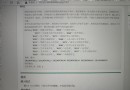
語法:
class xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
boostern_jobs 並行線程數scale_pos_weight
正樣本的權重,在二分類任務中,當正負樣本比例失衡時,設置正樣本的權重,模型效果更好。例如,當正負樣本比例為1:10時,scale_pos_weight=10。
n_estimatores
含義:總共迭代的次數,即決策樹的個數
調參:
max_depth
含義:樹的深度,默認值為6,典型值3-10。
調參:值越大,越容易過擬合;值越小,越容易欠擬合。
min_child_weight
含義:默認值為1,。
調參:值越大,越容易欠擬合;值越小,越容易過擬合(值較大時,避免模型學習到局部的特殊樣本)。
subsample
含義:訓練每棵樹時,使用的數據占全部訓練集的比例。默認值為1,典型值為0.5-1。
調參:防止overfitting。
colsample_bytree
含義:訓練每棵樹時,使用的特征占全部特征的比例。默認值為1,典型值為0.5-1。
調參:防止overfitting。
learning_rate
含義:學習率,控制每次迭代更新權重時的步長,默認0.3。
調參:值越小,訓練越慢。
典型值為0.01-0.2。
gamma
懲罰項系數,指定節點分裂所需的最小損失函數下降值。
調參:
alpha
L1正則化系數,默認為1
lambda
L2正則化系數,默認為1
pima-indians-diabetes.csv
印度的一個數據集,前面是各個類別的值,最後一列是標簽值,1代表糖尿病,0代表正常。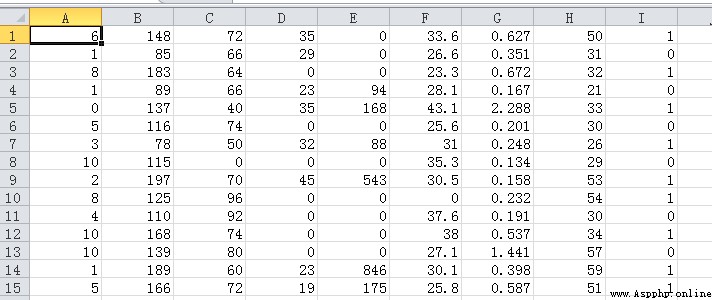
代碼:
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加載數據集
dataset = loadtxt('E:/file/pima-indians-diabetes.csv', delimiter=",")
# 將數據分為 數據和標簽
X = dataset[:,0:8]
Y = dataset[:,8]
# 劃分測試集和訓練集
seed = 7 # 隨機因子,能保證多次的隨機數據一致
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 訓練模型
model = XGBClassifier()
model.fit(X_train, y_train)
# 對模型做預測
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# 評估預測
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
測試記錄:
Accuracy: 74.02%
代碼:
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot as plt
# 加載數據集
dataset = loadtxt('E:/file/pima-indians-diabetes.csv', delimiter=",")
# 將數據分為 數據和標簽
X = dataset[:,0:8]
Y = dataset[:,8]
# 訓練模型
model = XGBClassifier()
model.fit(X, Y)
# 畫圖,畫出特征的重要性
plot_importance(model)
plt.show()
測試記錄: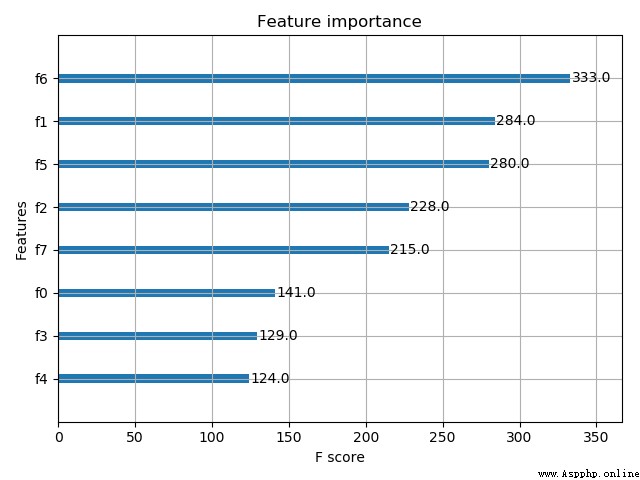
代碼:
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加載數據集
dataset = loadtxt('E:/file/pima-indians-diabetes.csv', delimiter=",")
# 將數據分為 數據和標簽
X = dataset[:,0:8]
Y = dataset[:,8]
# 劃分測試集和訓練集
seed = 7 # 隨機因子,能保證多次的隨機數據一致
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 訓練模型
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# 對模型做預測
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# 評估預測
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
測試記錄:
[0] validation_0-logloss:0.60491
[1] validation_0-logloss:0.55934
[2] validation_0-logloss:0.53068
[3] validation_0-logloss:0.51795
[4] validation_0-logloss:0.51153
[5] validation_0-logloss:0.50934
[6] validation_0-logloss:0.50818
[7] validation_0-logloss:0.51097
[8] validation_0-logloss:0.51760
[9] validation_0-logloss:0.51912
[10] validation_0-logloss:0.52503
[11] validation_0-logloss:0.52697
[12] validation_0-logloss:0.53335
[13] validation_0-logloss:0.53905
[14] validation_0-logloss:0.54545
[15] validation_0-logloss:0.54613
Accuracy: 74.41%
代碼:
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# 加載數據集
dataset = loadtxt('E:/file/pima-indians-diabetes.csv', delimiter=",")
# 將數據分為 數據和標簽
X = dataset[:,0:8]
Y = dataset[:,8]
# grid search 做交叉驗證
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# 匯總結果
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))
測試記錄:
Best: -0.530152 using {'learning_rate': 0.01}
-0.689563 with: {'learning_rate': 0.0001}
-0.660868 with: {'learning_rate': 0.001}
-0.530152 with: {'learning_rate': 0.01}
-0.552723 with: {'learning_rate': 0.1}
-0.653341 with: {'learning_rate': 0.2}
-0.718789 with: {'learning_rate': 0.3}