參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
pandas的數據排序類似excel的rank函數,但是用法更多。
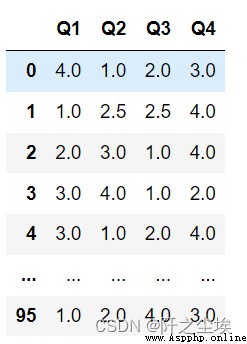
先讀取案例數據
import numpy as np
import pandas as pd
import datetime
data = 'https://www.gairuo.com/file/data/dataset/team.xlsx'
df = pd.read_excel(data) s.sort_index() # 升序排列
df.sort_index() # df 也是按索引進行排序
df.team.sort_index()
s.sort_index(ascending=False) # 降序排列
s.sort_index(inplace=True) # 排序後生效,改變原數據
# 索引重新0-(n-1) 排, 很有用,可以得到它的排序號
s.sort_index(ignore_index=True)
s.sort_index(na_position='first') # 空值在前,另 ‘last’
s.sort_index(level=1) # 如果多層,排一級
s.sort_index(level=1, sort_remaining=False) # 這層不排
# 行索引排序,表頭排序
df.sort_index(axis=1) # 會把列按列名順序排列#df.reindex()指定自己定義順序的索引,實現行和列的順序重新定義:
df = pd.DataFrame({'A': [1,2,4],
'B': [3,5,6]}, index=['a', 'b', 'c'])
df
'''A B
a 1 3
b 2 5
c 4 6'''
# 按要求重新指定索引順序
df.reindex(['c', 'b', 'a'])
'''A B
c 4 6
b 2 5
a 1 3'''
# 指定列順序
df.reindex(['B', 'A'], axis=1)
'''B A
a 3 1
b 5 2
c 6 4'''
df.Q1.sort_values()
df.sort_values('Q2') #df要傳入排序列名
df.sort_values(by=['team','name'],ascending=[True,False]) #team升序,相同的name降序
s.sort_values() # 升序
s.sort_values(ascending=False) # 降序
s.sort_values(inplace=True) # 修改生效
s.sort_values(na_position='first') # 空值在前
# df 按指定字段順序
df.sort_values(by=['team'])
df.sort_values('Q1')
# 按多個字段,先排 team, 在同 team 內再看 Q1
df.sort_values(by=['team', 'Q1'])
# 全降序
df.sort_values(by=['team', 'Q1'], ascending=False)
# 對應指定team升Q1降
df.sort_values(by=['team', 'Q1'], ascending=[True, False])
# 索引重新0-(n-1) 排
df.sort_values('team', ignore_index=True)#需要索引和值混合排序,比如先按名字排序同序的再按團隊排
df.set_index('name', inplace=True)
df.index.names = ['s_name']
df.sort_values(by=['s_name', 'team'])
# 以下方法也可以實現上述需求,不過要注意順序
df.set_index('name').sort_values('team').sort_index()s.nsmallest(3) # 最小的三個
s.nlargest(3) # 最大的三個
# 指定列
df.nlargest(3, 'Q1')
df.nlargest(5, ['Q1', 'Q2'])
df.nsmallest(len(df), ['Q1', 'Q2'])#Q1小在前,如果一樣看Q2,返回指定個數df.rank()#返回每列排序位置
df.rank(axis=1)#返回每行排序位置
df.rank(pct=True)#相對位置