此比較下去,直到兩個字符串中的字符不相等時,其比較結果就是兩個字符串的比較結果,兩個字符串中的所有後續字符將不再被比較;
比較原理:兩個以上字符進行比較時,比較的是其ordinal value(原始值),調用內置函數ord可以得到指定字符的ordinal value。與內置函數ord對應的是內置函數chr,調用內置函數chr時指定ordinal value可以得到其對應的字符。
print('apple'>'app') # True
print('apple'>'banana') # False
print(ord('a'),ord('b')) # 獲取字符的原始值 97 98
print(ord('馬')) # 39532
print(chr(97),chr(98)) # 獲得原始值所對應的字符 a b
print(chr(39532)) # 馬
== 比較的是value;is比較的是id(內存地址)是否相等
a=b='python'
c='python'
print(a==b) # True
print(b==c) # True
print(a==c) # True
print(a is b) # True
print(a is c) # True
print(b is c) # True
print(id(a)) # True 1920823049840
print(id(c)) # True 1920823049840
print(id(a)) # True 1920823049840
字符串是不可變類型,不具備增刪改操作,切片操作將產生新的對象
切片:
[start:end:step] 步長是以索引為單位的
s='hello,python'
s1=s[:5] # 由於沒有指定起始位置,默認從索引值0
s2=s[6:]
s3='!'
ss=s1+s3+s2
print(s1)
print(s2)
print(ss)
print(id(s1),type(s1))
print(id(s2),type(s2))
print(id(s3),type(s3))
print(id(ss),type(ss))
輸出結果:
hello
python
hello!python
2858431575024 <class 'str'>
2858431575088 <class 'str'>
2858431526000 <class 'str'>
2858431575152 <class 'str'>
s='hello,python'
print(s[1:5:1]) # ello 從索引為1開始到索引為5,不包含索引為5的,步長為1;
print(s[::2]) # 索引為0,2,4,6,8,10
# hlopto
print(s[::-1]) # 輸出:nohtyp,olleh
# 默認從從字符串的最後一個元素開始,到字符串的第一個元素
print(s[-6::1]) # python
字符串的拼接格式
兩種方式:
%作占位符,%s:字符串,%i或%d:整數,%f:浮點數。
# %做占位符
name='張三'
age=3
print('我叫%s,今年%d歲' % (name,age))
輸出結果:
我叫張三,今年3歲
{}作占位符,
# {}做占位符
name='張三'
age=3
print(f'我叫{name},今年{age}歲')
# f-string格式
print('我叫{0},今年{1}歲'.format(name,age))
輸出結果:
我叫張三,今年3歲
我叫張三,今年3歲
表示的精度和寬度
print('%10d' % 66) # 10 表示的是寬度
輸出結果:
66
print('%f' % 3.1415926)
print('%.3f' % 3.1415926)
print('%10.3f' % 3.1415926) # 寬度為10,精度為小數點後3位
輸出結果:
3.141593
3.142
3.142
print('{0}'.format(3.1415926))
輸出結果:
3.1415926
print('{0:.3}'.format(3.1415926)) # 表示總共3位數
輸出結果:
3.14
print('{0:.3f}'.format(3.1415926))
輸出結果:
3.142
print('{0:10.3f}'.format(3.1415926)) # 寬度為10位,保留三位小數
輸出結果:
3.142
為什麼需要字符串的編解碼
編碼與解碼的方式
編碼:將字符串轉化為二進制數據(bytes)
解碼:將bytes類型的數據轉化成字符串類型
# 編碼格式
s='天涯共此時'
print(s.encode(encoding='gbk')) # 在gbk這種編碼格式中一個中文占2個字節
print(s.encode(encoding='utf-8')) # 在utf-8這種編碼格式中一個中文占3個字節
輸出結果:
b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1'
b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6'
# 解碼格式
byte=s.encode(encoding='gbk')
print(byte.decode(encoding='gbk')) # byte代表的是二進制數據
輸出結果:
天涯共此時
byte=s.encode(encoding='utf-8')
print(byte.decode(encoding='utf-8')) # byte代表的是二進制數據
輸出結果:
天涯共此時
函數的定義:函數就是執行特定任務和以完成特定功能的一段代碼(搾汁機);
為什麼使用函數:復用代碼,隱藏實現細節,提高可維護性,提高可讀性便於調試;
函數的創建:
1 def 函數名 ([輸入參數]): # 函數名符合標識符的規范自命名
2 函數體 # 實現功能
3 [return xxx] # 接收結果的容器(變量)
4 def calc(a,b):
5 c=a+b
6 return c # 結束函數體並將結果提交,提交給函數的調用處
7 res = calc(99,999) # 調用
8 print(res)
輸出結果:
1098
解釋:
當執行在第7行的時候,將值賦值給a與b輸出的結果給調用處打印輸出
形式參數(形參)
def calc(a,b): # a,b稱為形式參數,形式參數在函數的定義處
實際參數(實參)
res = calc(99,999) # 10,20稱為實參,實參在函數的調用處
函數調用的參數傳遞方式:
位置實參:根據形參對應的位置進行實參傳遞
res = calc(99,999)
關鍵字實參:根據形參名稱進行實參傳遞
res = calc(b=999,a=99) # 等號左側的字母稱為關鍵字參數
函數參數傳遞調用的內存分析:
傳參的可變對象與不可變對象
# 定義函數
def fun(arg1,arg2):
print('arg1',arg1)
print('arg2',arg2)
arg1=100
arg2.append(10)
print('arg1', arg1)
print('arg2', arg2)
# 調用函數
n1=11
n2=[90,50,78]
print('n1',n1)
print('n2',n2)
fun(n1,n2) # 位置傳參,實參名稱可以與形參名稱不一致
print('n1',n1) # n1=11,
print('n2',n2)
'''在函數調用的過程中,進行參數的傳遞
如果是不可變對象n1,在函數體的修改不會影響實參的值,arg1的值改為100,不會影響;
如果是可變對象n2,在函數體的修改下會影響實參的值,arg2的列表中append(10),會影響n2的值'''
輸出結果:
n1 11
n2 [90, 50, 78]
arg1 11
arg2 [90, 50, 78]
arg1 100
arg2 [90, 50, 78, 10]
n1 11
n2 [90, 50, 78, 10]
函數的返回值:
1.如果函數沒有返回值(函數執行完畢之後,不需要給調用處提供數據),return可以省略不寫;
def fun1():
print('hello')
return # 可以省略不寫
fun1()
輸出結果:
hello
2.函數的返回值如果是1個,直接返回原類型
def fun1():
return 'hello'
stt=fun1()
print(stt)
輸出結果:
hello
3.函數的返回值,如果是多個,返回的結果為元組
def fun2():
return 'hello','python'
print(fun2())
輸出結果:
('hello', 'python')
# 不能嚴格按照函數結構寫
# 定義函數
def fun(num):
odd=[] # 存奇數
even=[] # 存偶數
for i in num:
if i%2: # 奇數為1,布爾值為True
odd.append(i)
else:
even.append(i)
return odd,even
lst=[10,55,88,98,78,56,69,33]
print(fun(lst))
輸出結果:
([55, 69, 33], [10, 88, 98, 78, 56])
默認值參數:
'''
函數定義默認值參數:函數定義時,給形參設置默認值,只有與默認值不符的時候才需要傳遞實參
'''
def funn(a,b=10):
print(a,b)
funn(100) # 只傳一個參數,b采用默認值
funn(10,20) # 20將默認值替換
輸出結果:
100 10
10 20
個數可變的位置參數:
定義函數時,可能無法事先確定傳遞的位置實參的個數時,使用可變的位置參數;使用*定義個數可變的位置形參;結果為一個元組
def fun(*args): # 只能是一個參數,args是一個自定義參數
print(args)
fun(10)
fun(10,20)
fun(10,30,50)
輸出結果:
(10,)
(10, 20)
(10, 30, 50)
個數可變的關鍵字形參:
定義函數時,無法事先確定傳遞的關鍵字實參的個數時,使用可變的關鍵字形參;使用**定義個數可變的關鍵字形參;結果為一個字典
def fun(**args): # 只能是一個參數
print(args)
fun(a=10)
fun(a=10,b=20)
fun(a=10,b=30,c=50)
輸出結果:
{'a': 10}
{'a': 10, 'b': 20}
{'a': 10, 'b': 30, 'c': 50}
在一個函數定義過程中,既有個數可變關鍵字形參,也有個數可變位置形參,個數可變的位置形參就在個數可變的關鍵字形參之前!這樣就不會報錯;
函數的參數總結:
函數調用時的參數傳遞:
'''函數調用時的參數--位置/關鍵字實參'''
# 將列表中的元素都轉換為位置實參--使用*
def fun(a,b,c): # a,b,c在函數的定義處,所以是形式參數
print('a=',a)
print('b=',b)
print('c=',c)
fun(10,20,30) # 函數調用時的參數傳遞,稱為位置傳參
lst=[50,70,10]
fun(*lst) # 在函數調用時將列表中的每一個元素都轉換為位置實參傳入
輸出結果:
a= 10
b= 20
c= 30
a= 50
b= 70
c= 10
# 將字典中的每個鍵值對都關鍵字實參--使用**
fun(a=100,b=200,c=300) # 函數的調用處,關鍵字傳參
dic={'a':111,'b':222,'c':333}
fun(**dic) # 在函數調用時,將字典的每一個鍵值對轉化為關鍵字實參傳入
輸出結果:
a= 100
b= 200
c= 300
a= 111
b= 222
c= 333
函數定義時的參數傳遞:
def fun3(a,b,c,d): # *從這個*之後的參數在函數調用只能采用關鍵字傳遞 def fun3(a,b,*,c,d)
print('a',a)
print('b',b)
print('c',c)
print('d',d)
fun3(88,99,111,255) # 位置傳參
fun3(a=45,b=55,c=65,d=85) # 關鍵字傳參
fun3(10,20,c=40,d=50) # 前兩個是位置實參傳遞,後兩個是關鍵字實參傳遞
# 函數定義時參數的形參的順序問題
def fun4(a,b,*,c,d,**args):
pass
def fun6(*args,**args2):
pass
def fun7(a,b=10,*args,**args2):
pass
輸出函數:
a 88
b 99
c 111
d 255
a 45
b 55
c 65
d 85
a 10
b 20
c 40
d 50
程序代碼能訪問該變量的區域;
根據變量的有效范圍可分為:
局部變量:在函數內定義的並使用的變量,只在函數內部有效,局部變量使用global聲明,這個變量就會變為全局變量;
全局變量函數體外定義的變量,可作用於函數體外;
def fun(a,b):
c=a+b # c稱為局部變量,因為c是函數體內定義的變量,a和b為函數的形參,作用范圍也是函數內部,相當於局部變量
print(c)
# print(a) 報錯,a與c超出了局部變量的范圍(超出了作用域)
# print(c)
name='樣老師' # name的作用范圍為內部和外部都可以使用,稱為全局變量
print(name)
def fun2():
print('楊老師')
fun2()
def fun3():
global age # 函數內部定義的變量為局部變量,局部變量使用global聲明,這個變量就是全局變量
age=20
print(age)
fun3()
print(age)
輸出結果:
樣老師
楊老師
20
20
定義:如果在一個函數的函數體內調用了該函數本身,這個函數就稱為遞歸函數;
組成部分:遞歸調用與遞歸終止條件;
調用過程:每遞歸調用一次函數,都會在站內存分配一個棧針;每執行完一次函數,都會釋放相應的空間
優缺點:缺點:占用內存多,效率低下;優點:思路和代碼簡單
def fun(n): # 計算階乘的數
if n==1:
return 1
else:
return n*fun(n-1)
print(fun(6))
輸出結果:720
解釋:從上到下遞推,從下到上回歸(還需理解)
fun(6) 720
|
6*fun(5) 6*(120)
|
6*(5*fun(4)) 6*(5*24)
|
6*(5*(4*fun(3))) 6*(5*(4*6))
|
6*(5*(4*(3*fun(2)))) 6*(5*(4*(3*2)))
|
6*(5*(4*(3*(2*fun(1))))) 6*(5*(4*(3*(2*1))))
def fib(n): # n代表第幾位數
if n==1:
return 1
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(7))
# 1 1 2 3 5 8 13 ...
# 輸出前六位數字
for i in range(1,7):
print(fib(i))
輸出結果:
13
1
1
2
3
5
8
補充遞歸是什麼:程序調用自身的編程技巧。
面向過程與面向對象:
類是多個類似事物組成的群體的統稱,能夠判斷
1.數據類型:不同的數據類型屬於不同的類;使用內置函數查看數據類型type()
2.對象:100、99、520都是int類之下包含的相似的不同個例,這個個例專業術語稱為實例或對象
3.類的創建:
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
pass
# python 中一切皆對象,Student是對象嗎?有內存空間嗎?
print(id(Student))
print(type(Student))
print(Student)
輸出結果:
2800713235104
<class 'type'>
<class '__main__.Student'>
4.類的組成:
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法:傳的是實例對象
def study(self):
print('我在實習...')
# 靜態方法
@staticmethod
def method():
print('我使用了staticmethod進行修飾,所以我是靜態方法')
# 類方法
@classmethod
def cm(cls):
print('我是類方法,因為我使用了classmethod進行修飾')
1.對象的創建:又稱為類的實例化
語法: 實例名=類名( )
例子:
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法:傳的是實例對象
def study(self):
print('我在實習...')
# 創建Student類的實例對象
stu=Student('張三',20) # 實例對象(有類指針),會指向類對象
print(id(stu)) # Student類的實例對象的內存地址
print(type(stu))
print(stu)
輸出結果:
1761611947792
<class '__main__.Student'>
<__main__.Student object at 0x0000019A28411F10>
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法
def study(self):
print('我在實習...')
# 創建Student類的實例對象
stu=Student('張三',20) # 實例對象(有類指針),會指向類對象調用類對象
stu.study() # 對象名.方法名 實例方法
print(stu.name) # 實例屬性
print(stu.age)
# 類名.方法名(類的對象)--實際上就是方法定義處的self
Student.study(stu) # 與stu.study()功能相同,都是調用student的study方法
輸出結果:
我在實習...
張三
20
我在實習...
遺留:兩者區別!
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性(類中方法外的變量稱為類屬性,被該類的所有對象所共享)
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法
def study(self):
print('我在實習...')
stu = Student('張三',40)
stu1 = Student('李四',35)
print(stu.native_place)
print(stu1.native_place)
Student.native_place = '北京'
print(stu.native_place)
print(stu1.native_place)
輸出結果:
吉林
吉林
北京
北京
類方法:
使用@classmethod修飾的方法,使用類名直接訪問
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法
def study(self):
print('我在實習...')
@classmethod
def cm(cls):
print('我是類方法,因為我使用了classmethod修飾')
Student.cm()
輸出結果:
我是類方法,因為我使用了classmethod修飾
靜態方法:
使用@staticmethod修飾的方法,使用類名直接訪問
class Student: # Student 類名;由一個或多個單詞組成,每個單詞的首字母大寫,其余小寫
native_place='吉林' # 直接寫在類裡的變量,稱為類屬性
def __init__(self,name,age): # 初始化變量
self.name=name # self.name稱為實例屬性,進行了一個賦值操作,將局部變量的name的值賦值給實體屬性
self.age=age
# 定義在類內部稱為實例方法
def study(self):
print('我在實習...')
@staticmethod
def stamen():
print('我是靜態方法,因為我使用了staticmenthod')
Student.stamen()
輸出結果:
我是靜態方法,因為我使用了staticmenthod
Python是動態語言,在創建對象之後可以動態的綁定屬性和方法
class Student():
def __init__(self,name,age):
self.name = name # 實例化變量=局部變量
self.age = age
def eat(self):
print('在吃飯')
stu1 = Student('張三',20)
stu2 = Student('馬武',47)
# 動態綁定屬性
stu2.gender = '女'
print(stu1.name,stu1.age)
print(stu2.name,stu2.age,stu2.gender)
# 動態綁定方法
def show(): # 函數
print('動態綁定方法')
stu1.show = show # 方法
stu1.show()
輸出結果:
張三 20
馬武 47 女
動態綁定方法
python類函數有self和沒self的區別:有self必須創建實例;沒有self可以直接用類名調用函數。
封裝:提高程序的安全性;
將數據(屬性)和行為(方法)包裝在類對象中。在方法內部對屬性進行操作,在類對象的外部調用方法。這樣,無需關心方法內部的具體實現細節,從而隔離了復雜度。
在python中沒有專門的修飾符用於屬性的私有,如果該屬性不希望在類對象外部被訪問,前邊使用兩個“_”
class Car():
def __init__(self,brand): # brand 是類的一個屬性
self.brand = brand
def start(self):
print('汽車已啟動')
car = Car('大眾')
Car.start(car) # car.start()
print(car.brand)
輸出結果:
汽車已啟動
大眾
class Student():
def __init__(self,name,age):
self.name = name
self.__age = age # 不希望在類的外部調用
def show(self):
print(self.name,self.__age)
stu = Student('lisi',20)
stu.show()
print(stu.name)
# print(stu.__age) 出錯不能調用
print(dir(stu))
print(stu._Student__age)
輸出結果:
lisi 20
lisi
['_Student__age', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'show']
20
繼承:提高代碼的復用性
語法格式:
class 子類類名(父類1,父類2,...):
pass
#如果一個類沒有繼承任何類,則默認繼承object
#python支持多繼承
#定義子類時,必須在其構造函數中調用父類的構造函數
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stunum):
super().__init__(name,age) # super函數是用來調用父類(超類)的一個方法;
self.stunum=stunum
class Teacher(Person):
def __init__(self,name,age,teachyear):
super().__init__(name,age)
self.teachyear=teachyear
student=Student('李四',23,'18010832')
teacher=Teacher('麼妹',60,23)
student.info()
teacher.info()
輸出結果:
李四 23
幺妹 23
class A(object):
pass
class B(object):
pass
class C(A,B):
pass
方法重寫:
如果子類對繼承的父類的某個屬性或方法不滿意,可以在子類中對其(方法體)進行重新編寫;
子類重寫後的方法:super().xxx()調用父類中被重寫的方法;
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stunum):
super().__init__(name,age)
self.stunum=stunum
def info(self):
super().info()
print(self.stunum)
class Teacher(Person):
def __init__(self,name,age,teachyear):
super().__init__(name,age)
self.teachyear=teachyear
def info(self):
super().info()
print(self.teachyear)
student=Student('李四',23,'18010832')
teacher=Teacher('麼妹',60,23)
student.info()
teacher.info()
輸出結果:
李四 23
18010832
麼妹 60
23
object類:
是所有類的父類,因此所有類都有object類的屬性和方法;
內置函數dir()可以查看指定對象所有的屬性;
object有一個____str____()方法,用於返回一個對於“對象的描述”,對應於內置函數str()經常用於print()方法,幫我們查看對象的信息,所以我們經常會對____str____()進行重寫.
class Student():
pass
stu=Student()
print(dir(stu))
print(stu)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
<__main__.Student object at 0x00000186A9217400> 返回對象的描述
重寫____str____()方法
class Person:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):
return '我的名字叫{0},今年{1}歲'.format(self.name,self.age)
stu=Person("馬麗榮",23)
print(dir(stu)) #可以查看指定對象所有屬性
print(type(stu))
print(stu)
輸出結果:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name']
<class '__main__.Person'>
我的名字叫馬麗榮,今年23歲
多態:提高程序的可擴展性和可維護性
即便不知道一個變量所引用的對象到底是什麼類型,仍然可以通過這個變量調用方法,在運行過程中根據變量所引用對象類型,動態調用哪個對象中的方法
class Anmial(object):
def eat(self):
print("動物要吃...")
class Dog(Anmial):
def eat(self):
print("狗吃骨頭...")
class Cat(Anmial):
def eat(self):
print("貓貓愛吃魚...")
class Person(object):
def eat(self):
print("人吃五谷雜糧...")
def func(anmi):
anmi.eat() # 不關心對象的類型,只關系該對象是否具有eat的行為
func(Dog())
func(Cat())
func(Person())
func(Anmial())
輸出結果:
狗吃骨頭...
貓貓愛吃魚...
人吃五谷雜糧...
動物要吃...
person不存在繼承關系,但是有eat方法;
python是動態語言,可以動態的綁定屬性和方法,不需要關心person是誰的子類,關心person是否有eat屬性或方法;
特殊屬性:dict() 獲得類對象或實例對象所綁定的所有屬性和方法的字典
class A:
pass
class B:
pass
class C(A,B):
def __init__(self,name,age):
self.name=name
self.age=age
class D(A):
pass
#創建C類對象
x=C('Jack',20) # x是C類型的實例對象;
print(x.__dict__) #實例對象的屬性字典
print(C.__dict__)
print(x.__class__) # 輸出對象所屬的類
print(C.__bases__) # C類的父類類型的元素
print(C.__base__) # 類的基類
print(C.__mro__) # 類的層次結構
print(A.__subclasses__())
輸出結果:
{'name': 'Jack', 'age': 20}
{'__module__': '__main__', '__init__': <function C.__init__ at 0x000002450577D670>, '__doc__': None}
<class '__main__.C'>
(<class '__main__.A'>, <class '__main__.B'>)
<class '__main__.A'>
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
[<class '__main__.C'>, <class '__main__.D'>]
__init__ __new__ 方法:
class Students(object):
def __new__(cls, *args, **kwargs): # 用於創建對象
print('__new__被調用執行了,cls的id值為:{0}'.format(id(cls))) # 4608
objj=super().__new__(cls)
print('創建的對象的id為:{0}'.format(id(objj))) # 3824
return objj
def __init__(self,name,age): # 對創建的對象進行初始化
print('__init__方法調用了id:{0}'.format(id(self))) # 3824
self.name = name
self.age = age
print("輸出Student類的的id:{0}".format(id(Students))) # 4608
print("輸出object對象的id:{0}".format(id(object))) # 2336
stu = Students("張三",20)
print("輸出實例對象stuid:{0}".format(id(stu))) # 3824
cls是類方法裡面的第一個參數,表示類本身;self是實例方法裡的第一個參數,表示對象本身。
變量的賦值操作:只是形成了兩個變量,實際上還是指向同一個對象
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk =disk
# 變量的賦值
cpu1 = CPU()
cpu2 = cpu1
print(cpu1,id(cpu1))
print(cpu2,id(cpu2))
輸出結果:
<__main__.CPU object at 0x000001F0FA767400> 2134505845760
<__main__.CPU object at 0x000001F0FA767400> 2134505845760
淺拷貝:python拷貝一般都是淺拷貝,拷貝時對象包含的子對象不拷貝,因此,原對象與拷貝對象會引用同一個子對象。(是重新建立了一個Computer實例對象,相當於原來的實例對象id變了,但是value不變,因此新拷貝出來的computer實例對象cpu和disk還是原來的)
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk =disk
cpu1 = CPU()
# 類的淺拷貝
disk = Disk()
computer = Computer(cpu1,disk)
import copy
computer2 = copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
輸出結果:
<__main__.Computer object at 0x0000019CA5AB4640> <__main__.CPU object at 0x0000019CA5AC7400> <__main__.Disk object at 0x0000019CA5B41CA0>
<__main__.Computer object at 0x0000019CA5BBA070> <__main__.CPU object at 0x0000019CA5AC7400> <__main__.Disk object at 0x0000019CA5B41CA0>
深拷貝:使用copy模塊的deepcopy函數,遞歸拷貝對象中包含的子對象,源對象和拷貝對象所有的的子對象也不相同。
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk =disk
cpu1 = CPU()
disk = Disk()
computer = Computer(cpu1,disk)
import copy
computer3 = copy.deepcopy(computer)
print(computer,computer.cpu,computer.disk)
print(computer3,computer3.cpu,computer3.disk)
輸出結果:
<__main__.Computer object at 0x0000021BD3C64640> <__main__.CPU object at 0x0000021BD3C77400> <__main__.Disk object at 0x0000021BD58A1CA0>
<__main__.Computer object at 0x0000021BD591A130> <__main__.CPU object at 0x0000021BD5966D30> <__main__.Disk object at 0x0000021BD5983AC0>
模塊:Modules
函數與模塊的關系:一個模塊中可以包含N多個函數;
在python中一個擴展名為.py的文件就是一個模塊;
使用模塊的好處:方便其它程序和腳本的導入並使用;避免函數名和變量名沖突;提高代碼的可維護性與可重用性。
創建模塊:新建一個.py文件,名稱盡量不要與python自帶的標准模塊名稱相同
導入模塊:
import 模塊名稱 [as 別名]
from 模塊名稱 import 函數/變量/類
import math
print(math.pi)
print(math.pow(2,3))
print(math.ceil(9.001))
print(math.floor(9.999))
輸出結果:
3.141592653589793
8.0
10
9
或者這樣寫...
from math import pi
from math import pow
print(pi)
print(pow(2,3))
輸出結果:
3.141592653589793
8.0
導入自定義模塊:
新建名為calc.py的模塊,寫入內容為
def add(a,b):
return a+b
def div(c,d):
return (c/d)
再新建文件.py,引入自定義的模塊
import calc
print(calc.add(2, 3))
print(calc.div(10,4))
輸出結果:
5
2.5
也可以這樣寫:
from calc import add
from calc import div
print(add(2,3))
print(div(10,4))
輸出結果:
5
2.5
在每個的模塊的定義中都包括一個記錄模塊名稱的變量____name____,程序可以檢查該變量,以確定他們在哪個模塊中執行。如果一個模塊不是被導入到其它程序中執行,那麼他可能在解釋器的頂級模塊中執行。頂級模塊的____name____變量值為____main____
if __name__ == '__main__':
pass
# 輸入“main”,回車就會輸出 if __name__ == '__main__':
新建文件calc2:
def add(a,b):
return a+b
if __name__ == '__main__': # 只有當運行calc2的時候才會輸出“print”
print(add(10,24))
再新建另一個文件demo0:
import calc2
print(calc2.add(10,20)) # 不會再輸出導入的模塊calc2的print...
包是一個分層次的目錄結構,它將一組功能相近的模塊組織在一個目錄下;
作用:代碼規范、避免模塊名沖突;
包與目錄的區別:包包含init.py文件的目錄稱為包;目錄裡通常不包含init.py文件;
Python程序下有多個包,每個包下有與之對應的多個模塊,每個模塊中就有類,函數屬性等...
包的導入:
import 包名.模塊名
右鍵模塊:“new package”, "new directory"
右鍵package1“new python file” --module1.py(寫入a=1)與module2.py(寫入b=2)
jichu下新建py文件-demo3,在demo3導入包:
import package1.module1
print(package1.module1.a)
或者可以這樣寫
import package1.module1 as KK # KK是package1.module1的別名
print(KK.a)
輸出結果:
1
導入包的模塊時注意事項:
使用import導入時只能跟包名或模塊名
import module
import package
使用from ... import導入時可以跟包,模塊,函數,變量
from package import module1
from package.module import a
補充一個me不知道的知識點:json文件是存儲數據結構和對象的文件,在web應用程序中進行數據交換。
# 獲取對象的內存大小
import sys
print(sys.getsizeof(24))
print(sys.getsizeof(str))
# 獲取時間
import time
print(time.time()) # 輸出為秒
print(time.localtime(time.time())) # 轉為本地時間
輸出結果:
1650168268.3991244
time.struct_time(tm_year=2022, tm_mon=4, tm_mday=17, tm_hour=12, tm_min=4, tm_sec=28, tm_wday=6, tm_yday=107, tm_isdst=0)
# 讀取百度
import urllib.request
print(urllib.request.urlopen('http://www.baidu.com').read())
第三方模塊的在線安裝:
pip install schedule
C:\Users>python
>>> import schedule # 無回顯表示安裝成功
第三方模塊的使用:
import 模塊名
import schedule
import time
def job():
print('哈哈,嘻嘻...')
schedule.every(3).seconds.do(job)
while True: # 無線循環語句
schedule.run_pending()
time.sleep(1)
補充作業:自動化發送信息(qq,wx,mail)怎末寫!!??
常見的字符編碼格式:
python的解釋器使用的是Unicode(內存);
.py文件在磁盤上使用的是UTF-8(外存)
不同的編碼格式決定占用的磁盤空間大小。
更改編碼格式:
#encoding=gbk
文件的讀寫操作俗稱“IO操作”;
文件讀寫操作流程:
操作原理:
.py文件是由解釋器去執行,解釋器調用操作系統資源操作磁盤上的文件,對硬盤上的文件進行讀和寫的操作。打開一個python文件後,應用程序的數據運行在內存中,從內存中拿取數據到應用程序叫讀,向內存中輸出數據叫做寫。
內置函數open()創建文件對象:
語法規則:
file = open(filename [,mode,encoding])
被創建的文件對象 要創建或打開的文件名稱 打開模式默認為只讀 默認文本文件txt中字符的編碼格式為gbk;
新建文本文檔wendang.txt(默認編碼格式是gbk):
中國
美麗
新建.py文件:
file=open('wenben.txt','r',encoding='utf-8') # 將txt的編碼格式轉換為.py文件默認的編碼格式utf-8
print(file.readlines())
file.close()
輸出結果: # 列表形式輸出
['中國\n', '美麗']
文件的類型:按文件中數據的組織形式,文件分為以下兩大類
文本文件:存儲的是普通的“字符文本”,默認為Unicode字符集,可以使用記事本程序打開;
二進制文件:把數據內容用“字節”存儲,無法用記事本打開,必須使用專用的軟件打開,舉例:MP3音頻文件 .jpg圖片 .doc文檔等。
# r
file=open('123.txt','w') # 有該文件寫入內容覆蓋,沒有該文件則創建文件寫入內容
file.write('python')
file.close()
輸出結果:
有該文件且文件內容為什麼都會被寫入的內容覆蓋掉;
沒有該文件則會有新的文件123.txt創建,寫入內容
python
#a
file=open('123.txt','a') # 追加內容
file.write('python')
file.close()
在已有的123.tex文件中輸出結果:
pythonpython
src_file=open('photo.jpg','rb')
targt_file=open('copyphoto.jpg','wb')
targt_file.write(src_file.read())
src_file.close()
targt_file.close()
a.txt內容為
中國
美麗
讀:
file = open('a.txt', 'r', encoding='UTF-8')
print(file.read())
輸出結果:
中國
美麗
file = open('a.txt', 'r', encoding='UTF-8')
print(file.read(2))
輸出結果:
中國
file = open('a.txt', 'r', encoding='UTF-8')
print(file.readline())
輸出結果:
中國
file = open('a.txt', 'r', encoding='UTF-8')
print(file.readlines())
輸出結果:
['中國\n', '美麗']
寫:
file = open('c.txt', 'a')
file.write('hello') # 將字符串寫入內容
file.close() # 創建名為c.txt文件內容為“hello”
file = open('c.txt', 'a')
lst = ['java','go','python']
file.writelines(lst)
file.close() # c.txt文件中內容為 “hellojavagopython”
file = open('d.txt', 'r',encoding='utf-8')
file.seek(3) # 一個中文占2個字節,光標停在“中之前”
print(file.read())
file.close()
輸出結果:
國
美麗
file = open('d.txt', 'r',encoding='utf-8')
print(file.read())
print(file.tell()) # 14字節
file.close()
輸出結果:
中國
美麗
14
file = open('f.txt', 'a')
file.write('enheng')
file.flush() # 數據是會先寫在緩存裡的
file.write('aha')
file.close()
輸出結果:
enhengaha
with語句可以自動管理上下文資源,不論什麼原因跳出with塊,都能確保文件正確的關閉,以此來達到釋放資源的目的。
with open('f.txt','r',encoding='utf-8') as file:
print(file.read())
open('f.txt','r',encoding='utf-8')稱為上下文表達式,對象稱為上下文管理器
上下文管理器:一個類對象實現了特殊方法____enter____與____exit____,那麼稱類對象遵守上下文關系協議,而這個類的實例對象就稱為上下文管理器。
語言解釋:
class MyContentMgr(object):
def __enter__(self):
print("__enter__方法被調用了")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("__exit__被調用執行了")
def show(self):
print('show方法被調用執行了')
with MyContentMgr() as file: # 相當於MycontentMgr=file
file.show()
輸出結果:
__enter__方法被調用了
show方法被調用執行了
__exit__被調用執行了
不管有無異常還是會調用exit方法退出 叫做自動關閉資源
建議用with語句寫打開文件
with open('789.jpg', 'rb') as src_file:
with open('9810.jpg','wb') as targ_file:
targ_file.write(src_file.read())
目錄操作:os模塊是python內置的與操作系統功能和文件系統相關的模塊,該模塊中的語句的執行結果通常與操作系統有關,在不同的操作系統上運行,得到的結果可能不一樣。os模塊與os.path模塊用於對目錄或文件進行操作。
import os
os.system('notepad.exe') # 打開記事本應用程序
os.system('calc.exe') # 打開計算機應運程序
# 直接調用可執行文件
os.startfile('C:\\Program Files (x86)\\Tencent\\QQ\\Bin\\qq.exe') # 登錄應用程序qq
os模塊操作目錄相關函數:
import os
print(os.getcwd())
lis = os.listdir('../jichu') # 注意是“/”
print(lis)
os.mkdir('newpy') # 默認目錄路徑與當前寫的程序的文件在一個路徑下
os.makedirs('A/B/C')
os.rmdir('newpy.py')
os.removedirs('A/B/C')
import os
print(os.getcwd())
os.chdir('E:\\(network)\\python資料及練習\\python學習-練習\\project')
print(os.getcwd())
輸出結果:
E:\(network)\python資料及練習\python學習-練習\jichu
E:\(network)\python資料及練習\python學習-練習\project
import os.path
print(os.path.abspath('project')) # 目錄的絕對路徑
print(os.path.exists('jichu'),os.path.exists('calc.py'))
print(os.path.join('E:\\Python','demo110.py'))
print(os.path.split('E:\(network)\python資料及練習\python學習-練習\jichu')) #目錄與文件拆分
print(os.path.splitext('bug.py'))
print(os.path.basename('E:\(network)\python資料及練習\python學習-練習\jichu\leiyuduixiang.py'))
print(os.path.dirname('E:\(network)\python資料及練習\python學習-練習\jichu\leiyuduixiang.pyd'))
print(os.path.isdir('E:\(network)\python資料及練習\python學習-練習\jichu'))
輸出結果:
E:\(network)\python資料及練習\python學習-練習\project
True False
E:\Python\demo110.py
('E:\\(network)\\python資料及練習\\python學習-練習', 'jichu')
('bug', '.py')
leiyuduixiang.py
E:\(network)\python資料及練習\python學習-練習\jichu
True
練習:獲取當前目錄下的所有.pyw文件
import os
path = os.getcwd()
pyfile = os.listdir(path)
for file in pyfile:
if file.endswith('.py'): # 以什麼結尾
print(file)
walk()方法:遞歸遍歷指定目錄下所有的文件和目錄。而且將目錄下的子目錄都遍歷出來。
import os
path = os.getcwd()
lis_files = os.walk(path) # 返回為一個元組
print(lis_files) # 是一個迭代器對象 <generator object walk at 0x00000148F96ED7B0>
for dirpath,dirname,filename in lis_files:
print(dirpath)
print(filename)
print(dirname)
print('------------------') # 不僅遍歷出當前目錄、文件,還遍歷出子目錄與子文件
輸出結果:
<generator object walk at 0x00000134139F3740>
E:\(network)\python資料及練習\python學習-練習\jichu
['123.txt', '789.jpg', '9810.jpg', 'a.txt', 'bug.py', 'c.txt', 'calc.py', 'copyphoto.jpg', 'd.txt', 'demo19.py', 'demo3.py', 'f.txt', 'leiyuduixiang.py', 'Object類.py', 'os模塊.py', 'os模塊函數.py', 'with語句復制圖片.py', '上下文管理器.py', '主程序1.py', '主程序2.py', '內置模塊.py', '在線安裝三方模塊使用.py', '多態.py', '引入自定義模塊.py', '斐波那契數列.py', '模塊.py', '深拷貝與淺拷貝.py', '特殊方法.py', '特殊方法2.py', '生活照10.jpg', '類方法與靜態方法.py', '繼承.py', '獲取.py文件.py', '試試.py', '讀寫方法.py', '讀取文件.py', '調試.py']
['directory1', 'me', 'newpy', 'package1', '__pycache__']
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\directory1
['1.py', '2.py']
['subdir2']
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\directory1\subdir2
['su1.py']
[]
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\me
[]
['mine']
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\me\mine
[]
['you']
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\me\mine\you
[]
[]
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\newpy
[]
[]
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\package1
['module1.py', 'module2.py', '__init__.py']
['__pycache__']
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\package1\__pycache__
['module1.cpython-38.pyc', '__init__.cpython-38.pyc']
[]
------------------
E:\(network)\python資料及練習\python學習-練習\jichu\__pycache__
['calc.cpython-38.pyc', '主程序1.cpython-38.pyc']
[]
------------------
import os
path = os.getcwd()
lis_files = os.walk(path) # 返回為一個元組
print(lis_files) # 是一個迭代器對象 <generator object walk at 0x00000148F96ED7B0>
for dirpath,dirname,filename in lis_files:
for dir in dirname:
print(os.path.join(dirpath,dir)) # 當前目錄下有多少個子目錄
for file in filename:
print(os.path.join(dirpath,file)) # 遍歷指定目錄下所有的文件以及目錄類似於遞歸的操作
print('--------------------')
輸出結果:
<generator object walk at 0x0000024AD0933740>
E:\(network)\python資料及練習\python學習-練習\jichu\directory1
E:\(network)\python資料及練習\python學習-練習\jichu\me
E:\(network)\python資料及練習\python學習-練習\jichu\newpy
E:\(network)\python資料及練習\python學習-練習\jichu\package1
E:\(network)\python資料及練習\python學習-練習\jichu\__pycache__
E:\(network)\python資料及練習\python學習-練習\jichu\123.txt
E:\(network)\python資料及練習\python學習-練習\jichu\789.jpg
E:\(network)\python資料及練習\python學習-練習\jichu\9810.jpg
E:\(network)\python資料及練習\python學習-練習\jichu\a.txt
E:\(network)\python資料及練習\python學習-練習\jichu\bug.py
E:\(network)\python資料及練習\python學習-練習\jichu\c.txt
E:\(network)\python資料及練習\python學習-練習\jichu\calc.py
E:\(network)\python資料及練習\python學習-練習\jichu\copyphoto.jpg
E:\(network)\python資料及練習\python學習-練習\jichu\d.txt
E:\(network)\python資料及練習\python學習-練習\jichu\demo19.py
E:\(network)\python資料及練習\python學習-練習\jichu\demo3.py
E:\(network)\python資料及練習\python學習-練習\jichu\f.txt
E:\(network)\python資料及練習\python學習-練習\jichu\leiyuduixiang.py
E:\(network)\python資料及練習\python學習-練習\jichu\Object類.py
E:\(network)\python資料及練習\python學習-練習\jichu\os模塊.py
E:\(network)\python資料及練習\python學習-練習\jichu\os模塊函數.py
E:\(network)\python資料及練習\python學習-練習\jichu\with語句復制圖片.py
E:\(network)\python資料及練習\python學習-練習\jichu\上下文管理器.py
E:\(network)\python資料及練習\python學習-練習\jichu\主程序1.py
E:\(network)\python資料及練習\python學習-練習\jichu\主程序2.py
E:\(network)\python資料及練習\python學習-練習\jichu\內置模塊.py
E:\(network)\python資料及練習\python學習-練習\jichu\在線安裝三方模塊使用.py
E:\(network)\python資料及練習\python學習-練習\jichu\多態.py
E:\(network)\python資料及練習\python學習-練習\jichu\引入自定義模塊.py
E:\(network)\python資料及練習\python學習-練習\jichu\斐波那契數列.py
E:\(network)\python資料及練習\python學習-練習\jichu\模塊.py
E:\(network)\python資料及練習\python學習-練習\jichu\深拷貝與淺拷貝.py
E:\(network)\python資料及練習\python學習-練習\jichu\特殊方法.py
E:\(network)\python資料及練習\python學習-練習\jichu\特殊方法2.py
E:\(network)\python資料及練習\python學習-練習\jichu\生活照10.jpg
E:\(network)\python資料及練習\python學習-練習\jichu\類方法與靜態方法.py
E:\(network)\python資料及練習\python學習-練習\jichu\繼承.py
E:\(network)\python資料及練習\python學習-練習\jichu\獲取.py文件.py
E:\(network)\python資料及練習\python學習-練習\jichu\試試.py
E:\(network)\python資料及練習\python學習-練習\jichu\讀寫方法.py
E:\(network)\python資料及練習\python學習-練習\jichu\讀取文件.py
E:\(network)\python資料及練習\python學習-練習\jichu\調試.py
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\directory1\subdir2
E:\(network)\python資料及練習\python學習-練習\jichu\directory1\1.py
E:\(network)\python資料及練習\python學習-練習\jichu\directory1\2.py
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\directory1\subdir2\su1.py
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\me\mine
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\me\mine\you
--------------------
--------------------
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\package1\__pycache__
E:\(network)\python資料及練習\python學習-練習\jichu\package1\module1.py
E:\(network)\python資料及練習\python學習-練習\jichu\package1\module2.py
E:\(network)\python資料及練習\python學習-練習\jichu\package1\__init__.py
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\package1\__pycache__\module1.cpython-38.pyc
E:\(network)\python資料及練習\python學習-練習\jichu\package1\__pycache__\__init__.cpython-38.pyc
--------------------
E:\(network)\python資料及練習\python學習-練習\jichu\__pycache__\calc.cpython-38.pyc
E:\(network)\python資料及練習\python學習-練習\jichu\__pycache__\主程序1.cpython-38.pyc
--------------------
補充詞語理解:
循環(loop),指的是在滿足條件的情況下,重復執行同一段代碼。比如,while語句。
迭代(iterate),指的是按照某種順序逐個訪問列表中的每一項。比如,for語句。每一次對過程的重復稱為一次“迭代”,而每一次迭代得到的結果會作為下一次迭代的初始值。走n遍,反反復復
遍歷(traversal),指的是按照一定的規則訪問樹形結構中的每個節點,而且每個節點都只訪問一次。'走一遍'
遞歸(recursion),指的是一個函數不斷調用自身的行為。比如,以編程方式輸出著名的斐波納契數列。
1.漏了末尾的冒號,如if語句,循環語句,else子句等;
2.縮進錯誤;
3.把英文符號寫成中文符號;
4.字符串拼接的時候,把字符串和數字拼在一起;
5.沒有定義變量;
6."=="比較運算符與賦值運算符"="混用
思路不清導致的問題解決方案
1.使用print()函數;
2.使用"#"暫時注釋部分代碼;
被動掉坑:程序代碼邏輯沒有錯,只是因為用戶錯誤操作或者一些"例外情況"而導致的程序崩潰;
異常處理機制:可以在異常出現時即時捕獲,然後內部繼續"消化",讓程序繼續運行;
try...except...結構
try:
...
可能會出現的異常的代碼...
...
except xxx(異常類型):
...
異常處理代碼... # 報錯後執行的代碼
...
# 輸入兩個整數並進行除數運算
try:
num1 = int(input('輸入第一個整數:'))
num2 = int(input('輸入第二個整數:'))
num = num1/num2
print(num)
except:
print('輸出錯誤')
或
try:
num1 = int(input('輸入第一個整數:'))
num2 = int(input('輸入第二個整數:'))
num = num1/num2
print(num)
except ZeroDivisionError:
print('輸出錯誤')
多個except結構:捕獲異常的順序按照先子類後父親類的順序,為了避免遺漏可能出現的異常,可以在最後增加BaseException
try:
...
... # 可能會出現的異常的代碼
...
except Expection1:
...
... # 異常處理代碼
...
except Expection2:
...
... # 異常處理代碼
...
except BaseException:
...
... # 異常處理代碼
...
try:
num1 = int(input('輸入第一個整數:'))
num2 = int(input('輸入第二個整數:'))
num = num1/num2
print(num)
except ZeroDivisionError:
print('除數不能為0')
except ValueError:
print('不能為字母')
except BaseException as e:
print('程序結束')
try...except...else結構
如果try塊中沒有拋出異常,則執行else塊,如果try中拋出異常,則執行except塊。
try:
num1 = int(input('輸入第一個整數:'))
num2 = int(input('輸入第二個整數:'))
num = num1/num2
except BaseException as e:
print('出錯了')
print(e)
else:
print('結果為:',num)
try...except...else...finally結構
finally塊無論如何是否發生異常都會被執行,能常用來釋放try塊中申請的資源。
try:
num1 = int(input('輸入第一個整數:'))
num2 = int(input('輸入第二個整數:'))
num = num1/num2
except BaseException as e:
print('出錯了')
print(e)
else:
print('結果為:',num)
finally:
print('無論是否產生異常,總會被執行的代碼')
print('程序結束')
輸出結果:
輸入第一個整數:78
輸入第二個整數:2
結果為: 39.0
無論是否產生異常,總會被執行的代碼
程序結束
sorted()函數對所有可迭代對象進行排序操作。
語法:
sorted(interable,cmp=None,key=None,reverse=False)
interable--可迭代對象;
cmp--比較的函數,這個具有兩個參數,參數的值都是從可迭代對象中取出,此函數必須遵守的規則是:大於則返回1,小於則返回-1,等於則返回0;
key--主要用來進行比較的元素,只有一個參數,具體的函數參數就是取自可迭代對象中,指定可迭代對象中的一個元素進行排序。
reverse--排序規則,reverse=True降序,reverse=False升序(default).
一個從程序外部獲取獲取參數的橋梁,獲得的是一個列表,用[]提取其中的元素,其第一個元素是程序本身,隨後才依次是外部給予的參數。
模塊:a_plus_b.py
def plus(a:int, b:int ) -> int:
return a + b
模塊:main.py
import sys
from a_plus_b import plus
a = int(sys.argv[1])
b = int(sys.argv[2])
print(plus(a,b))
sum(interable[,start])
interable--可迭代對象,列表、元組、集合。
start--指定相加的參數,如果沒有設定這個值,默認為0.
map(function,interable,...)
function--函數
interable--一個或多個序列
返回迭代器(python3.x)
import sys
input_filepath = sys.argv[1]
with open(input_filepath,'r',encoding='utf-8') as sum_file:
sumfile = sum_file.read().split(' ')
# print(sumfile,type(sumfile))
new_num = map(int,sumfile)
print(sum(new_num))
splitlines()方法語法:
str.splitlines([keepends])
count()方法語法:
str.count(sub,start = 0,end = len(string))
sub--搜索的子字符串
start--字符串開始搜索的位置。默認為第一個字符,第一個字符的索引值為0。
end--字符串中結束搜索的位置。字符中第一個字符的索引為0。默認為字符串的最後位置
返回值:返回子字符串在字符串中出現的次數。
def num_your(poem):
# write your code here
# num_count = 0
# for item in poem.splitlines():
# if 'your' in item:
# num_count += 1
# return num_count
num_count = poem.count(' your ')
return num_count
len()方法返回對象(字符、列表、元組)長度或項目個數。
len()方法語法:
len(s)
s--對象
返回值:對象長度
eval()函數用來執行一個字符串表達式,並返回表達式的值。
語法:
eval(expression[,globals[,locals]])
expression--表達式
globals--變量作用域,全局命名空間,如果被提供,則必須是一個字典對象。
post()方法將POST請求發送到指定的URL。
post()方法將某些數據發送到服務器時使用。
requests.post(url, data={key: value}, json={key: value}, args)
args表示下面參數表中的零個或多個*命名*參數。例:
requests.post(url, data = myobj, timeout=2.50)
True(允許重定向)auth可選。用於啟用某種HTTP身份驗證的元組。 默認Nonecert可選。指定證書文件或密鑰的字符串或元組。 默認Nonecookies可選。要發送到指定網址的Cookie字典。 默認Noneheaders可選。要發送到指定網址的HTTP標頭字典。 默認Noneproxies可選。URL代理協議字典。 默認Nonestream可選。如果響應應立即下載(False)或流式傳輸(True)的布爾指示。 默認Falsetimeout可選。一個數字或一個元組,指示等待客戶端建立連接和/或發送響應的秒數。 默認值None表示請求將繼續,直到連接關閉verify可選。用於驗證服務器TLS證書的布爾值或字符串指示。 默認True