DataFrame.plot`(*kind='line'*)
kind : str,需要繪制圖形的種類
‘line’ : line plot (default)
‘bar’ : vertical bar plot
‘barh’ : horizontal bar plot
‘hist’ : histogram
‘pie’ : pie plot
‘scatter’ : scatter plot
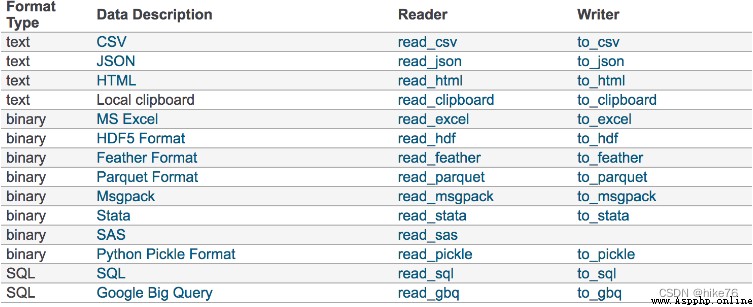
數據大部分存在於文件當中,所以pandas會支持復雜的IO操作,pandas的API支持眾多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
注:最常用的HDF5和CSV文件
pandas.read_csv(filepath_or_buffer, sep =‘,’, usecols )
filepath_or_buffer:文件路徑
sep :分隔符,默認用","隔開
usecols:指定讀取的列名,列表形式
讀取之前的股票的數據
# 讀取文件,並且指定只獲取'open', 'close'指標
data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close'])
open close
2018-02-27 23.53 24.16
2018-02-26 22.80 23.53
2018-02-23 22.88 22.82
2018-02-22 22.25 22.28
2018-02-14 21.49 21.92
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode=‘w’, encoding=None)
path_or_buf :文件路徑
sep :分隔符,默認用","隔開
columns :選擇需要的列索引
header :boolean or list of string, default True,是否寫進列索引值
index:是否寫進行索引
mode:‘w’:重寫, ‘a’ 追加
保存讀取出來的股票數據,保存’open’列的數據,然後讀取查看結果
# 選取前10行數據保存,便於觀察數據
data[:10].to_csv("./data/test.csv", columns=['open'])
# 讀取,查看結果
pd.read_csv("./data/test.csv")
Unnamed: 0 open
0 2018-02-27 23.53
1 2018-02-26 22.80
2 2018-02-23 22.88
3 2018-02-22 22.25
4 2018-02-14 21.49
5 2018-02-13 21.40
6 2018-02-12 20.70
7 2018-02-09 21.20
8 2018-02-08 21.79
9 2018-02-07 22.69
將索引存入到文件當中,變成單獨的一列數據。如果需要刪除,可以指定index參數,刪除原來的文件,重新保存一次。
# index:存儲不會將索引值變成一列數據
data[:10].to_csv("./data/test.csv", columns=['open'], index=False)
HDF5文件的讀取和存儲需要指定一個鍵,值為要存儲的DataFrame
pandas.read_hdf(path_or_buf,key =None,** kwargs),從h5文件當中讀取數據
path_or_buffer:文件路徑
key:讀取的鍵
return:Theselected object
DataFrame.to_hdf(path_or_buf, key, **kwargs)
# 讀取文件
day_close = pd.read_hdf("./data/day_close.h5")
# 存儲文件
day_close.to_hdf("./data/test.h5", key="day_close")
# 再次讀取的時候, 需要指定鍵的名字
new_close = pd.read_hdf("./data/test.h5", key="day_close")
注意:優先選擇使用HDF5文件存儲
JSON是常用的一種數據交換格式,前面在前後端的交互經常用到,也會在存儲的時候選擇這種格式。所以需要知道Pandas如何進行讀取和存儲JSON格式。
pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
將JSON格式准換成默認的Pandas DataFrame格式
orient : string,Indication of expected JSON string format.按照什麼方式進行讀取
‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]}
split 將索引對索引,列名對列名,數據對數據。將三部分都分開了
‘records’ : list like [{column -> value}, … , {column -> value}]
records 以
columns:values的形式輸出 ‘index’ : dict like {index -> {column -> value}}
index 以
index:{columns:values}...的形式輸出 ‘columns’ : dict like {column -> {index -> value}},默認該格式
colums 以
columns:{index:values}的形式輸出 ‘values’ : just the values array
values 直接輸出值
lines : boolean, default False,按照每行讀取json對象
typ : default ‘frame’, 指定轉換成的對象類型series或者dataframe
這裡使用一個新聞標題諷刺數據集,格式為json。is_sarcastic:1諷刺的,否則為0;headline:新聞報道的標題;article_link:鏈接到原始新聞文章。存儲格式為:
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
orient指定存儲的json格式,lines指定按照行去變成一個樣本
json_read = pd.read_json("./data/Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
將Pandas 對象存儲為json格式
path_or_buf=None:文件地址
orient:存儲的json形式,{‘split’,’records’,’index’,’columns’,’values’}
lines:一個對象存儲為一行
json_read.to_json("./data/test.json", orient='records')
結果為
[{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0},{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0},{
"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1},{
"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1},{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0},{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/advancing-the-worlds-women_b_6810038.html","headline":"advancing the world's women","is_sarcastic":0},....]
修改lines參數為True
json_read.to_json("./data/test.json", orient='records', lines=True)
結果為
{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0}
{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0}
{
"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1}
{
"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1}
{
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0}...
NaN為float類型
獲取缺失值的標記方式(NaN或者其他標記方式),如果缺失值的標記方式是NaN,則判斷數據中是否包含NaN:
存在缺失值nan:①刪除存在缺失值的:dropna(axis=‘rows’),不會修改原數據,需要接受返回值,②替換缺失值:fillna(value, inplace=True)
如果缺失值沒有使用NaN標記,比如使用"?",先替換“?”為np.nan,然後繼續處理
# 讀取電影數據
movie = pd.read_csv("./data/IMDB-Movie-Data.csv")
# 是缺失值返回true,否則返回false
pd.isnull(movie)
# 如果有一個缺失值,就返回true
np.any(pd.isnull(movie))
# 是缺失值返回false,否則返回true
pd.notnull(movie)
# 只要有一個缺失值,就返回false
np.all(pd.notnull(movie))
pandas刪除缺失值,使用dropna的前提是,缺失值的類型必須是np.nan
# 不修改原數據
movie.dropna()
# 可以定義新的變量接收或者用原來的變量名
data = movie.dropna()
# 替換存在缺失值的樣本的兩列
# 替換填充平均值,中位數
# Revenue (Millions)為要進行處理的列名
# fillna中第一個參數為替換成誰,第二個參數為是否對原值進行修改
# movie['Revenue (Millions)'].fillna(value=movie['Revenue (Millions)'].mean(), inplace=True)
替換所有列的缺失值:
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)
# 讀取文件
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
先替換“?”為np.nan
df.replace(to_replace=, value=)
to_replace:替換前的值
value:替換後的值
# 把一些其它值標記的缺失值,替換成np.nan
wis = wis.replace(to_replace='?', value=np.nan)
進行缺失值的處理
# 刪除
wis = wis.dropna()
連續屬性離散化的目的是為了簡化數據結構,數據離散化技術可以用來減少給定連續屬性值的個數。離散化方法經常作為數據挖掘的工具。
連續屬性的離散化就是在連續屬性的值域上,將值域劃分為若干個離散的區間,最後用不同的符號或整數值代表落在每個子區間中的屬性值。
離散化有很多種方法,這使用一種最簡單的方式去操作
這樣將數據分到了三個區間段,可以對應的標記為矮、中、高三個類別,最終要處理成一個"啞變量"矩陣
先讀取股票的數據,篩選出p_change數據
data = pd.read_csv("./data/stock_day.csv")
p_change= data['p_change']
使用的工具:
pd.qcut(data, q):
對數據進行分組將數據分組,一般會與value_counts搭配使用,統計每組的個數
series.value_counts():統計分組次數
# 自行分組
qcut = pd.qcut(p_change, q=10)
# 計算分到每個組數據個數
qcut.value_counts()
自定義區間分組:
# 自己指定分組區間
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
把每個類別生成一個布爾列,這些列中只有一列可以為這個樣本取值為1,其又被稱為熱編碼。
pandas.get_dummies(data, prefix=None)
data:array-like, Series, or DataFrame
prefix:分組名字
# 得出one-hot編碼矩陣
dummies = pd.get_dummies(p_counts, prefix="rise")
如果數據由多張表組成,那麼有時候需要將不同的內容合並在一起分析
pd.concat([data1, data2], axis=1)
按照行或列進行合並,axis=0為列索引,axis=1為行索引
# 按照行索引進行
pd.concat([data, dummies], axis=1)
pd.merge(left, right, how=‘inner’, on=None)
可以指定按照兩組數據的共同鍵值對合並或者左右各自
left: DataFrame
right: 另一個DataFrame
on: 按照哪個鍵進行拼接 how:按照什麼方式連接
leftLEFT OUTER JOINUse keys from left frame onlyrightRIGHT OUTER JOINUse keys from right frame onlyouterFULL OUTER JOINUse union of keys from both framesinnerINNER JOINUse intersection of keys from both frames# 創建左表
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
# 創建右表
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默認內連接
result = pd.merge(left, right, on=['key1', 'key2'])
結果如下:只有當K0和K1同時存在時才保留數據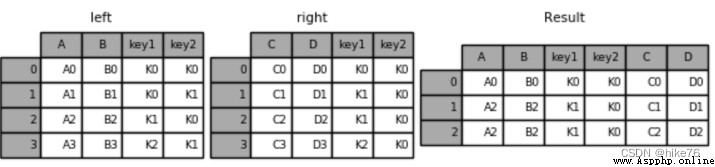
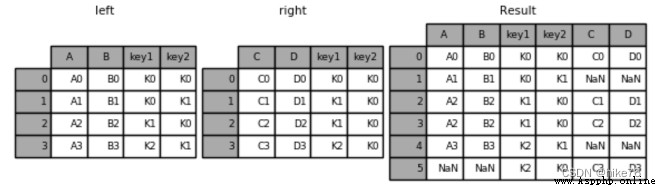
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
左連接結果: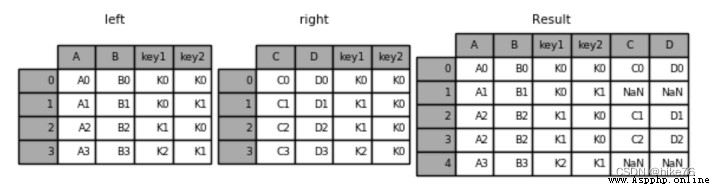
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
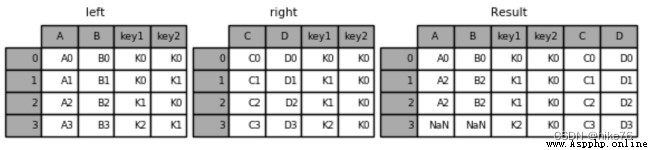
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
探索兩列數據之間存在的關系
交叉表用於計算一列數據對於另外一列數據的分組個數(用於統計分組頻率的特殊透視表)
pd.crosstab(value1, value2),返回具體的數量
透視表是將原有的DataFrame的列分別作為行索引和列索引,然後對指定的列應用聚集函數
data.pivot_table(),返回百分占比
DataFrame.pivot_table([], index=[])
# 尋找星期幾跟股票漲跌的關系
# 1、先把對應的日期找到星期幾
date = pd.to_datetime(data.index).weekday
data['week'] = date
# 2、假如把p_change按照大小去分類,0為界限
data['posi_neg'] = np.where(data['p_change'] > 0, 1, 0)
# 通過交叉表找尋兩列數據的關系
count = pd.crosstab(data['week'], data['posi_neg'])
對於每個星期一等的總天數求和,運用除法運算求出比例
# 算數運算,先求和
sum = count.sum(axis=1).astype(np.float32)
# 進行相除操作,得出比例
pro = count.div(sum, axis=0)
使用plot畫出這個比例,使用stacked的柱狀圖
pro.plot(kind='bar', stacked=True)
plt.show()
使用透視表,剛才的過程更加簡單
# 通過透視表,將整個過程變成更簡單一些
data.pivot_table(['posi_neg'], index='week')
分組與聚合通常是分析數據的一種方式,通常與一些統計函數一起使用,查看數據的分組情況
交叉表與透視表也有分組的功能,所以算是分組的一種形式,只不過他們主要是計算次數或者計算比例
類似於Hadoop中MapReduce對應的Map與Reduce階段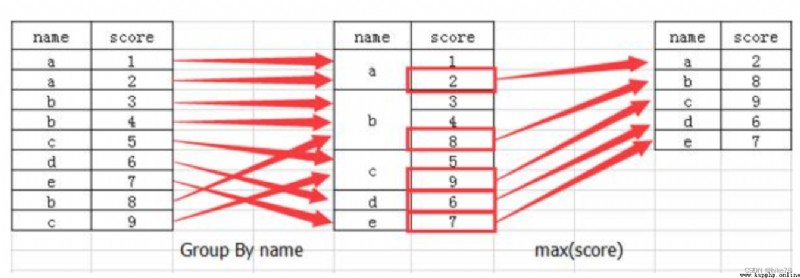
DataFrame.groupby(key, as_index=False)
key:分組的列數據,可以多個
col =pd.DataFrame({
'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
進行分組,對顏色分組,price進行聚合
# 分組,求平均值
col.groupby(['color'])['price1'].mean()
col['price1'].groupby(col['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
# 分組,數據的結構不變
col.groupby(['color'], as_index=False)['price1'].mean()
color price1
0 green 2.025
1 red 2.380
2 white 5.560
想知道美國的星巴克數量和中國的哪個多,或者想知道中國每個省份星巴克的數量的情況
數據來源:https://www.kaggle.com/starbucks/store-locations/data
# 導入星巴克店的數據
starbucks = pd.read_csv("./data/starbucks/directory.csv")
# 進行分組聚合
# 按照國家分組,求出每個國家的星巴克零售店數量
count = starbucks.groupby(['Country']).count()
# 繪制圖像
count['Brand'].plot(kind='bar', figsize=(20, 8))
plt.show()
# 降序排序,取前20個
count['Brand'].sort_values(ascending=False)[:20].plot(kind='bar', figsize=(20, 8))
# 加入省市一起進行分組
# 設置多個索引,set_index()
starbucks.groupby(['Country', 'State/Province']).count()
這個結構與MultiIndex結構類似
現在我們有一組從2006年到2016年1000部最流行的電影數據
數據來源:https://www.kaggle.com/damianpanek/sunday-eda/data
問題1:想知道這些電影數據中評分的平均分,導演的人數等信息,應該怎麼獲取?
問題2:對於這一組電影數據,如果想rating,runtime的分布情況,應該如何呈現數據?
問題3:對於這一組電影數據,如果希望統計電影分類(genre)的情況,應該如何處理數據?
首先獲取導入包,獲取數據
%matplotlib inline
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#文件的路徑
path = "./data/IMDB-Movie-Data.csv"
#讀取文件
df = pd.read_csv(path)
想知道這些電影數據中評分的平均分,導演的人數等信息,應該怎麼獲取?
得出評分的平均分,使用mean函數
df["Rating"].mean()
得出導演人數信息,求出唯一值,然後進行形狀獲取
## 導演的人數
# df["Director"].unique().shape[0]
np.unique(df["Director"]).shape[0]
644
對於這一組電影數據,如果想rating,runtime的分布情況,應該如何呈現數據?
以直方圖的形式,選擇分數列數據,進行plot,但是這種方法顯示的橫縱軸顯示不夠直觀
df["Rating"].plot(kind='hist',figsize=(20,8))
Rating進行分布展示,進行繪制直方圖
plt.figure(figsize=(20,8),dpi=80)
plt.hist(df["Rating"].values,bins=20)
plt.show()
修改刻度的間隔
# 增加x軸刻度,求出最大最小值
max_ = df["Rating"].max()
min_ = df["Rating"].min()
# 生成x刻度列表
t1 = np.linspace(min_,max_,num=21)
# [ 1.9 2.255 2.61 2.965 3.32 3.675 4.03 4.385 4.74 5.095 5.45 5.805 6.16 6.515 6.87 7.225 7.58 7.935 8.29 8.645 9. ]
# 修改刻度
plt.xticks(t1)
# 添加網格
plt.grid()
進行繪制直方圖
plt.figure(figsize=(20,8),dpi=80)
plt.hist(df["Runtime (Minutes)"].values,bins=20)
plt.show()
修改間隔
# 求出最大最小值
max_ = df["Runtime (Minutes)"].max()
min_ = df["Runtime (Minutes)"].min()
# # 生成刻度列表
t1 = np.linspace(min_,max_,num=21)
# 修改刻度
plt.xticks(np.linspace(min_,max_,num=21))
# 添加網格
plt.grid()
對於這一組電影數據,如果希望統計電影分類(genre)的情況,應該如何處理數據?
思路分析:
創建一個全為0的dataframe,列索引置為電影的分類,temp_df
# 進行字符串分割
temp_list = [i.split(",") for i in df["Genre"]]
# 獲取電影的分類
genre_list = np.unique([j for i in temp_list for j in i])
# 增加新的列,行為電影個數,列為分類個數
temp_df = pd.DataFrame(np.zeros([df.shape[0],genre_list.shape[0]]),columns=genre_list)
遍歷每一部電影,temp_df中把分類出現的列的值置為1
for i in range(1000):
#temp_list[i] ['Action','Adventure','Animation']
temp_df.ix[i,temp_list[i]]=1
print(temp_df.sum().sort_values())
求和,繪圖
temp_df.sum().sort_values(ascending=False).plot(kind="bar",figsize=(20,8),fontsize=20,colormap="cool")
Musical 5.0
Western 7.0
War 13.0
Music 16.0
Sport 18.0
History 29.0
Animation 49.0
Family 51.0
Biography 81.0
Fantasy 101.0
Mystery 106.0
Horror 119.0
Sci-Fi 120.0
Romance 141.0
Crime 150.0
Thriller 195.0
Adventure 259.0
Comedy 279.0
Action 303.0
Drama 513.0
dtype: float64