Python用做數據處理還是相當不錯的,如果你想要做爬蟲,Python是很好的選擇,它有很多已經寫好的類包,只要調用,即可完成很多復雜的功能
在我們開始之前,我們需要安裝一些環境依賴包,打開命令行

確保電腦中具有python和pip,如果沒有的話則需要自行進行安裝
之後我們可使用pip安裝必備模塊 requests
pip install requests
requests是python實現的簡單易用的HTTP庫,使用起來比urllib簡潔很多,requests 允許你發送 HTTP/1.1 請求。指定 URL並添加查詢url字符串即可開始爬取網頁信息
以該平台為例,抓取網頁中的公司名稱數據,網頁鏈接:https://www.crrcgo.cc/admin/crr_supplier.html?page=1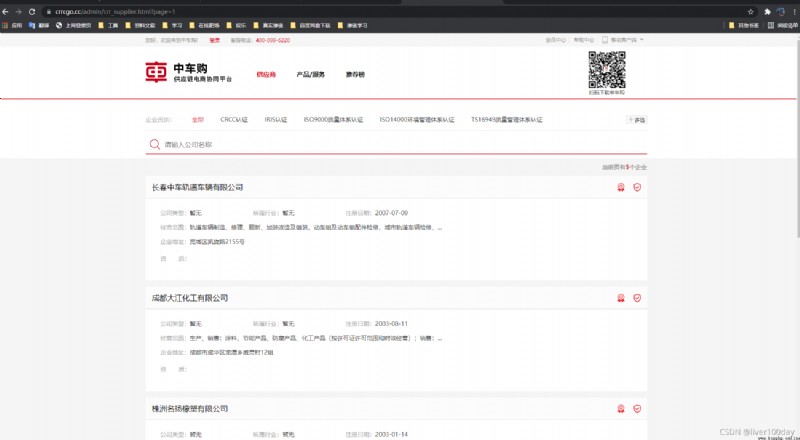
目標網頁源代碼如下: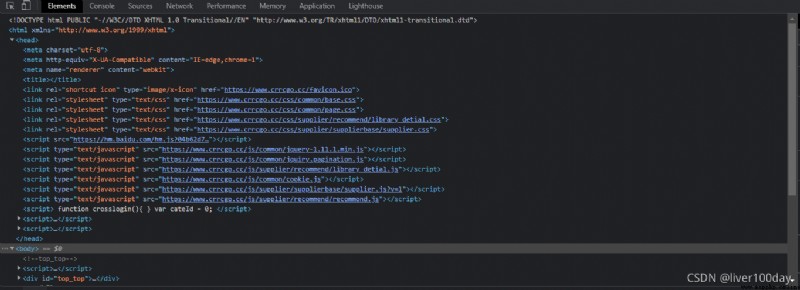
首先明確步驟
1.打開目標站點
2.抓取目標站點代碼並輸出
import requests
導入我們需要的requests功能模塊
page=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
這句命令的意思就是使用get方式獲取該網頁的數據。實際上我們獲取到的就是浏覽器打開百度網址時候首頁畫面的數據信息
print(page.text)
這句是把我們獲取數據的文字(text)內容輸出(print)出來
import requests
page=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
print(page.text)
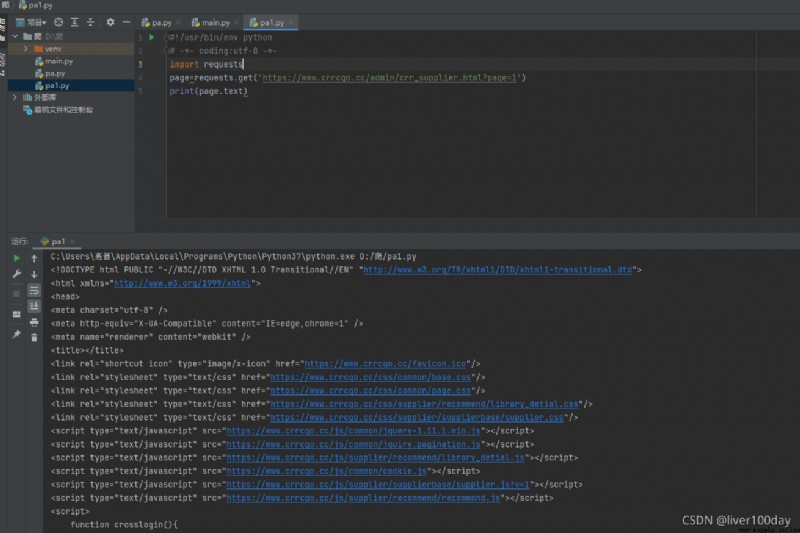
成功爬取到了目標網頁源代碼
但是上面抓取到的代碼充滿尖括號的一片字符,對我們沒有什麼作用,這樣的充滿尖括號的數據就是我們從服務器收到的網頁文件,就像Office的doc、pptx文件格式一樣,網頁文件一般是html格式。我們的浏覽器可以把這些html代碼數據展示成我們看到的網頁。
我們如果需要這些字符裡面提取有價值的數據,就必須先了解標記元素
每個標記的文字內容都是夾在兩個尖括號中間的,結尾尖括號用/開頭,尖括號內(img和div)表示標記元素的類型(圖片或文字),尖括號內可以有其他的屬性(比如src)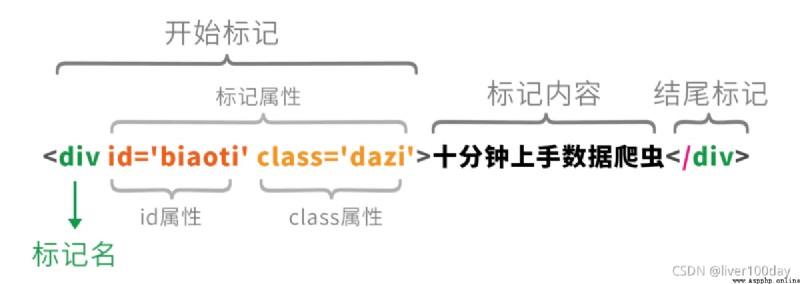
標記內容文字才是我們需要的數據,但我們要利用id或class屬性才能從眾多標記中找到需要的標記元素。
我們可以在電腦浏覽器中打開任意網頁,按下f12鍵即可打開元素查看器(Elements),就可以看到組成這個頁面的成百上千個各種各樣的標記元素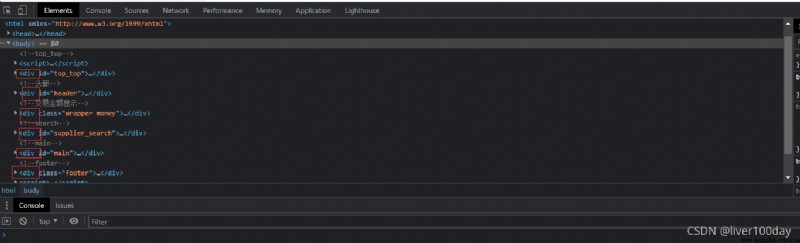
標記元素是可以一層一層嵌套的,比如下面就是body嵌套了div元素,body是父層、上層元素;div是子層、下層元素。
<body>
<div>十分鐘上手數據爬蟲</div>
</body>
回到抓取上面來,現在我只想在網頁中抓取公司名這個數據,其他的我不想要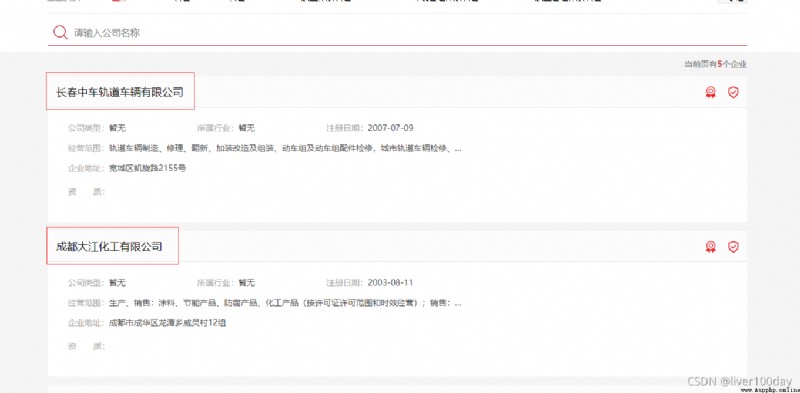
查看網頁html代碼,發現公司名在標簽detail_head裡面
import requests
req=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
這兩行上面解釋過了,是獲取頁面數據
from bs4 import BeautifulSoup
我們需要使用BeautifulSoup這個功能模塊來把充滿尖括號的html數據變為更好用的格式,from bs4 import BeautifulSoup這個是說從bs4這個功能模塊中導入BeautifulSoup,是的,因為bs4中包含了多個模塊,BeautifulSoup只是其中一個
req.encoding = "utf-8"
指定獲取的網頁內容用utf-8編碼
soup = BeautifulSoup(html.text, 'html.parser')
這句代碼用html解析器(parser)來分析我們requests得到的html文字內容,soup就是我們解析出來的結果。
company_item=soup.find_all('div',class_="detail_head")
find是查找,find_all查找全部。查找標記名是div並且class屬性是detail_head的全部元素
dd = company_item.text.strip()
strip() 方法用於移除字符串頭尾指定的字符(默認為空格或換行符)或字符序列。在這裡就是移除多余的尖括號的html數據
最後拼接之後代碼如下:
import requests
from bs4 import BeautifulSoup
req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_item = soup.find("div",class_="detail_head")
dd = company_item.text.strip()
print(dd)
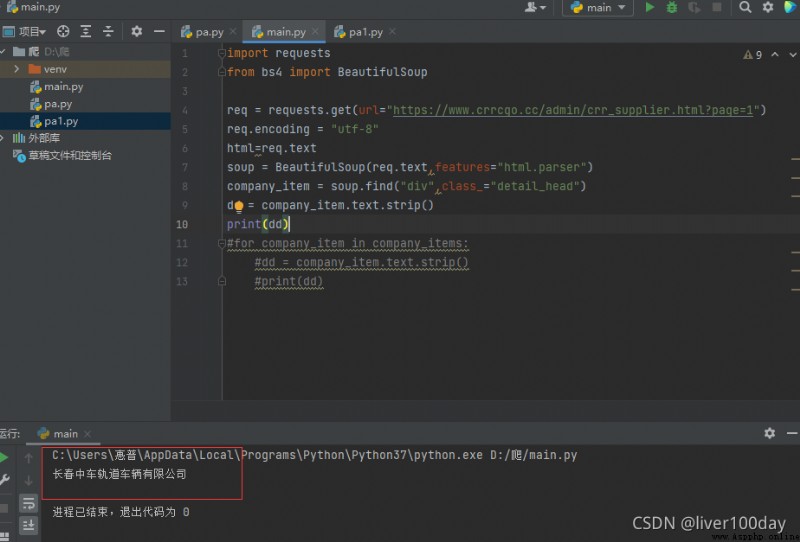
最後執行結果成功的抓取到了網頁中我們想要的公司信息,但是卻只抓取到了一個公司,其余的則並未抓取到
所以我們需要加入一個循環,抓取網頁中所有公司名,並沒多大改變
for company_item in company_items:
dd = company_item.text.strip()
print(dd)
最終代碼如下:
import requests
from bs4 import BeautifulSoup
req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_items = soup.find_all("div",class_="detail_head")
for company_item in company_items:
dd = company_item.text.strip()
print(dd)
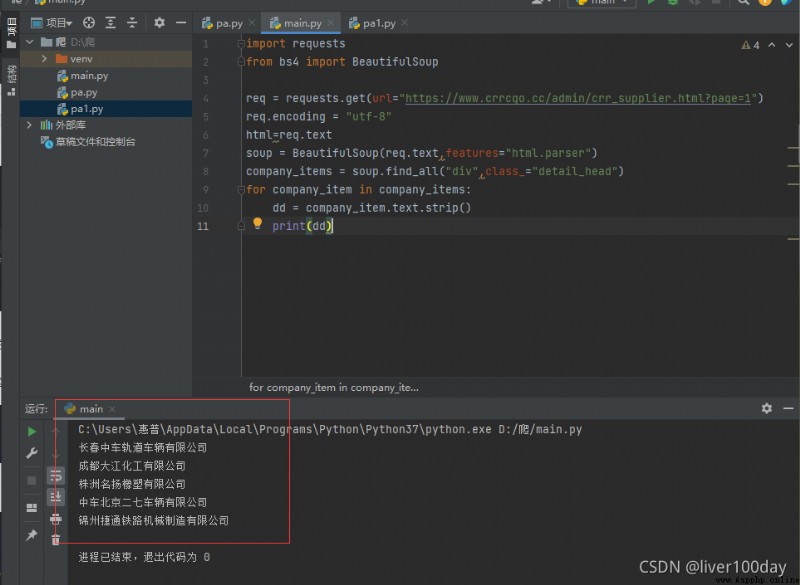
最終運行結果查詢出了該網頁中所有的公司名
那我現在想要抓取多個網頁中的公司名呢?很簡單,大體代碼都已經寫出,我們只需要再次加入一個循環即可
查看我們需要進行抓取的網頁,發現當網頁變化時,就只有page後面的數字會發生變化。當然很多大的廠商的網頁,例如京東、淘寶 它們的網頁變化時常讓人摸不著頭腦,很難猜測。
inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
for num in range(1,6):
print("================正在爬蟲第"+str(num)+"頁數據==================")
寫入循環,我們只抓取1到5頁的內容,這裡的循環我們使用range函數來實現,range函數左閉右開的特性使得我們要抓取到5頁必須指定6
outurl=inurl+str(num)
req = requests.get(url=outurl)
將循環值與url拼接成完整的url,並獲取頁面數據
完整代碼如下:
import requests
from bs4 import BeautifulSoup
inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
for num in range(1,6):
print("================正在爬蟲第"+str(num)+"頁數據==================")
outurl=inurl+str(num)
req = requests.get(url=outurl)
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_items = soup.find_all("div",class_="detail_head")
for company_item in company_items:
dd = company_item.text.strip()
print(dd)
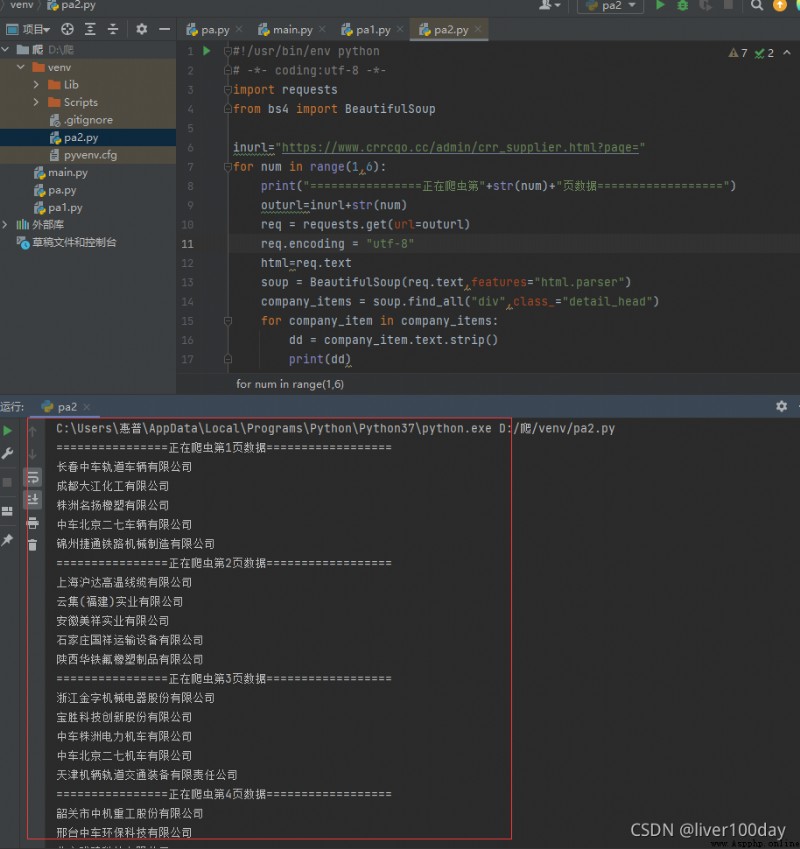
成功的抓取到了1-5頁所有的公司名(子標簽)內容
最近一直在學習,但是學習的東西很多很雜,於是便把自己的學習成果記錄下來,便利自己,幫助他人。希望本篇文章能對你有所幫助,有錯誤的地方,歡迎指出!!!喜歡的話,不要忘記點贊哦!!!
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦