參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
pandas的數據框需要修改添加刪除的便捷方法
先讀取案例數據
import numpy as np
import pandas as pd
data = 'https://www.gairuo.com/file/data/dataset/team.xlsx'
df = pd.read_excel(data) df.iloc[0,0]='Lily'
df[df.Q1<60]=60
df.Q2=[1,2,3,4,5]*20
df.Q2=range(100)
df.loc[1:2,'Q1':'Q2']=pd.DataFrame({'Q1':[1,2,3],'Q2':[4,5,6]})
df.loc[1:3, 'Q1':'Q2'] = 99 # 這個范圍的數據會全變成 99
df.loc[df.name=='Arry', 'Q1':'Q4'] = [66,77,88,99] # 指定多列
df.loc[df.name.isin(['Arry', 'Ack']), 'Q1'] = (33, 44) # 修改列值s.replace(0, 5) # 將列數據中 0 換為 5
df.replace(0, 5) # 將數據中所有 0 換為 5
df.replace([0, 1, 2, 3], 4) # 將 0-3 全換成 4
df.replace([0, 1, 2, 3], [4, 3, 2, 1]) # 對應修改
# {‘pad’, ‘ffill’, ‘bfill’, None} 試試
s.replace([1, 2], method='bfill') # 向下填充
df.replace({0: 10, 1: 100}) # 字典對應修改
df.replace({'Q1': 0, 'Q2': 5}, 100) # 指定字段的指定值修改為 100
df.replace({'Q1': {0: 100, 4: 400}}) # 指定列裡指定值按指定的值替換
# 使用正則
df.replace(to_replace=r'^ba.$', value='new', regex=True)
df.replace({'A': r'^ba.$'}, {'A': 'new'}, regex=True)
df.replace(regex={r'^ba.$': 'new', 'foo': 'xyz'})
df.replace(regex=[r'^ba.$', 'foo'], value='new')df.fillna(0) # 空全修改為 0
# {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
df.fillna(method='ffill') # 都修改為它前一個值
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
df.fillna(value=values) # 各列替換空值不同
df.fillna(value=values, limit=1) # 只替換第一個df.dropna() # 一行中有一個空NaT就刪除
df.dropna(axis='columns') # 只保留全有值的列
df.dropna(how='all') # 行或列全沒值才刪除
df.dropna(thresh=2) # 至少有兩個空值時才刪除
df.dropna(inplace=True) # 刪除並生效替換# 對索引值進行修改
df.rename(columns={"Q1": "a", "Q2": "b"}) # 對表頭進行修改
df.rename(index={0: "x", 1: "y", 2: "z"}) # 對索引進行修改
df.rename(index=str) # 對類型進行修改
df.rename(str.lower, axis='columns') # 傳索引類型
df.rename({1: 2, 2: 4}, axis='index')
# 對索引名進行修改
s.rename_axis("animal")
df.rename_axis("animal") # 默認是列索引
df.rename_axis("limbs", axis="columns") # 指定行索引
# 多層索引時可以將type修改為class
df.rename_axis(index={'type': 'class'})
# 可以用 set_axis 進行設置修改
s.set_axis(['a', 'b', 'c'], axis=0)
df.set_axis(['I', 'II'], axis='columns')
df.set_axis(['i', 'ii'], axis='columns', inplace=True)df['total']=df.Q1+df.Q2+df.Q3+df.Q4
df['total']=df.sum(1)
df['total'] = df.select_dtypes(include=['int']).sum(1)
df['total'] = df.loc[:,'Q1':'Q4'].apply(lambda x: sum(x), axis='columns')
df['foo'] = 100 # 增加一列 foo, 所有值都是 100
df['foo'] = df.Q1 + df.Q2 # 新列為兩列相加
df['foo'] = df['Q1'] + df['Q2'] # 同上
# 把所有為數字的加起來
df.loc[:, 'Q10'] = '我是新來的' # 也可以
# 增加一列並賦值,不滿足條件的為 NaN
df.loc[df.num >= 60, '成績'] = '合格'
df.loc[df.num < 60, '成績'] = '不合格'# 一般格式 df.insert(新列索引位, 名字, 數據)
df.insert(2,'total',df.sum(1))
df.insert(len(df.columns), 'Qx',pd.Series(np.random.randn(100), index=df.index))#臨時增加的列
df.assign(total=df.sum(1))
df.assign(total=df.sum(1),Q=100)#加兩列
df.assign(total=df.sum(1)).assign(Q=100)#同上
df.assign(Q5=[100]*100) # 新增加一列 Q5
df = df.assign(Q5=[100]*100) # 賦值生效
df.assign(Q6=df.Q2/df.Q1) # 計算並增加 Q6
df.assign(Q7=lambda x: x.Q1 * 9 / 5 + 32) # 使用 lambda
# 添加一列,值為表達式結果 True or False
df.assign(tag=df.Q1>df.Q2)
# True 為1 False 為 0
df.assign(tag=(df.Q1>df.Q2).astype(int))
# 映射文案
df.assign(tag=(df.Q1>60).map({True:'及格',False:'不及格'}))
# 增加多個
df.assign(Q8=lambda x: x.Q1*5,
Q9=lambda x: x.Q8+1) # 注 Q8沒生效不能直接 df.Q8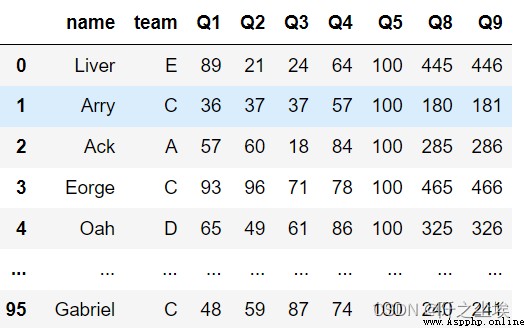
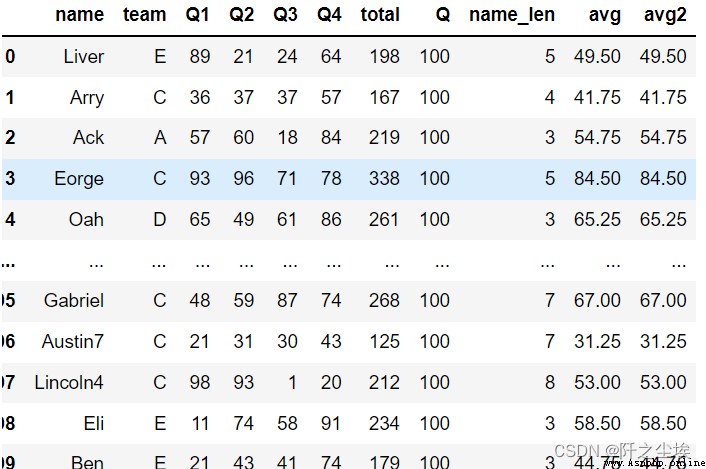
案例
###案例
(df.assign(total=df.sum(1))#z總成績
.assign(Q=100) #滿分列
.assign(name_len=df.name.str.len()) #姓名長度
.assign(avg=df.mean(1)) #平均值
.assign(avg2=lambda d:d.total/4) #平均值
)
#df.eval() 可以進行賦值定義一個新列:
df.eval('total =Q1 + Q2 + Q3+ Q4')
df['C1'] = df.eval('Q2 + Q3')
df.eval('C2 = Q2 + Q3') # 計算
a = df.Q1.mean()
df.eval("C3 = `Q3`[email protected]") # 使用變量
df.eval("C3 = Q2 > (`Q3`[email protected])") # 加一個布爾值
sys.setrecursionlimit(10000)
df.eval('C4 = name + team', inplace=True) # 立即生效df.loc[101] = ['tom', 'A', 88, 88, 88, 88]
df.loc[101]={'Q1':88,'Q2':99} # 指定列,無數據列值為NaN
df.loc[df.shape[0]+1] = {'Q1':88,'Q2':99} # 自動增加索引
df.loc[len(df)+1] = {'Q1':88,'Q2':99}
#批量操作
rows = [[1,2],[3,4],[5,6]]
for row in rows:
df.loc[len(df)] = rowdf = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
df.append(df2)#pd.concat([s1, s2]) 可以將兩個 df/s 連接起來:
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
pd.concat([s1, s2])
pd.concat([s1, s2], ignore_index=True) # 索引重新編
# 原數索引不就,增加一個一層索引(keys 裡的內容)變成多層索引
pd.concat([s1, s2], keys=['s1', 's2'])
pd.concat([s1, s2], keys=['s1', 's2'],
names=['Series name', 'Row ID'])
# df 同樣道理
pd.concat([df1, df2])
pd.concat([df1, df3], sort=False)
pd.concat([df1, df3], join="inner") # 只連相同列
pd.concat([df1, df4], axis=1) # 連接列df.pop('Q1') # 刪除一列
s.pop(3) # 刪除一個索引位
# 也可以把想要的列篩選出來賦值給 df 達到刪除的目的
df.drop([0,1]) #刪除行
df.drop('name',axis=1)#刪除列