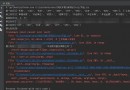
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsdef calc_distance(dataset, centroids):n, l = dataset.shapem, l = centroids.shapedataset = dataset.reshape(n, 1, l)centroids = centroids.reshape(1, m, l)sum = np.sum(np.square(dataset[..., :] - centroids[..., :]), axis=-1)distance = np. sqrt(sum)return distancedef kmeans(dataset, k):data_num = len(dataset)# The first column stores which cluster the sample belongs to# The second column stores the error of the sample to the center point of the clusterclusterAssment = np.zeros((data_num, 2))centroids = dataset[np.random.choice(data_num, k, replace=False)]last_nearest = np.zeros((data_num,))while True:distances = calc_distance(dataset, centroids)current_nearest = np.argmin(distances, axis=1)if (last_nearest == current_nearest).all():breakclusterAssment = np.hstack([np.expand_dims(current_nearest, axis=1),np.expand_dims(distances[np.arange(data_num), current_nearest], axis=1)])# update clusterfor idx in range(k):centroids[idx] = np.mean(dataset[current_nearest == idx], axis=0)last_nearest = current_nearestreturn centroids, clusterAssment