參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
pandas的數據框可以進行各種自帶方法的篩選和查詢,可以使用各種邏輯個條件去找出符合要求的數據。
首先讀取演示數據集
import numpy as np
import pandas as pd
import datetime
data = 'https://www.gairuo.com/file/data/dataset/team.xlsx'
df = pd.read_excel(data) df.Q1>90
df.index==1
df.loc[:,'Q1':'Q4']>60
~(df.Q1<60)&(df['team']=='C')#Q1成績不小於60,且是c組
df[df['Q1'] == 8] # Q1 等於8
df[~(df['Q1'] == 8)] # 不等於8
df[df.name == 'Ben'] # 姓名為Ben
df[df.Q1 > df.Q2]
#loc
df.loc[df['Q1']==8]
df.loc[df['Q1'] > 90, 'Q1':] # Q1 大於90,顯示Q1後邊的所有列
df.loc[(df.Q1 > 80) & (df.Q2 < 15)] # and 關系
df.loc[(df.Q1 > 90) | (df.Q2 < 90)] # or 關系
df[(df.loc[:,['Q1','Q2']]>80).all(1)]#Q1和Q2都大於80分
df[(df.loc[:,['Q1','Q2']]>80).any(1)]#Q1和Q2至少一個大於80分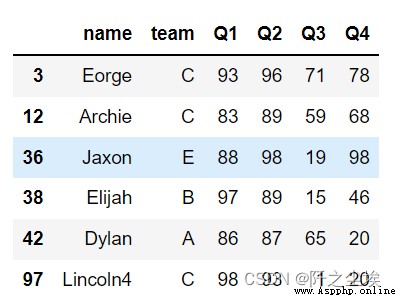
df.Q1[lambda s:max(s.index)]##最大索引的值 索引為99的人的Q1分數
max(df.Q1.index) #計算索引最大值
df.Q1[max(df.Q1.index)] #結果一樣df[lambda df: df['Q1'] == 8] # Q1為8的
df.loc[lambda df: df.Q1 == 8, 'Q1':'Q2'] # Q1為8的, 顯示 Q1 Q2
# 選擇字段時盡量使用字典法,屬性法在條件表達式時一些情況可能有 bug
df.loc[:, lambda df: df.columns.str.len()==4] # 真假組成的序列
df.loc[:, lambda df: [i for i in df.columns if 'Q' in i]] # 列名列表
df.iloc[:3, lambda df: df.columns.str.len()==2] # 真假組成的序列df[df.Q1.eq(60)]#相對於df[df.Q1==60]
df.eq() # 等於相等 ==
df.ne() # 不等於 !=
df.le() # 小於等於 >=
df.lt() # 小於 <
df.ge() # 大於等於 >=
df.gt() # 大於 >
# 都支持 axis{0 or ‘index’, 1 or ‘columns’}, default ‘columns’
df[df.Q1.ne(89)] # Q1 不等於8
df.loc[df.Q1.gt(90) & df.Q2.lt(90)] # and 關系 Q1>90 和Q2<90
df.loc[df[['Q1','Q3']].gt(60).all(1)] #相當於 df.loc[(df.Q1 > 60) & (df.Q3 > 60)] # isin
df[df.team.isin(['A','B'])] ##相當於df[(df.team=='A')|(df.team=='B')]
df[df.isin({'team': ['C', 'D'], 'Q1':[36,93]})] # 復雜查詢,其他值為 NaNdf.query('Q1 > Q2 > 90') # 直接寫類型 sql where 語句
df.query('Q1 + Q2 > 180')
df.query('Q1 == Q2')
df.query('(Q1<50) & (Q2>40) and (Q3>90)')
df.query('Q1 > Q2 > Q3 > Q4')
df.query('team != "C"')
df.query('team in ["A","B"]')
df.query('team not in ("E","A","B")')
df.query('team == ["A","B"]')
df.query('team != ["A","B"]')
df.query('name.str.contains("am")') # 包含 am 字符
# 對於名稱中帶有空格的列,可以使用反引號引起來
df.query('B == `team name`')# 支持傳入變量,如:大於平均分40分的
a = df.Q1.mean()
df.query('Q1 > @a+40')
df.query('Q1 > `Q2`[email protected]')
# df.eval() 用法與 df.query 類似
df[df.eval("Q1 > 90 > Q3 > 10")]
df[df.eval("Q1 > `Q2`[email protected]")]df.filter(items=['Q1', 'Q2']) # 選擇兩列
df.filter(regex='Q', axis=1) # 列名包含Q的
df.filter(regex='e$', axis=1) # 正則,以 e 結尾的
df.filter(regex='1$', axis=0) # 正則, 索引名1結尾的
df.filter(like='2', axis=0) # 索引中有2的
# 索引中2開頭列名有Q的
df.filter(regex='^2', axis=0).filter(like='Q', axis=1)df.select_dtypes(include=['float64']) # 選擇 float64 型數據
df.select_dtypes(include='bool')
df.select_dtypes(include=['number']) # 只取數字型
df.select_dtypes(exclude=['int64']) # 排除 int 類型
df.select_dtypes(exclude=['datetime64'])df=df.select_dtypes(include=['number'])#先只取數字##where是返回布爾值為真的位置的值,為假返回nan,形狀與原來一樣
s.where(s > 90) # 不符合條件的為 NaN
s.where(s > 90, 0) # 可以替換不符合條件的值,為 0
df.where(df>70)
df.where(lambda d:d.Q1>50)
df.Q1.where(pd.Series([True]*3)) #只取前三個
df.where(df>60,'不及格')#將nan替換為不及格
#給定算子
c=df%2==0
df.where(~c,-(df-20))#為偶數時返回原來的值減去20的相反數# np.where, 可以對滿足條件的值也進行替換
np.where(s>80, True, False)
np.where(df>=60, '合格', '不合格')
df.where(df==99999,np.where(df>60,'合格', '不合格'))##讓df.where中條件為假,應用np.where#例子
df.assign(avg=df.mean(1)).assign(及格=lambda d:np.where (d.avg>60,'是','否')) #計算平均成績,判斷是否及格
#相當於
#m=df.mean(1)
#m=m.where(m>60,'不及格')
#m.where(m=='不及格','及格')
#上面兩句改為m.where(m==99999,np.where(m>60,'合格', '不合格'))
#還可以用apply函數
###mask用法和where基本相同,就是滿足條件的位置返回Nan
df.mask(df > 90) # 符合條件的為 NaN
df.mask(df > 90, 0) # 符合條件的為 0
df.Q1.mask(df.Q1>80,'優秀')# 例:能被3整除的顯示,不能的顯示相反數
m = df.loc[:,'Q1':'Q4'] % 3 == 0
df.loc[:,'Q1':'Q4'].where(m, -df.loc[:,'Q1':'Q4'])# 行列相同數量,返回一個 array
df.lookup([1,3,4], ['Q1','Q2','Q3']) # array([36, 96, 61])
df.lookup([1], ['Q1']) # array([36]) #相當於df.loc[1,'Q1']