本文已參與「新人創作禮」活動,一起開啟掘金創作之路.
它是一個生成模型,through the given sample data,Get the probability of each feature appearing in each sample,From this, the joint probability is calculated,Determine which category is more likely to appear,It can be used for multi-classification problems
It is based on conditional probability

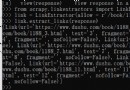
The training data and test data are stored separately in TextData.txt和ceshiData.txt文件中.

TextData.txt
C、J表示標簽

ceshiData.txt

帶有CThere are tags in this category8個單詞,其中包含Chinese5個,Beijing1個,Shanghai1個,Macao1個
帶有JThere are tags in this category3個單詞,其中包含Chinese1個,Tokyo1個,Japan1個
So the features of all categories in the whole data are :Chinese、Beijing、Shanghai、Macao、Tokyo、Japan,總共6個特征.
接下來統計C標簽、J標簽以及6The number of times a feature appears in the entire document
Then use Laplace smoothing to calculate the probability of each feature appearing under each category
最後進行預測
導入數據函數:
def loadDataSetx(fileName):
dataMat=[]
fr=open(fileName)
# 一行一行地讀取數據
for line in fr.readlines():
# Convert the current row of data to a list
curLine=line.strip().split(' ')
# Extract the data and save it to dataMat中
dataMat.append(curLine)
return dataMat
復制代碼training data function:
def train(dataMat):
# Get the type of each set of data
allType_yuan=[]
for i in range(len(dataMat)):
allType_yuan.append(dataMat[i][-1])
# Remove duplicates in type
allType=list(set(allType_yuan))
allType_pinlv=[]
for i in range(len(allType)):
allType_pinlv.append(float(allType_yuan.count(allType[i])/len(allType_yuan)))
# print(allType_pinlv)
# All properties in the sample
attribute=[]
for i in range(len(dataMat)):
for j in range(1,len(dataMat[i])-1):
attribute.append(dataMat[i][j])
attribute=list(set(attribute))
# Raw data is divided by type
type_dataMat=[]
for i in range(len(allType)):
data=[]
data.append(allType[i])
for j in range(len(dataMat)):
if dataMat[j][-1]==allType[i]:
for k in range(1,len(dataMat[j])-1):
data.append(dataMat[j][k])
type_dataMat.append(data)
# print(type_dataMat)
# The frequency of occurrence of each word in each category,Laplace smoothing was used
attr_pinlv=[]
for i in range(len(allType)):
attr_pinlv_1={}
attr_pinlv_1['Type']=allType[i]
for j in range(len(attribute)):
attr_pinlv_1[attribute[j]]=float((type_dataMat[i].count(attribute[j])+1)/(len(attribute)+len(type_dataMat[i])-1))
attr_pinlv.append(attr_pinlv_1)
return allType_pinlv,attr_pinlv
復制代碼Test data function:
# 測試數據
def ceshi(fileName,allType_pinlv,attr_pinlv):
ceshi=loadDataSetx(fileName)
ceshi_result=[]
# 第i條測試數據
for i in range(len(ceshi)):
ceshi_result_1={}
for j in range(len(allType_pinlv)):
pinlv=1
# print(allType_pinlv[j])
pinlv*=allType_pinlv[j]
# print(pinlv)
yangben_data=attr_pinlv[j]
# the first in the test dataj個字符串
for k in range(1,len(ceshi[i])):
pinlv*=yangben_data[ceshi[i][k]]
ceshi_result_1[yangben_data['Type']]=pinlv
ceshi_result.append(ceshi_result_1)
print(ceshi_result)
for i in range(len(ceshi_result)):
maxPinlv=max(ceshi_result[i].values())
for key,value in ceshi_result[i].items():
if value==maxPinlv:
print('第'+str(i+1)+'The group data prediction category is :'+key)
break
復制代碼函數調用:
dataMat=loadDataSetx('TextData.txt')
allType_pinlv,attr_pinlv=train(dataMat)
print(allType_pinlv)
print(attr_pinlv)
ceshi('ceshiData.txt',allType_pinlv,attr_pinlv)
復制代碼