.py directory has
1.xlsx, 2.xlsx, 3.xlsx
has a 1.txt, the content is
1
2
3
python readTake 1.txt and convert the corresponding xlsx to csv according to the content.
I now read the txt, store it in an array, and then read the array to convert xlsx. Only the last xlsx can be converted. When printing, it is 1, 2, 3, and the arrayOnly the last one, don't understand why
import numpy as np
import pandas as pd
i=0
with open('123.txt','r') as f:
for line in f.readlines():
line = line.strip().split()
i+=1
b =line[0:1]
lines = np.array(b)
print(lines)
for i in range(0,len(lines)):
print(lines[i])
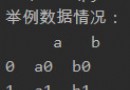
data = pd.read_excel('1.xlsx','Sheet1',index_col=0)
data.to_csv('data.csv',encoding='utf-8')