一個人走得遠了,就會忘記自己為了什麼而出發,希望你可以不忘初心,不要隨波逐流,一直走下去
歡迎關注點贊收藏留言
本文由 程序喵正在路上 原創,CSDN首發!
系列專欄:Python爬蟲
首發時間:2022年7月31日
如果覺得博主的文章還不錯的話,希望小伙伴們三連支持一下哦

By writing program to crawl the Internet excellent resources,比如圖片、音頻、視頻、數據等等
爬蟲一定要用 Python 嗎?
不是的,用 Java 也行,用 C語言 也行,編程語言只是工具,The purpose of crawl data is you,As for what kind of tools to achieve a goal can be
Then why do most people like to use Python To write the crawler?
因為 Python 寫爬蟲簡單
在眾多編程語言中,Python For the small white to fit the fastest,語法最簡單,更重要的是 Python Have a lot of the crawler to third-party support library
首先,爬蟲在法律上是不被禁止的,That is to say the law is to allow the crawler exist,但是,The crawler also has the risk of illegal.技術是無罪的,Basically see you use it to do,For example some people use the crawler + Some hackers technology to the small broken every second stand lu one hundred and eight thousand times,那這個肯定是不被允許的
爬蟲分為善意的爬蟲和惡意的爬蟲:
綜上,In order to avoid Fried jing,We will place ji,Constantly optimize our crawlers to avoid interference to the normal operation of the site,And when using crawl to the data,發現涉及到用戶隱私和商業機密等敏感內容時,一定要及時終止爬取和傳播
反爬機制:
反反爬策略:
robots.txt 協議:
The development tools can be used:
We can get to use baidu to search the resources,And the crawler is by writing programs to simulate this a series of steps
需求:用程序模擬浏覽器,輸入一個網址,從該網址中獲取到資源或者內容
用 Python 搞定以上需求,特別簡單
在 Python 中,我們可以直接用 urllib Module to complete the simulation of the browser to work,具體代碼如下
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打開百度
print(resp.read().decode("utf-8")) # Print crawling to the content of the
是不是很簡單呢?
We can grab the html All content in written to the file,And then were compared with the original baidu,看看是否一致
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打開百度
with open("mybaidu.html", mode="w", encoding="utf-8") as f: # 創建文件
f.write(resp.read().decode("utf-8")) # 讀取到網頁的頁面源代碼,保存到文件中
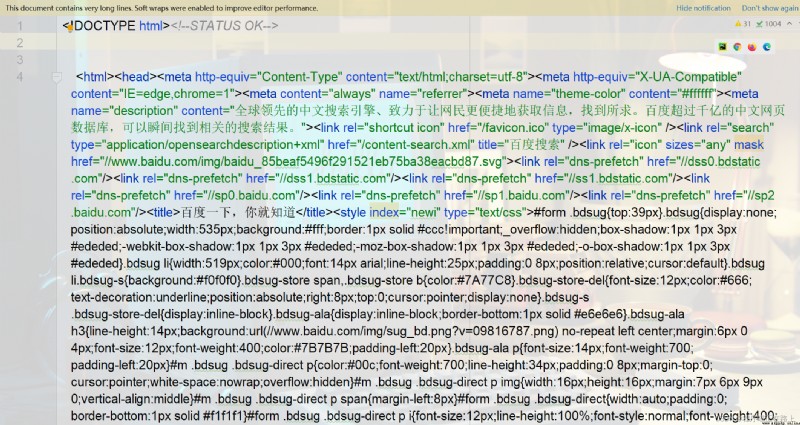
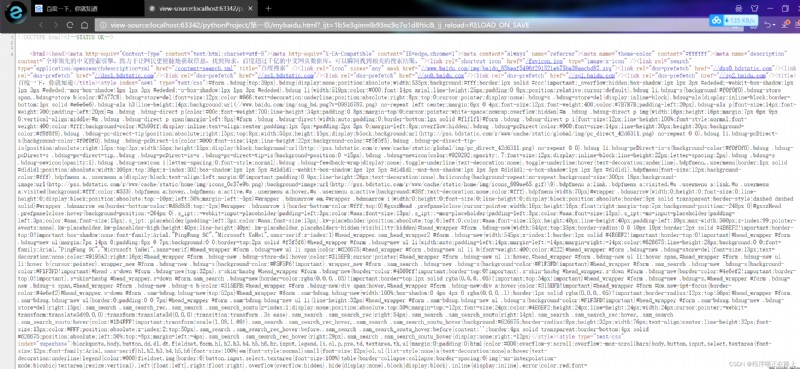
好的,So that we successfully from baidu crawl to a page on the source code,Just a few lines of code so simple
We implemented a web page in front of the whole scraping work,那麼下面我們來了解一下 web 請求的全部過程,Behind this helps we encounter all kinds of websites of the fundamental principles of
So what in our browser enter the url to the page we see the whole content of,這個過程中究竟發生了什麼?
這裡我們以百度為例,在訪問百度的時候,The browser will take this time baidu's request is sent to the server(Baidu a computer),由服務器接收到這個請求,Then load some data,返回給浏覽器,Again by the browser to display.聽起來好像是廢話…
但是,It contains a very important thing in it,注意,Baidu is not directly the server returned to the browser page,而是頁面源代碼(由 html、css、js 組成).Performed by the browser source code for the page,Then after the execution results show users
So all the data in the page source code?
Here we come to understand a new concept——頁面渲染
We have two kinds of common page rendering process:
服務器渲染
This is the most easy to understand, 也是最簡單的.Which means we are request to the server, Written to the server the data directly to all html 中, 我們浏覽器就能直接拿到帶有數據的 html 內容,比如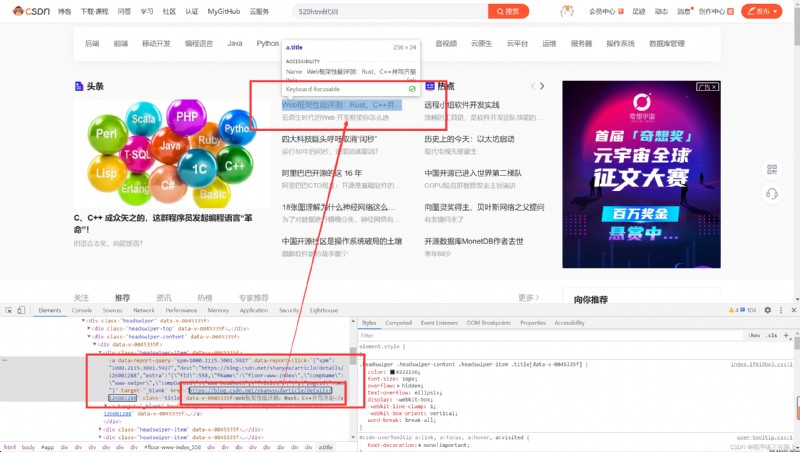
由於數據是直接寫在 html 中的,So we can see the data can is find in the page source code,這種網頁⼀Are relatively easy to grab to page content
前端JS渲染
這種就稍顯麻煩了,這種機制⼀般是第⼀次請求服務器返回⼀堆 HTML 框架結構,然後再次請求到真正保存數據的服務器,By the data returned from the server,Finally on the browser to load the data
在網頁按 F12 進入檢查,Then according to the following steps as you can see the server to get their data back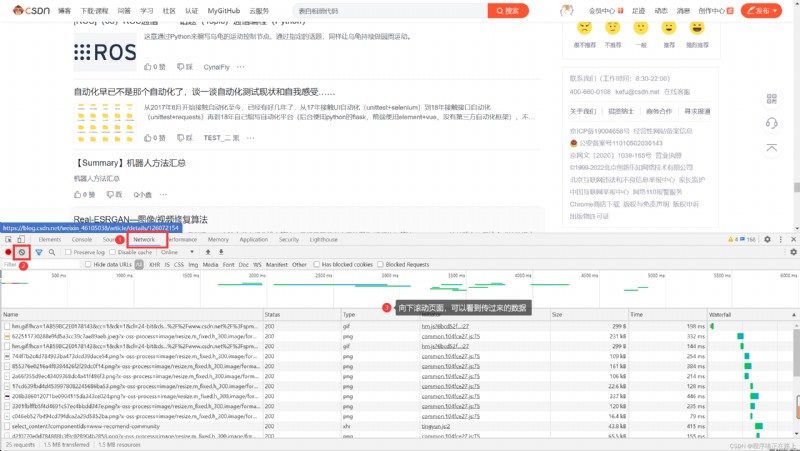

The advantage is the server side can relieve stress,而且分工明確,比較容易維護
To understand the two page rendering,我們不難看出,有些時候,我們的數據不⼀Its capital is directly from the source.If you can't find your data in the page source code, That probably data is stored in another⼀個請求裡
協議:Is between the two computers in order to be able to communicate smoothly and set⼀A gentleman's agreement.常見的協議有 TCP/IP、SOAP協議、HTTP協議、SMTP協議 等等
HTTP協議,全稱為 Hyper Text Transfer Protocol(超文本傳輸協議),是用於從萬維網(WWW:World Wide Web)服務器傳輸超文本到本地浏覽器的傳送協議.簡單來說,就是浏覽器和服務器之間的數據交互遵守的就是 HTTP協議
HTTP協議 把⼀Message is divided into three large pieces of content,無論是請求還是響應都是三塊內容
請求:
1 請求行 * 請求方式(get / host)請求url地址 協議
2 請求頭 * 放一些服務器要使用的附加信息
3 請求體 * 一般放一些請求參數
響應:
1 狀態行 * 協議 狀態碼
2 響應頭 * 放一些客戶端要使用的一些附加信息
3 響應體 * 服務器返回的真正客戶端要用的內容(HTML、json)等
In the back when we write the crawler request and reply headers are of greater concern,這兩個地方一般都隱含著一些比較重要的內容
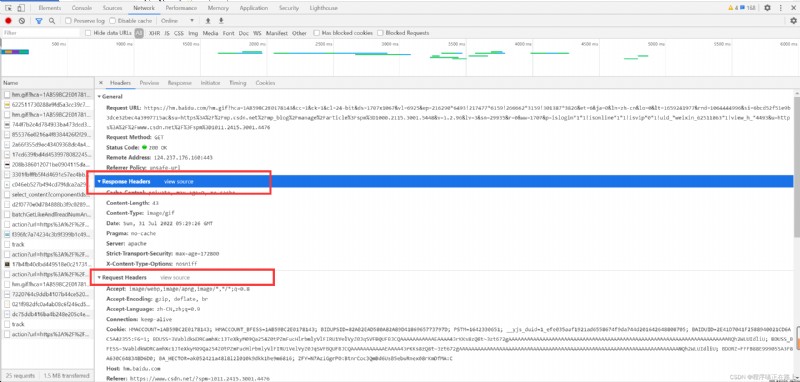
請求頭中最常見的一些重要內容(爬蟲需要):
響應頭中一些重要內容:
請求方式:
In front of the first crawler,我們使用 urllib To grab the page source code,這個是 Python 內置的一個模塊.但是,It is not our commonly used tools,Commonly used crawled page module typically use a third-party modules requests.The advantage of this module is better than urllib 還要簡單,And handles all requests more convenient
既然是第三方模塊,It needs us to the module to install,安裝方法如下:
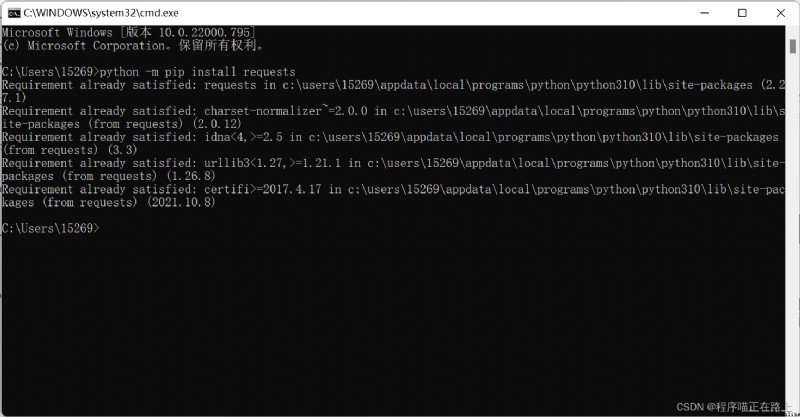
按 win + R 進入控制台,Then type the following command can be
python -m pip install requests
If installation is slow can convert domestic source to download and install:
python -m pip install -i http://pypi.tuna.tsinghua.edu.cn/simple requests
安裝完,接下來我們來看看 requests 能帶給我們什麼?
代碼實現:
# 案例1:Grab sogou search content
import requests
kw = input("請輸入你要搜索的內容:")
url = f"https://www.sogou.com/web?query={
kw}"
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/11"
}
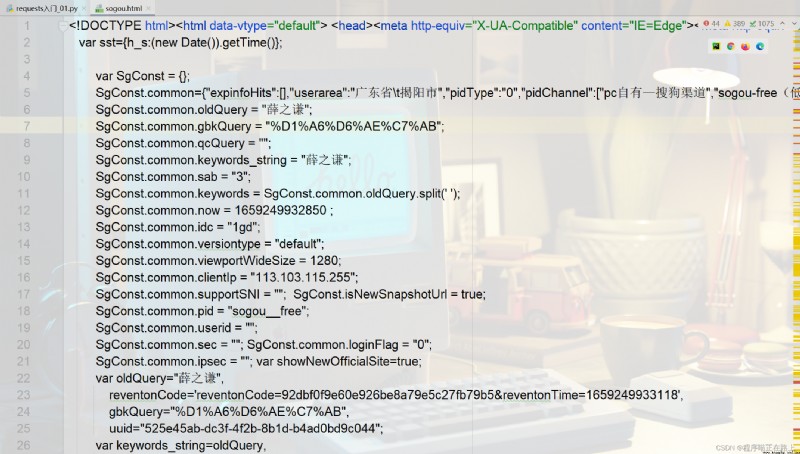
resp = requests.get(url, headers=dic) # 處理一個小小的反爬
with open("sogou.html", mode="w", encoding="utf-8") as f:
f.write(resp.text)
運行結果:
Next we see a case is a little more complicated
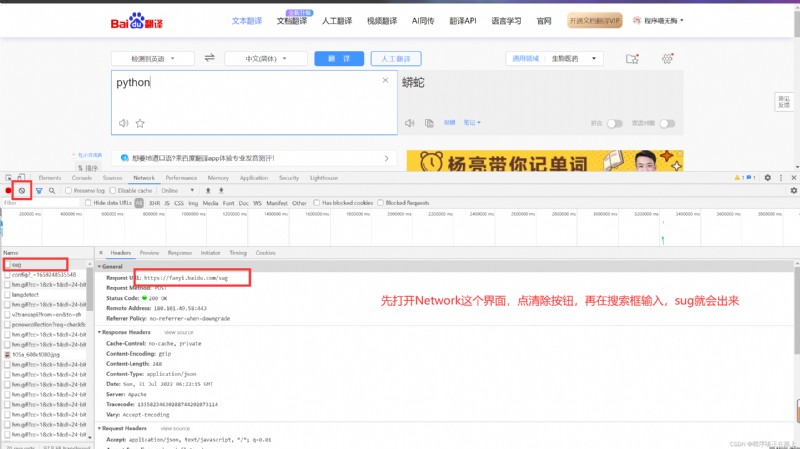
代碼實現:
import requests
# 准備參數
kw = input("Please enter your translation of the English words:")
url = "https://fanyi.baidu.com/sug"
dic = {
"kw": kw # And caught the parameters of the tool here to
}
# Please note that baidu translationsug這個url,它是通過postSubmitted in the form of,So we have to simulatepost請求
resp = requests.post(url, data=dic)
# 返回值是json,It can be parsed into directlyjson
resp_json = resp.json()
print(resp_json) # 直接打印看看,Easy to understand this statement
print(resp_json['data'][0]['v']) # Get returned by the contents of the dictionary
運行結果:
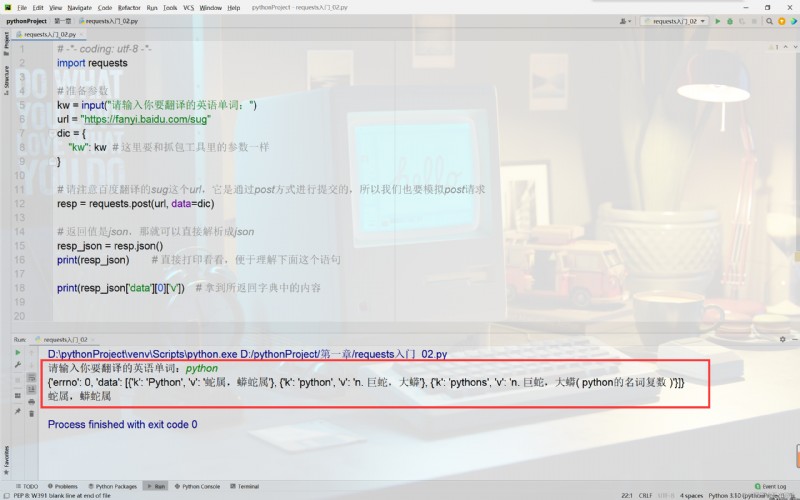
是不是很簡單?
Some sites in time will check your client request type,比如案例3
代碼實現:
import json
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 重新封裝參數
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
resp = requests.get(url=url, params=param, headers=headers)
list_data = resp.json()
print(list_data)
with open('douban.json', mode='w', encoding='utf-8') as f:
json.dump(list_data, fp=f, ensure_ascii=False)
print('over!!!')
運行結果:

🧸 這次的分享就到這裡啦,繼續加油哦^^
我是程序喵,With you a little bit of progress
有出錯的地方歡迎在評論區指出來,共同進步,謝謝啦