時隔這麼久, Kaggle 終於推出了新的表格數據競賽,一開始大家都很興奮。直到他們沒有。當 Kagglers 發現數據集有 50 GB 大時,社區開始討論如何處理如此大的數據集.
CSV 文件格式需要很長時間來寫入和讀取大型數據集,並且除非明確告知,否則不會記住數據類型。
除了通過減少數據類型來減少所需的磁盤空間之外,問題在於在工作會話之間以哪種格式保存修改後的數據集。CSV 文件格式需要很長時間來寫入和讀取大型數據集,並且除非明確告知,否則不會記住列的數據類型。本文探討了處理大型數據集的 CSV 文件格式的四種替代方案:Pickle、Feather、Parquet 和 HDF5。此外,我們將研究這些帶有壓縮的文件格式。
為了進行基准測試,我們將創建一個虛構的數據集。這個虛構的數據集包含每種數據類型的一列,但以下例外:具有數據類型的列在此示例float16中categorical被省略,因為 parquet 不支持float16而 HDF5format = "table"不支持categorical。為了減少可比性的時序噪聲,這個虛構的數據集包含 10,000,000 行,並且如 [8] 中所建議的幾乎 1GB 大。
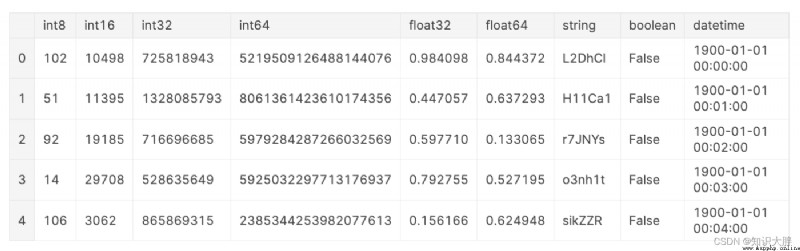
數據的特性會影響讀取和寫入時間,例如數據類型、DataFrame 的寬度(列數)與長度(行數)。但是,這超出了本文的范圍。為了進一步閱讀,我推薦以下資源: