給定數據集(txt文件),采用隨機梯度下降的方式進行神經網絡的學習,完成權重參數的更新,使得輸入的數據能夠接近輸出label。
關於BP神經網絡的手推和原理見筆者《CV學習筆記-推理和訓練》、《CV學習筆記-BP神經網絡》
txt文件類似下圖所示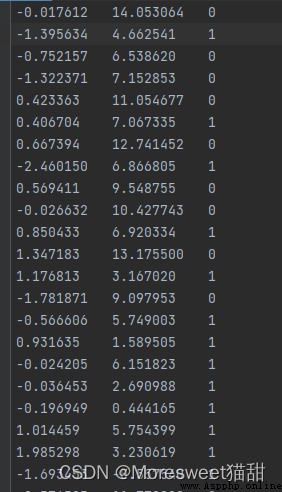
類:NeuralNetWork
類內初始化:__init__用以設置神經網絡的參數(輸入層參數、隱藏層參數、輸出層參數、學習率)
類內方法: train用於訓練數據,更新權重
讀取數據:loadDataSet用於在txt文件中讀取數據,包括輸入值和label值
隨機梯度下降處理:stocGradDescent用於處理訓練數據的過程
class NeuralNetWork:
def __init__(self, input_nodes, hidden_nodes, out_nodes, lr):
# 設置輸入個數
self.innodes = input_nodes
# 設置隱藏層節點個數
self.hnodes = hidden_nodes
# 設置輸出節點個數
self.onodes = out_nodes
# 設置學習率,用於反向更新
self.lr = lr
# self.weight_i2h = np.ones((self.hnodes, self.innodes))
# self.weight_h2o = np.ones((self.onodes, self.hnodes))
# 隨機初始化比1矩陣效果要好很多
# 權重矩陣(輸入到隱藏)
self.weight_i2h = (numpy.random.normal(0.0, pow(self.hnodes,-0.5), (self.hnodes,self.innodes) ) )
# 權重矩陣(隱藏到輸出)
self.weight_h2o = (numpy.random.normal(0.0, pow(self.onodes,-0.5), (self.onodes,self.hnodes) ) )
# 設置激活函數(sigmoid)
self.activation_function = lambda x: 1.0/(1+np.exp(-x))
pass
''' 訓練方法,輸入一次訓練的輸入和label '''
def train(self, inputs_list, targets_list):
inputs = numpy.array(inputs_list, ndmin=2).T
target = np.array(targets_list, ndmin=2).T
# wx+b
hidden_inputs = np.dot(self.weight_i2h, inputs)
# 激活作為隱藏層的輸出
hidden_outputs = self.activation_function(hidden_inputs)
# wx+b
o_inputs = np.dot(self.weight_h2o, hidden_outputs)
# 激活作為輸出
o_outputs = self.activation_function(o_inputs)
# 損失函數
loss = (target - o_outputs) ** 2 * 0.5
# 輸出誤差,用於反向更新
error = target - o_outputs
# error = target - o_outputs
# 隱藏層誤差,用於反向更新
hidden_error = np.dot(self.weight_h2o.T, error * o_outputs * (1 - o_outputs))
# 梯度
gradO = error * o_outputs * (1 - o_outputs)
# 反向更新,詳見筆者博客[《CV學習筆記-BP神經網絡》(https://blog.csdn.net/qq_38853759/article/details/121930413)
self.weight_h2o += self.lr * np.dot((error * o_outputs * (1 - o_outputs)), np.transpose(hidden_outputs))
gradI = hidden_error * hidden_outputs * (1 - hidden_outputs)
# 反向更新
self.weight_i2h += self.lr * np.dot((hidden_error * hidden_outputs * (1 - hidden_outputs)),
np.transpose(inputs))
return loss
def loadDataSet():
data = []
label = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
data.append([1.0, float(lineArr[0]), float(lineArr[1])])
label.append(int(lineArr[2]))
data = np.array(data)
label = np.array(label)
return data, label
def stocGradDescent(data, label):
m, n = np.shape(data)
for iter in range(200):
total_loss = 0
for i in range(m):
# if label[i] == 1:
# pass
# elif label[i] == 0:
# pass
# 累計每個epoch的loss觀察效果
total_loss += net.train(data[i], label[i])
print("NO.{} Loss={}".format(iter, total_loss))
import numpy
import numpy as np
class NeuralNetWork:
def __init__(self, input_nodes, hidden_nodes, out_nodes, lr):
self.innodes = input_nodes
self.hnodes = hidden_nodes
self.onodes = out_nodes
self.lr = lr
# self.weight_i2h = np.ones((self.hnodes, self.innodes))
# self.weight_h2o = np.ones((self.onodes, self.hnodes))
# 隨機初始化比1矩陣效果要好很多
self.weight_i2h = (numpy.random.normal(0.0, pow(self.hnodes,-0.5), (self.hnodes,self.innodes) ) )
self.weight_h2o = (numpy.random.normal(0.0, pow(self.onodes,-0.5), (self.onodes,self.hnodes) ) )
self.activation_function = lambda x: 1.0/(1+np.exp(-x))
pass
def train(self, inputs_list, targets_list):
inputs = numpy.array(inputs_list, ndmin=2).T
target = np.array(targets_list, ndmin=2).T
hidden_inputs = np.dot(self.weight_i2h, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
o_inputs = np.dot(self.weight_h2o, hidden_outputs)
o_outputs = self.activation_function(o_inputs)
loss = (target - o_outputs) ** 2 * 0.5
error = target - o_outputs
# error = target - o_outputs
hidden_error = np.dot(self.weight_h2o.T, error * o_outputs * (1 - o_outputs))
gradO = error * o_outputs * (1 - o_outputs)
self.weight_h2o += self.lr * np.dot((error * o_outputs * (1 - o_outputs)), np.transpose(hidden_outputs))
gradI = hidden_error * hidden_outputs * (1 - hidden_outputs)
self.weight_i2h += self.lr * np.dot((hidden_error * hidden_outputs * (1 - hidden_outputs)),
np.transpose(inputs))
return loss
# 從testSet.txt中讀取數據存儲至樣本集data和標簽集label
def loadDataSet():
data = []
label = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
data.append([1.0, float(lineArr[0]), float(lineArr[1])])
label.append(int(lineArr[2]))
data = np.array(data)
label = np.array(label)
return data, label
def stocGradDescent(data, label):
m, n = np.shape(data)
for iter in range(200):
total_loss = 0
for i in range(m):
# if label[i] == 1:
# pass
# elif label[i] == 0:
# pass
total_loss += net.train(data[i], label[i])
print("NO.{} Loss={}".format(iter, total_loss))
if __name__ == '__main__':
input_nodes = 3
hidden_nodes = 3
output_nodes = 1
learning_rate = 0.1
net = NeuralNetWork(input_nodes, hidden_nodes, output_nodes, learning_rate)
data, label = loadDataSet()
stocGradDescent(data, label)
print(net.weight_i2h)
print(net.weight_h2o)
pass
txt文本文件內容請自行復制
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0
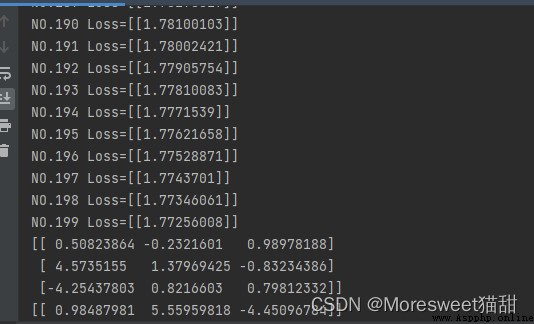
通過debug看效果:
可見剛開始網絡的輸出跟label的差距還是很大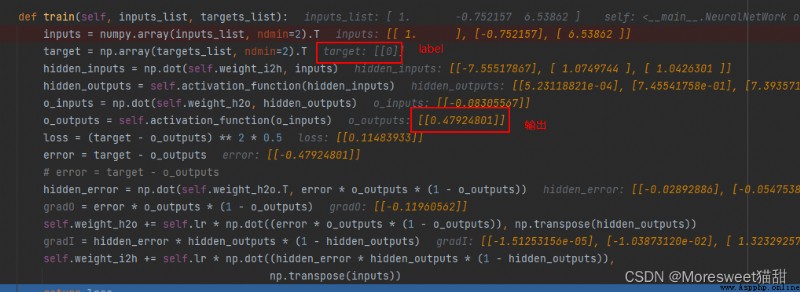
可以看到訓練到一百多代的時候loss已經有了明顯的下降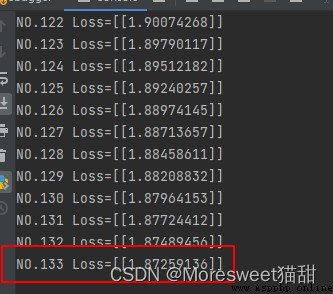
此時debug看效果,可以看到效果明顯改善,網絡的輸出已經比較小接近於真實label:0了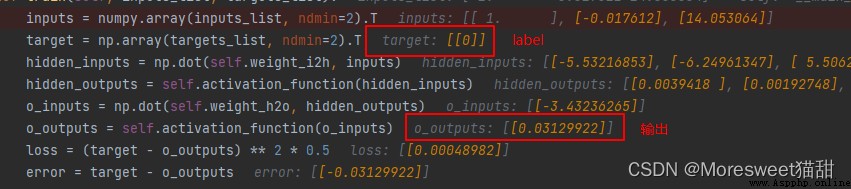
label為1的效果也靠譜很多了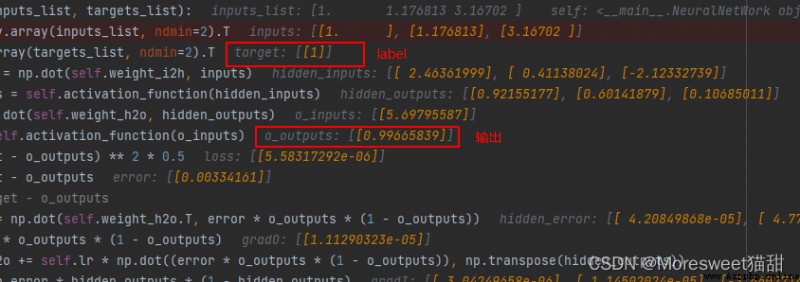
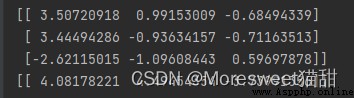
最後打印出權重參數: