Recently I suddenly had some spare block time.So I realized some interesting papers idea, The most impressive of them is《Hierarchical Attention Networks for Document Classification》.I put the relevant code here:
今天,基本上所有的 NLP 方面的應用,如果想取得 state-of-art 的結果,就必須要經過 attention model 的加持.比如 machine translation, QA(question-answer), NLI(natural language inference), etc, etc…. 但是這裡有個問題: 傳統上的 attention 的應用,總是要求我們的 task 本身同時有源和目標的概念.比如在 machine translation 裡, 我們有源語言和目標語言,在 QA 裡我們有問題和答案,NLI 裡我們有 sentence pairs …… 而 Attention 常常被定義為目標和源的相關程度.
但是還有很多 task 不同時具有源和目標的概念.比如 document classification, 它只有原文,沒有目標語言/文章, 再比如 sentiment analysis(也可以看做是最簡單的一種 document classification),它也只有原文.那麼這種情況下 attention 如何展開呢? 這就需要一個變種的技術,叫 intra-attention(或者 self-attention), 顧名思義,就是原文自己內部的注意力機制.
intra-attention 有不同的做法.Like the previous paragraph Google 發的那篇《Attention is All You Need》,在 machine translation 這個任務中,通過把 attention 機制 formularize 成 Key-Value 的形式,It is natural to express the source language and the target language respectively intra-attention. The advantage of this is to create clarity within the sentence 1.語法修飾 2. Semantic referential relationship 方面的理解,This means better control over the structure and meaning of sentences.
As shown in the stolen picture below:
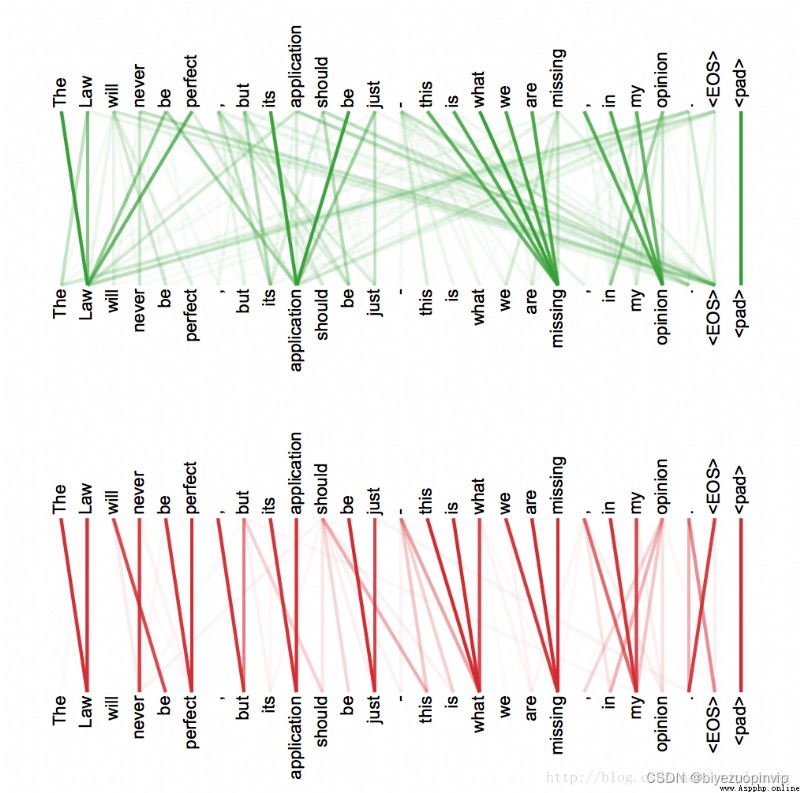
The above two figures represent the attention results of the projection of the original text in two different subspaces, respectively(See the original for details Google 的論文,The introduction here is omitted).We can see clear referential and modifier relationships.Introduced by the article self-attention 機制加上 positional embedding 的做法,May be a future development direction.
This paper takes a very different approach.它引入了 context vector Used to discover the importance of each word and each sentence.
It is based on this observation:
每個 document 由多個句子組成,而在決定文章的類型時,每個句子有不同的重要性.有的更相關一些,有的用處不大.比如說在一篇有關動物科學的文章中,某些句子和文章的主題相關性就很高.比如包含類似於“斑馬”或者“獵食者”,“偽裝”這樣詞語的句子.我們在建造模型時,最好能夠給這樣的句子更多的“attention”. 同樣的,對於每個句子而言,它所包含的每個詞語的重要性也不一樣,比如在 IMDB 的 review 中, 如 like, amazing, terrible Such words are more able to determine the sentence sentiment
所以,在分類任務中,如果我們給模型一篇文章,我們想問模型的問題是:1. 在這篇文章中,哪些句子更重要,能夠決定它的分類? 2. 在這篇文章的某個句子中,哪些詞語最重要,能夠影響句子在文章裡的重要性?
那麼,如何向模型提出這樣的問題呢? 或者說如何讓模型理解我們的意圖呢? 作者是通過引入 context vector 做到的.這個 context vector A little bit of a fairy tale feeling, The reason why I feel this way,是因為:
context vector 是人工引入的,它不屬於 task 的一部分.它是隨機初始化的.
它代替了 inter-attention 中目標語言/句子,能夠和 task 中的原文產生相互作用,計算出原文各個部分的相關程度,也就是我們關心的 attention.
它是 jointly learned. 也就是說,它本身,It is also learned !!
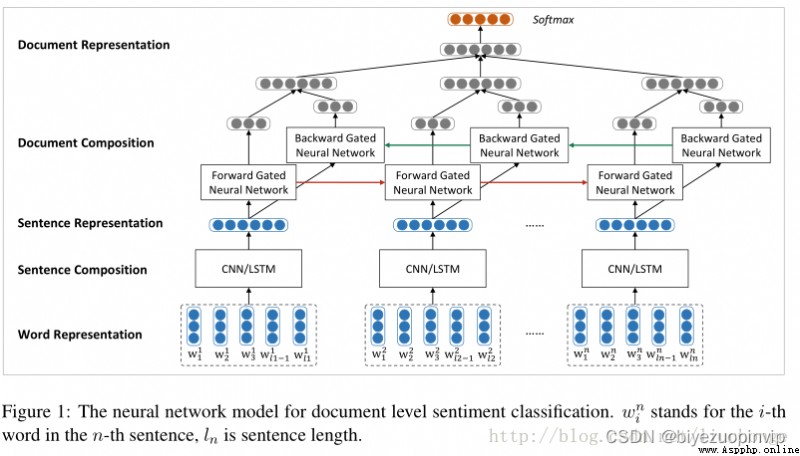
具體而言,網絡的架構如下:
網絡由四個部分組成:word sequence layer, word-attention layer, sentence sequence layer, and sentence-attention layer
If not in the picture uw(詞語級別的 context vector)和 us(句子級別的 context vector),There's nothing special about this model either.It is nothing more than by word sequence layer 和 sentence sequence layer 組成的一個簡單的層級的 sequence model only.And with these two context vector, We can use them to generate attention layer, Find the task relevance of each word and each sentence.
具體做法如下,for each sentence,用 sequence model, 就是雙向的 rnn to express,在這裡用的是 GRU cell.corresponding to each word hidden vector The output is transformed(affine+tanh)之後和 uwuw 相互作用(點積),The result is the weight of each word.After weighting, the whole can be generated sentence 的表示.From a high-level perspective(hierarchical 的由來),每個 document 有 L 個句子組成,那麼這 L sentences can be connected to form another sequence model, Also bidirectional GRU cell 的雙向 rnn,Similarly, the output layer is transformed and summed us 相互作用,Generate weights for each sentence,After weighting, we have a pair of whole document 的表示.最後用 softmax Predictions for classification can then be generated.
每次的“提問”,都是由 uw 和 us 來實現的,They are used to find high-weight words and sentences.下面看看實現.
下面是我用 tensorflow 的實現.具體見我的 github:
word-sequence 和 sentence-sequence All through the following module 實現.
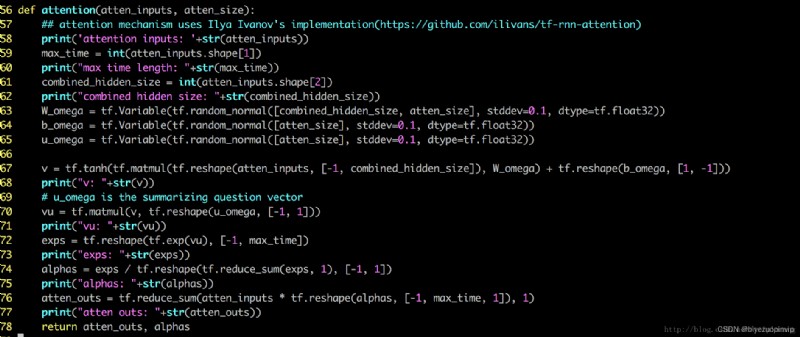
Bidirectional is used here dynamic 的 rnn,實際上 static 的 rnn 效果也不錯
不同的 IMDB 的 reviews 大小不一樣,Some contain dozens of sentences,Some contain only a few sentences, 為了讓 rnn Models are more accurate,我把每個 batch 內部的 review 的實際長度(review The number of sentences contained)存在了 seq_lens 裡面.這樣在調用 bidirectional_dynamic_rnn 時,rnn Know exactly where the computation should stop.
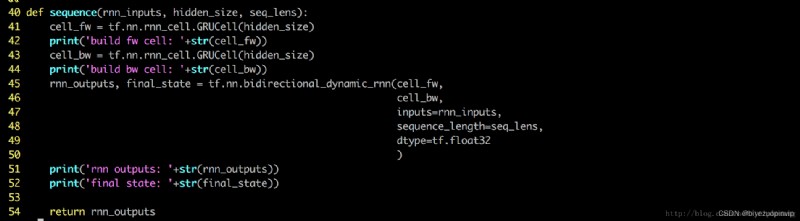
word-attention 和 sentence-attention All by calling this module 來實現
注意第 65 行 uw 就是我們說的 context vector (我在第 69 OK to call it summarizing question vector)
根據原 paper 的做法,利用 data 先 pretrain 了 word embeddings sequence 層之後加了 dropout, The use is not very obvious.
最大的 review 長度控制在 15 個句子, The length of each sentence is fixed 70.
The final approximate accuracy is 0.9 左右.I have very limited computing resources right now,So you can't experiment with too many other parameters.
以下是幾個例子.The depth in red represents the sentence for review 的 sentiment 的重要性,The depth of yellow represents the importance of the word to the sentence.
0 代表 negative, 1 代表 positive


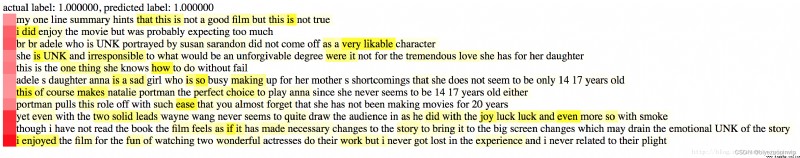
總結一下: 這種 intra-attention The mechanism is very creative,Also quite effective.Based on my incomplete experiments,hierarchical attention model Significantly better than other eg stacked bi-directional RNN, CNN text(Yoon Kim 的版本). Not entirely because I have very limited computing resources,I just implemented these models,There is no careful tuning, And I'm only right 2-class 的 IMDB experimented. So the above conclusion is not rigorous enough,僅供參考.
我當然相信 attention 的效果,But rather unbearable sequence model 的速度.Recent new breakthroughs(SRU)Possibly a substantial increase sequence model 的效率,But I still want to try it CNN+attention, The reason is that it is relatively optimistic CNN 的速度,而來 attention 可以一定程度上彌補 CNN Flaws in long-range correlations.
https://zhuanlan.zhihu.com/p/26892711
在 componet 裡面定義了 sequence 和 attention 兩個模塊
在 models 裡面 build graph 的時候,
先用一個 embeddings Vectorized word encoder for words,reshape 之後得到 word_rnn_inputs_formatted,作為 sequence 的輸入,
word_rnn_outputs = sequence(word_rnn_inputs_formatted, hidden_size, None)
在 sequence Bidirectional is used in the module GRU 網絡,Forward and reverse contextual information can be combined,Get the hidden layer output.
Then stitch the hidden layers together atten_inputs = tf.concat(word_rnn_outputs, 2),作為 attention 模塊的輸入.
The latter sentences are similar
oriented contextual information,Get the hidden layer output.
Then stitch the hidden layers together atten_inputs = tf.concat(word_rnn_outputs, 2),作為 attention 模塊的輸入.