一個人走得遠了,就會忘記自己為了什麼而出發,希望你可以不忘初心,不要隨波逐流,一直走下去
歡迎關注點贊收藏留言
本文由 程序喵正在路上 原創,CSDN首發!
系列專欄:Python爬蟲
首發時間:2022年7月31日
如果覺得博主的文章還不錯的話,希望小伙伴們三連支持一下哦

通過編寫程序來爬取互聯網上的優秀資源,比如圖片、音頻、視頻、數據等等
爬蟲一定要用 Python 嗎?
不是的,用 Java 也行,用 C語言 也行,編程語言只是工具,爬取數據是你的目的,至於用什麼工具去達到目的都是可以的
那為什麼大多數人都喜歡用 Python 來寫爬蟲呢?
因為 Python 寫爬蟲簡單
在眾多編程語言中,Python 對小白來說上手最快,語法最簡單,更重要的是 Python 擁有非常多的關於爬蟲能用到的第三方支持庫
首先,爬蟲在法律上是不被禁止的,也就是說法律是允許爬蟲存在的,但是,爬蟲也具有違法風險的。技術是無罪的,主要看你用它來干嘛,比如說有些人利用爬蟲 + 一些黑客技術每秒鐘對著小破站撸上十萬八千次,那這個肯定是不被允許的
爬蟲分為善意的爬蟲和惡意的爬蟲:
綜上,為了避免煎精,我們還是要安分守紀,時常優化自己的爬蟲程序避免干擾到網站的正常運行,並且在使用爬取到的數據時,發現涉及到用戶隱私和商業機密等敏感內容時,一定要及時終止爬取和傳播
反爬機制:
反反爬策略:
robots.txt 協議:
可以使用的開發工具:
我們可以用百度來搜索得到想要的資源,而爬蟲就是通過編寫程序來模擬這一系列步驟
需求:用程序模擬浏覽器,輸入一個網址,從該網址中獲取到資源或者內容
用 Python 搞定以上需求,特別簡單
在 Python 中,我們可以直接用 urllib 模塊來完成對浏覽器的模擬工作,具體代碼如下
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打開百度
print(resp.read().decode("utf-8")) # 打印抓取到的內容
是不是很簡單呢?
我們可以把抓取到的 html 內容全部寫入文件中,然後和原版的百度進行對比,看看是否一致
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打開百度
with open("mybaidu.html", mode="w", encoding="utf-8") as f: # 創建文件
f.write(resp.read().decode("utf-8")) # 讀取到網頁的頁面源代碼,保存到文件中
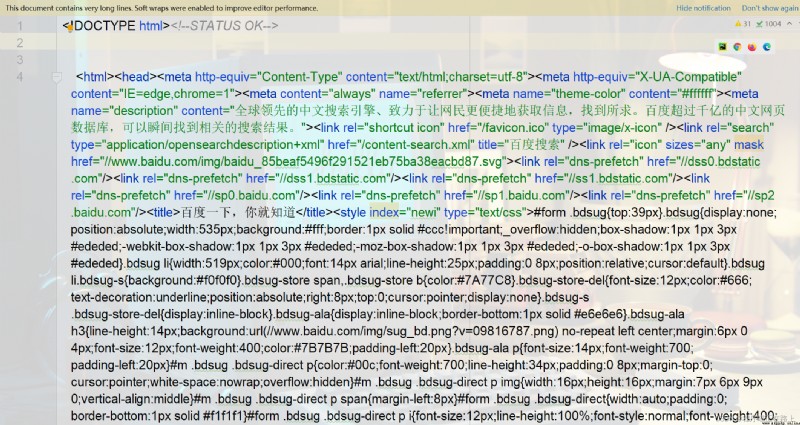
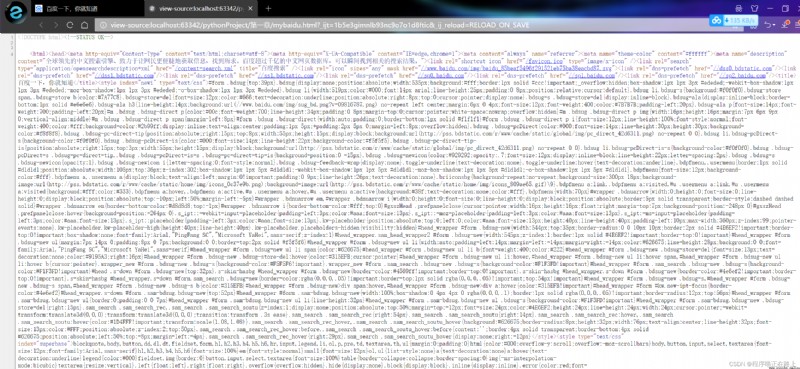
好的,這樣我們就成功地從百度上爬取到了一個頁面的源代碼,就是幾行代碼這麼簡單
前面我們實現了一個網頁的整體抓取工作,那麼下面我們來了解一下 web 請求的全部過程,這樣有助於後面我們遇到各種各樣的網站時有入手的基本准則
那麼到底我們浏覽器在輸入完網址到我們看到網頁的整體內容,這個過程中究竟發生了什麼?
這裡我們以百度為例,在訪問百度的時候,浏覽器會把這一次請求發送到百度的服務器(百度的一台電腦),由服務器接收到這個請求,然後加載一些數據,返回給浏覽器,再由浏覽器進行顯示。聽起來好像是廢話…
但是,這裡面蘊含著一個極為重要的東西在裡面,注意,百度的服務器返回給浏覽器的不直接是頁面,而是頁面源代碼(由 html、css、js 組成)。由浏覽器把頁面源代碼進行執行,然後把執行之後的結果展示給用戶
那麼所有的數據都在頁面源代碼裡面嗎?
這裡我們來了解一個新的概念——頁面渲染
我們常見的頁面渲染過程有兩種:
服務器渲染
這個是最容易理解的, 也是最簡單的。意思就是我們在請求到服務器的時候, 服務器直接把數據全部寫入到 html 中, 我們浏覽器就能直接拿到帶有數據的 html 內容,比如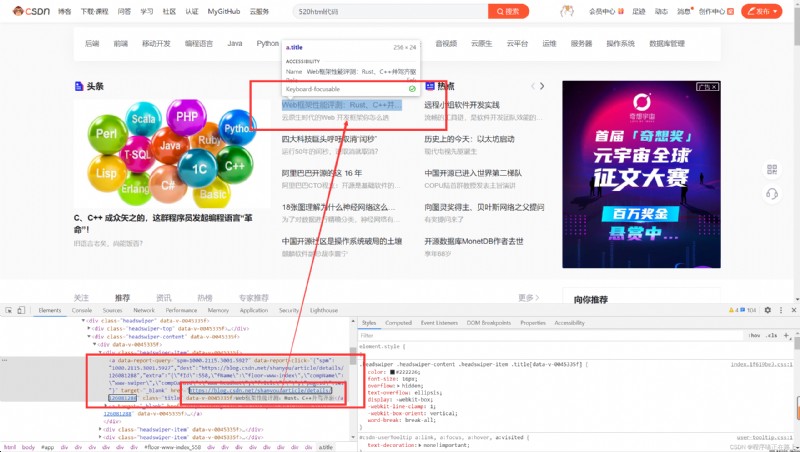
由於數據是直接寫在 html 中的,所以我們能看到的數據在頁面源代碼中能是找得到的,這種網頁⼀般都相對比較容易就能抓取到頁面內容
前端JS渲染
這種就稍顯麻煩了,這種機制⼀般是第⼀次請求服務器返回⼀堆 HTML 框架結構,然後再次請求到真正保存數據的服務器,由這個服務器返回數據,最後在浏覽器上對數據進行加載
在網頁按 F12 進入檢查,再按下列步驟可以看到服務器後面傳過來的數據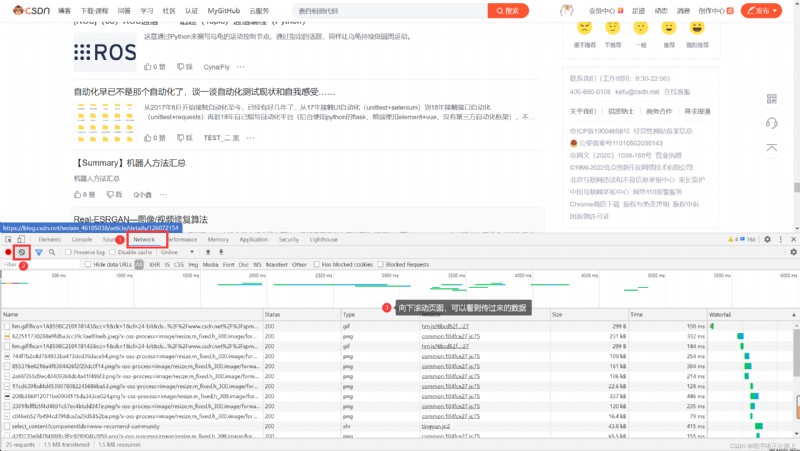

這樣做的好處是服務器那邊能緩解壓力,而且分工明確,比較容易維護
了解了兩種頁面渲染,我們不難看出,有些時候,我們的數據不⼀定都是直接來自於頁面源代碼。如果你在頁面源代碼中找不到你要的數據時, 那很可能數據是存放在另⼀個請求裡
協議:就是兩個計算機之間為了能夠流暢地進行溝通而設置的⼀個君子協定。常見的協議有 TCP/IP、SOAP協議、HTTP協議、SMTP協議 等等
HTTP協議,全稱為 Hyper Text Transfer Protocol(超文本傳輸協議),是用於從萬維網(WWW:World Wide Web)服務器傳輸超文本到本地浏覽器的傳送協議。簡單來說,就是浏覽器和服務器之間的數據交互遵守的就是 HTTP協議
HTTP協議 把⼀條消息分為三大塊內容,無論是請求還是響應都是三塊內容
請求:
1 請求行 * 請求方式(get / host)請求url地址 協議
2 請求頭 * 放一些服務器要使用的附加信息
3 請求體 * 一般放一些請求參數
響應:
1 狀態行 * 協議 狀態碼
2 響應頭 * 放一些客戶端要使用的一些附加信息
3 響應體 * 服務器返回的真正客戶端要用的內容(HTML、json)等
在後面我們寫爬蟲的時候要格外注意請求頭和響應頭,這兩個地方一般都隱含著一些比較重要的內容
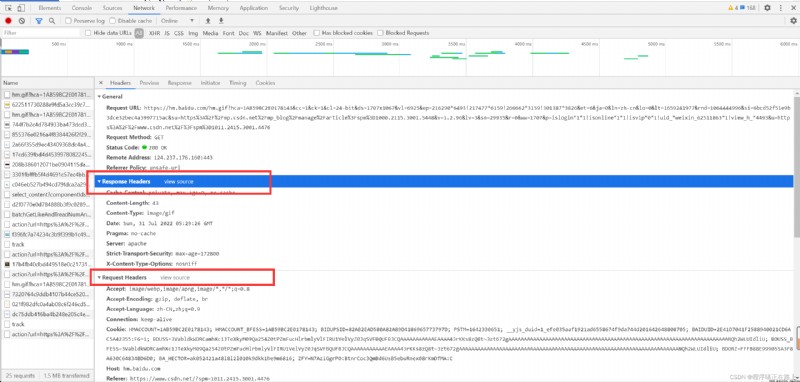
請求頭中最常見的一些重要內容(爬蟲需要):
響應頭中一些重要內容:
請求方式:
前面第一個爬蟲程序,我們使用 urllib 來抓取頁面源代碼,這個是 Python 內置的一個模塊。但是,它並不是我們常用的爬蟲工具,常用的抓取頁面的模塊通常使用一個第三方模塊 requests。這個模塊的優勢就是比 urllib 還要簡單,並且處理各種請求都比較方便
既然是第三方模塊,那就需要我們對該模塊進行安裝,安裝方法如下:
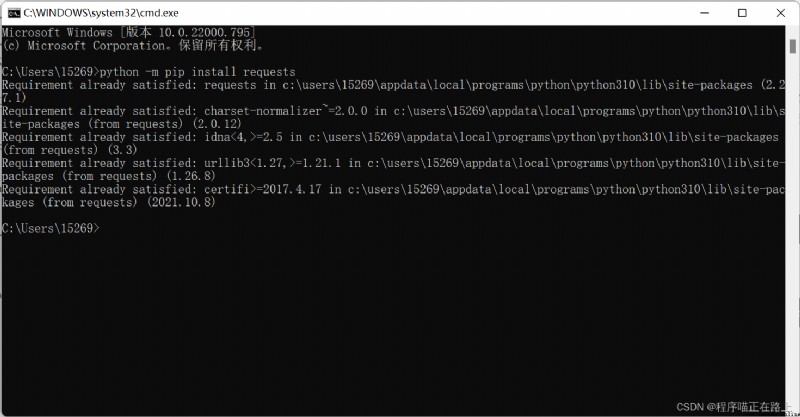
按 win + R 進入控制台,然後輸入下面這行命令即可
python -m pip install requests
如果安裝速度慢的話可以改用國內的源進行下載安裝:
python -m pip install -i http://pypi.tuna.tsinghua.edu.cn/simple requests
安裝完,接下來我們來看看 requests 能帶給我們什麼?
代碼實現:
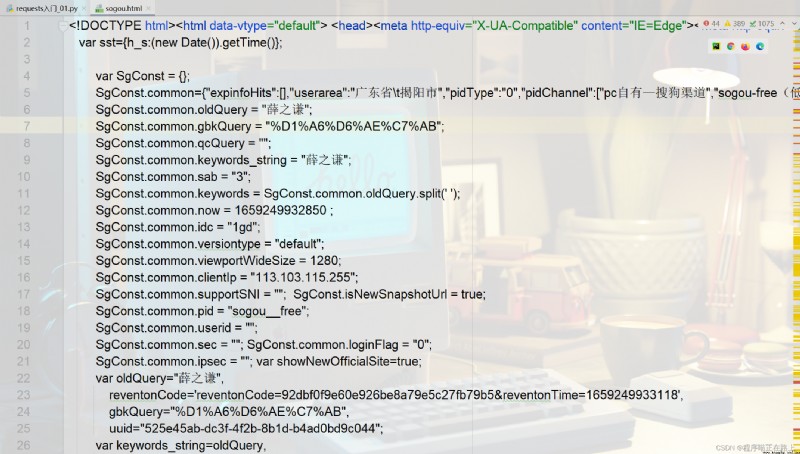
# 案例1:抓取搜狗搜索內容
import requests
kw = input("請輸入你要搜索的內容:")
url = f"https://www.sogou.com/web?query={
kw}"
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/11"
}
resp = requests.get(url, headers=dic) # 處理一個小小的反爬
with open("sogou.html", mode="w", encoding="utf-8") as f:
f.write(resp.text)
運行結果:
接下來我們看一個有一點點復雜的案例
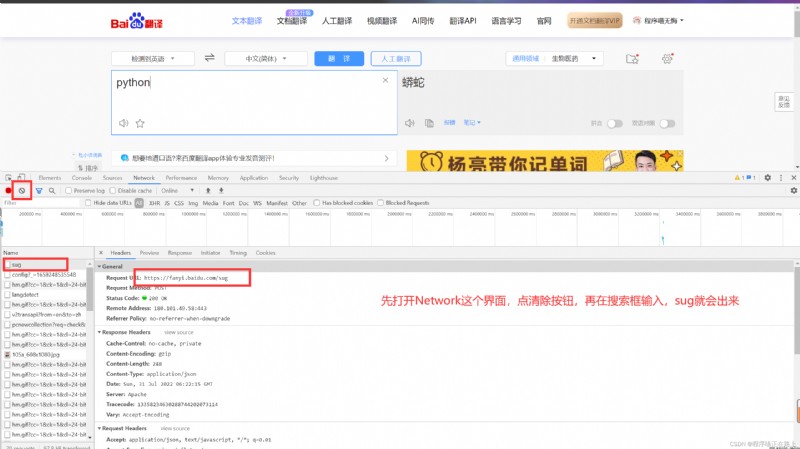
代碼實現:
import requests
# 准備參數
kw = input("請輸入你要翻譯的英語單詞:")
url = "https://fanyi.baidu.com/sug"
dic = {
"kw": kw # 這裡要和抓包工具裡的參數一樣
}
# 請注意百度翻譯的sug這個url,它是通過post方式進行提交的,所以我們也要模擬post請求
resp = requests.post(url, data=dic)
# 返回值是json,那就可以直接解析成json
resp_json = resp.json()
print(resp_json) # 直接打印看看,便於理解下面這個語句
print(resp_json['data'][0]['v']) # 拿到所返回字典中的內容
運行結果:
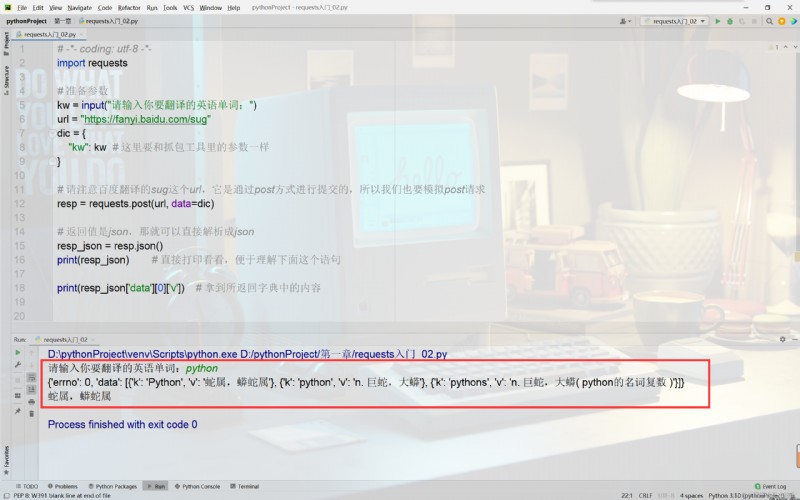
是不是很簡單?
還有一些網站在進行請求的時候會校驗你的客戶端型號,比如案例3
代碼實現:
import json
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 重新封裝參數
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
resp = requests.get(url=url, params=param, headers=headers)
list_data = resp.json()
print(list_data)
with open('douban.json', mode='w', encoding='utf-8') as f:
json.dump(list_data, fp=f, ensure_ascii=False)
print('over!!!')
運行結果:

🧸 這次的分享就到這裡啦,繼續加油哦^^
我是程序喵,陪你一點點進步
有出錯的地方歡迎在評論區指出來,共同進步,謝謝啦