Communication is used in python programming, and naturally it is necessary to use the string to list function. I have tried many methods and it is not ideal. Finally, I have to use the magical eval()
The details are as follows:
str0 = b'[[0], [486.13334690553745, 473.83448697068405,7.678963807368689]],[[1], [504.08351648351646], 256.98362637362635],[[2], []],[[3], []]'To convert this string to a list or ndarray, the dimension is not fixed, the length is not fixed, the content inside is not int, but float.
There are many methods found on the Internet, but there are limitations. In the end, it is either a dimension limitation, a length limitation, an int limitation, or the square brackets cannot be recognized.
The last sentence is done:
temp1 = eval(str1)Running result:
([[0], [486.13334690553745, 473.83448697068405, 7.678963807368689]], [[1], [504.08351648351646], 256.983626373626[3], [[2], []]], [[2][]])
I can't see the conversion situation, then break the point and look at the data structure of the variable temp1, see the figure below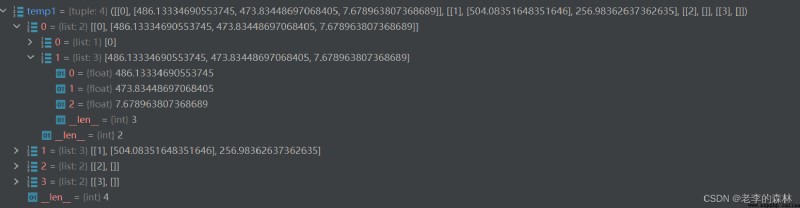
The deepest data type is float, and the structure level is also OK.Satisfied with the results.
Why do you say that you have to use eval() as a last resort, because this function is so amazing, it runs the content in the parentheses, that is, runs it as an expression, there is a hidden danger here,If the other party of the communication is a malicious program that hides the malicious code in the communication content, the operation result of eval is unknown.
There are also solutions. For my communication content, numbers from 0 to 9, spaces, decimal points, commas, square brackets are used, then I can remove all other symbols and English letters except these to removehidden danger.
Using regular expressions, the full code is as follows:
import restr0 = b'[[0], [486.13334690553745, 473.83448697068405, 7.678963807368689]],[[1], [504.08351648351646], 2535.98],[[2], []],[[3], []]'str0 = str0.decode('utf-8') # remove the previous bstr1 = re.sub('([^\u0030-\u0039\u005b\]\u002c\u002e])', '', str0)temp1 = eval(str1)print(temp1)At the break point of the print sentence, debug runs, and you can see the content of temp1, which is the same as before.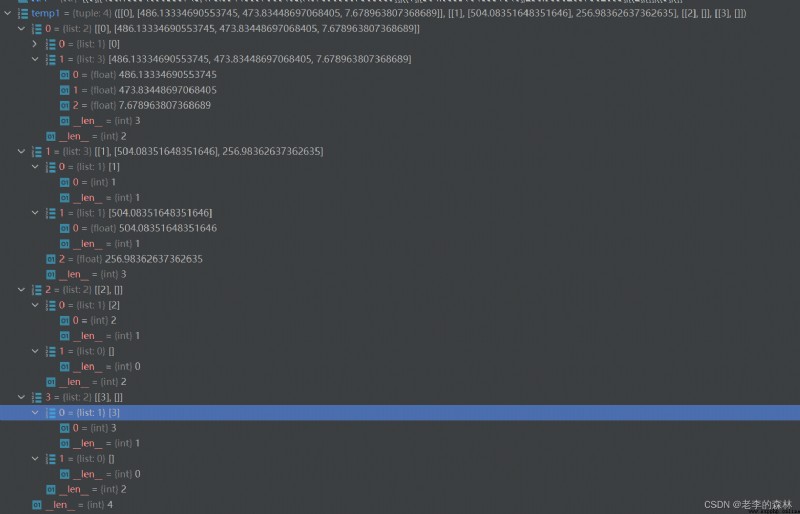
The following is a description of the regular expression:p>
re.sub('([^\u0030-\u0039\u005b\]\u002c\u002e])', '', str0)sub means to extract a subset
\u0030-\u0039 means the section 30 to 39 in the ASCII code, that is, the numbers 0~9
\u005b means the left square bracket [
and the right square bracket cannotIn this way, it needs to be escaped, that is, ]
\u002c is a comma,
\u002e is a decimal point.