文件的序列化和反序列化
文件的序列化兩種方式
使用dumps()
#dumps()
#1創建一個文件
fp=open('test.txt','w')
# 2定義一個列表
name_list=['zs','ls']
#導入json模塊到該文件中
import json
#序列化
#將python對象編程json字符串
#我們在使用scrapy框架的時候,該框架會返回一個對象,我們要將對象寫入到文件中,就要使用json.dumps
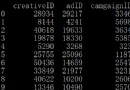
names=json.dumps(name_list)
print(names)
print(type(names))
#將names寫入到文件中
fp.write(names)
fp.close()
使用dump()
#dump
#在將對象轉換為字符串的同時,指定一個文件的對象 然後把轉換後的字符串寫入到這個文件裡
fp=open('test.txt','w')
name_list=['zs','ls']
import json
#相當於names=json.dumps(name_list) 和 fp.write(names)
json.dump(name_list,fp)
fp.close()
反序列化的兩種方式
使用loads()
#反序列化
# 將json的字符串變成一個python對象
fp=open('test.txt','r')
content=fp.read()
print(content)
print(type(content))
import json
#將json字符串變成python對象
result=json.loads(content)
print(result)
print(type(result))
使用load()
#load
fp=open('test.txt','r')
import json
result = json.load(fp)
print(result)
print(type(result))