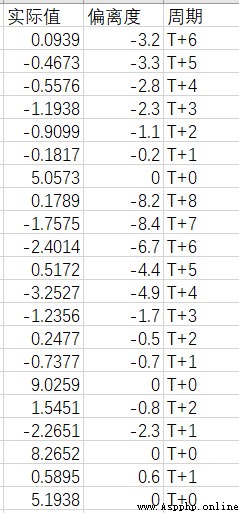
在做數據分析時,因實際數據量較大,請問有什麼方法可以實現自動在給定參數范圍內得出概率的最優解,數據表結構如下圖
import pandas as pddata_A=pd.read_csv(r'E:\數據分析\數據.csv',encoding='gbk')#求符合“周期”為T+n,且“偏離度”介於x,y之間,所對應大於等於z的“實際值”,在全部“實際值”中出現的概率(PR)def get_PR(n,x,y,z): data_B=data_A[(data_A["周期"]=='T+'+str(n))&(data_A["偏離度"]<=x)&(data_A["偏離度"]>=y)] PR=len(data_B[data_B["實際值"]>=z])/len(data_A["實際值"]) return(PR)因為python剛學不久,我只找到了GridSearch好像可以解決參數調優,但網上的資料都是講算法的,沒有直觀直接應用函數的,所以不知道怎麼套用
因為實際數據較大,請問有什麼方法可以實現自動在給定參數(n,x,y,z)范圍內得出概率(PR)的最大值(或者記錄所有參數組合及相應的PR結果)比如給定n范圍1到5,x范圍0到5,y范圍-5到-1,z范圍0到3,自動計算z在取0 1 2 3時,PR數值最大對應的n,x,z的數值,感謝解答!
 The installation and the Request of Python library cannot import, You should consider upgrading via the Python -m PIP...
The installation and the Request of Python library cannot import, You should consider upgrading via the Python -m PIP...
Installation of Pythons Reques
 Introduction to Geek Programming Python - Lists, Tuples, Dictionaries 1/7
Introduction to Geek Programming Python - Lists, Tuples, Dictionaries 1/7
pythonThe most common data typ
 [Wu Sir] Django rest framework source code and actual combat_ Day02 (top)
[Wu Sir] Django rest framework source code and actual combat_ Day02 (top)
(0) Abstract # Course link 4 S