前些天發現了一個巨牛的人工智能學習電子書,通俗易懂,風趣幽默,無廣告,忍不住分享一下給大家。(點擊跳轉人工智能學習資料)
說明:若需要數據附件及python源文件請移步微信公眾號“創享日記”,聯系作者有償獲取!
一、題目
一、題目
請統計附件hamlet.txt中出現的英文單詞情況,統計並輸出出現最多的10個單詞,注意:
(1)單詞不區分大小寫,即單詞的大小寫或組合形式一樣;
(2)請在文本中剔除如下特殊符號: !"#$%&()*+,- /:;<=>[email protected][]^. _'{}~;
(3)輸出10個單詞,每個單詞-行;
(4)輸出單詞為小寫形式。
二、題目分析
這道題首先可以通過read函數將文件中所有內容讀取出來然後通過lower函數將他們全都轉化為小寫字母。之後通過遍歷那一串特殊符號,通過replace函數將這些特殊符號轉化為空字符串,也就是變相剔除了。接下來剩下的都是一些單詞了,因為單詞之間以空格隔開,可以通過split方法將剩余的單詞轉化為列表,然後遍歷這個單詞列表,通過字典的特性,將單詞作為字典的鍵,單詞出現的次數作為字典的值。最後獲取字典的值,這時候,字典的值的從大到小的順序,就是所對應單詞的排序,我們通過lambda表達式對字典進行一個排序,然後循環輸出數量前十的值所對應的單詞即可。
三、代碼
dict={
}
with open("hamlet.txt","r")as file:
data=file.read()
data=data.lower()
for c in '!"#$%&()*+,-./:;<=>[email protected][\]^_‘{|}~':
data=data.replace(c,"")
data=data.replace("\n"," ")
total=data.split()
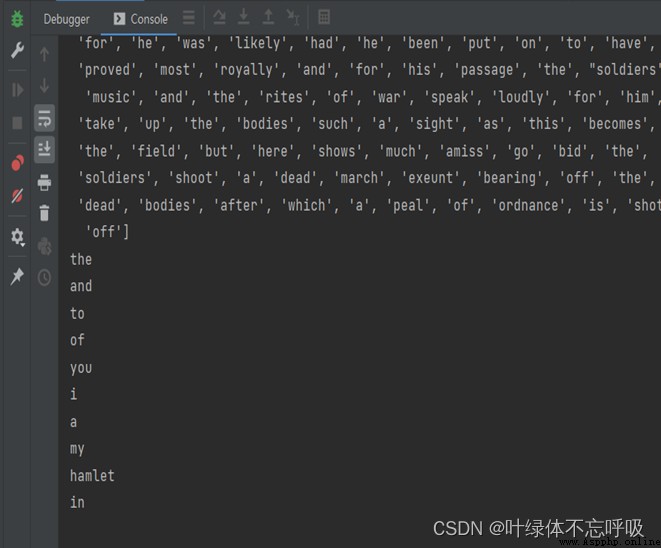
print(total)
for word in total:
dict[word]=dict.get(word,0)+1
items = list(dict.items())
items.sort(key = lambda x:x[1],reverse = True)
for i in range(10):
word,count= items[i]
print("{}".format(word))
四、實驗結果