pandas庫的函數令人眼花缭亂,現實中的復雜問題難免使人手足無措。如果你剛開始使用pandas,遇到報錯是很正常的,即使正確地進行了修復,下次遇到類似的問題時你可能已經遺忘了先前的解決方案,這樣的情況聽上去令人有些沮喪。因此推薦你閱讀《pandas數據處理與分析》,本書前 3 個部分劃分為“1+4+4”的模塊結構, 即“pandas 基礎”+ “4 類 pandas 操作”+“4 類 pandas 數據”,在每個模塊中總結了函數之間的邏輯關系,從而展示出 數據處理的宏觀體系。除了數據處理,還要對數據進行分析,因此在先前的結構之上,讀者還應 該掌握 3 個問題的解決方案,即“怎麼分析”“怎麼處理”“怎麼加速”,這對應“數據觀測”“特 征工程”和“性能優化”這 3 個知識模塊。
數據處理與分析是實戰型任務,讀者需要通過一些高質量的練習來鞏固所學知識。因此, 本 書配備了一定數量的習題,這些習題能夠幫助讀者理解、強化和拓展書中介紹的內容。

《pandas數據處理與分析》(耿遠昊)【摘要 書評 試讀】- 京東圖書item.jd.com/13268767.html正在上傳…重新上傳取消
實戰式pandas教程,梳理pandas中常用的函數,結合大量代碼講解理論知識,展示數據處理的宏觀體系,提供高質量的練習,幫助讀者理解、強化和拓展所學知識。
基於Pandas官方推薦中文教程Joyful Pandas,實戰式Pandas教程“熊貓書”。
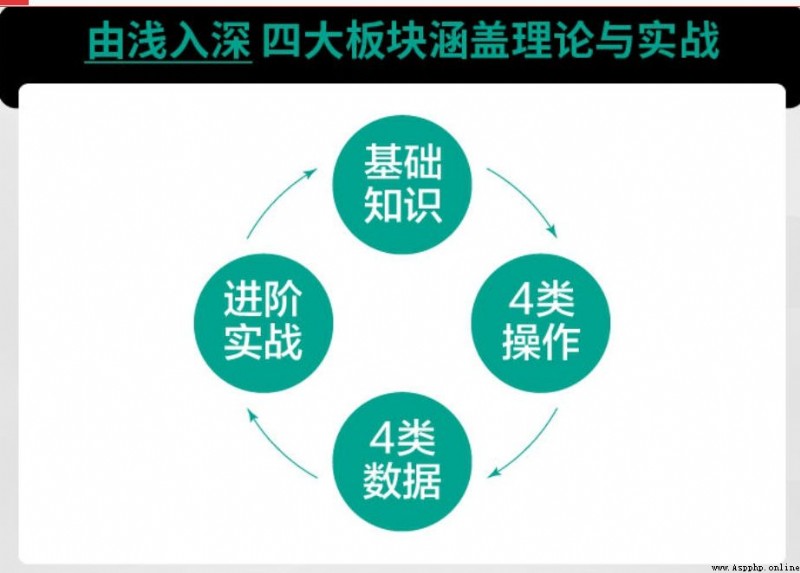
本書共包含13章,第一部分介紹NumPy和pandas的基本內容;第二部分介紹pandas庫中的4類操作,包括索引、分組、變形和連接;第三部分介紹基於pandas庫的4類數據,包括缺失數據、文本數據、分類數據和時間序列數據,並介紹這4類數據的處理方法;第四部分介紹數據觀測、特征工程和性能優化的相關內容。本書以豐富的練習為特色,每章的最後一節為習題,同時每章包含許多即時性的練習(練一練)。讀者可通過這些練習將對數據科學的宏觀認識運用到實踐中。
pandas是Python數據科學生態中一個核心的第三方庫。使用pandas,我們能夠快捷、高效地解決現實中各類與數據相關的問題。本書全面講解了基於pandas的數據處理與分析技術,理論與實踐相結合,是學習pandas的優秀教程。
——張日權 華東師范大學經濟與管理學部統計學院院長,教授、博士生導師
Python作為數字經濟時代最受歡迎的編程語言之一,正成為廣大有志於投身數據科學領域的青年學子必學的技術。“Joyful Pandas”是Datawhale社區的開源項目,也是pandas官方目前唯一推薦的中文教程,本書在該教程的基礎上進一步完善,強化理論與實踐的結合,對Python初學者和進階者均有裨益。
—— 陳海強 廈門大學王亞南經濟研究院教授、博士生導師
數據分析能力正逐步成為 數字化發展浪潮中學習者應具備的基本技能。本書分為“基礎知識”“4類操作”“4類數據”和“進階實戰”四大部分,結合簡潔易懂的代碼示例,涵蓋pandas的所有核心操作與特性,非常適合數據分析人員自學。
——黃鹂強 浙江大學數據科學系教授、博士生導師
本書並不要求讀者對數據科學或數據分析有先驗認識,只需具備基本的 Python 語法知識。本書也適用於有一些 pandas 基礎且想要系統學習數據處理與分析方法的讀者。對於已經對 pandas 和數據科學有一定了解的讀者,閱讀本書也能夠起到鞏固和拓展知識的作用。
本書分為基礎知識(第 1 章~第 2 章)、4 類操作(第 3 章~第 6 章)、4 類數據(第 7 章~第 10 章)和進階實戰(第 11 章~第 13 章)4 個部分。
第一部分包含 Python 基礎、NumPy 基礎和 pandas 基礎。其中,Python 基礎回顧推導式、匿 名函數和打包函數的概念與應用;NumPy 基礎包含常見的數組操作, 如構造、變形、切片、廣播
機制以及常用函數。pandas 基礎包含文件的讀取和寫入、基本數據結構、常用基本函數以及窗口 對象。
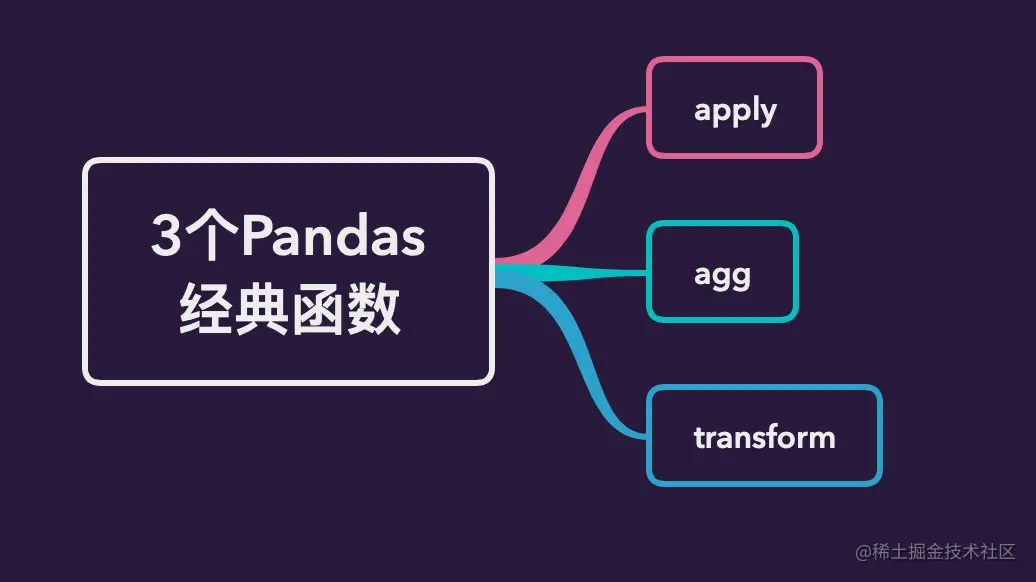
第二部分介紹索引、分組、變形和連接這 4 類操作。其中,第 3 章涵蓋單級索引、多級索引 和常用索引方法;第 4 章介紹分組模式及其對象的基本概念、聚合函數的使用方法、變換函數和 過濾函數的用法,以及跨列分組的相關內容;第 5 章討論長寬表的變形和其他變形方法;第 6 章 涉及關系連接的基本概念、常用關系連接函數和其他連接函數等。
第三部分介紹缺失數據、文本數據、分類數據和時間序列數據這 4 類數據。其中,第 7 章涉 及缺失數據的四大操作—統計、刪除、填充、插值,以及對 Nullable 類型的詳細解讀;第 8 章 涵蓋 str 對象、正則表達式基礎、文本處理的5 類操作—拆分、合並、匹配、替換、提取,以及 常用字符串函數;第 9 章涉及 cat 對象、有序類別以及區間類別;第 10 章涵蓋時間戳、時間差、 日期偏置和時間序列操作的內容。
第四部分包含數據觀測、特征工程和性能優化的內容。第 11 章介紹可視化的基本方法以及數 據觀測的一般思路。第 12 章介紹單特征構造、多特征構造和特征選擇的常用方法。第 13 章介紹 pandas 代碼編寫的注意事項、基於多進程的加速方法、基於 Cython 的加速方法以及基於 Numba 的加速方法。