cv.findContours(img,mode,method)
mode:輪廓檢索模式
method:輪廓逼近方法
為了更高的准確率,使用二值圖像
image=cv.imread("E:\\Pec\\lan.jpg")
#轉化為灰度圖
gray=cv.cvtColor(image,cv.COLOR_BGR2GRAY)
#轉化為二值圖
ret,thresh=cv.threshold(gray,127,255,cv.THRESH_BINARY)
#返回值一:計算好或者設定好的阈值
#返回值二:處理好的圖像

#binary,contours,hierarchy=cv.findContours(,,)
#因為OpenCV庫的更新,會報錯“not enough values to unpack (expected 3, got 2)”
#把返回值從三個改成兩個即可(刪除第一個返回值)
contours,hierarchy=cv.findContours(thresh,cv.RETR_TREE,cv.CHAIN_APPROX_NONE)
#返回值一:輪廓信息
#返回值二:層級
#繪制圖像輪廓函數drawContours():圖像、輪廓信息、輪廓索引(需要多少輪廓,-1默認全部)、顏色模式、線條厚度
draw_img=image.copy()
res=cv.drawContours(draw_img,contours,-1,(0,255,0),2)
cv_show("res",res)

#輪廓特征
cnt=contours[0]#第0個輪廓
#面積
area=cv.contourArea(cnt)
print(area)
#周長,True表示閉合的輪廓圖像
girth=cv.arcLength(cnt,True)
print(girth)
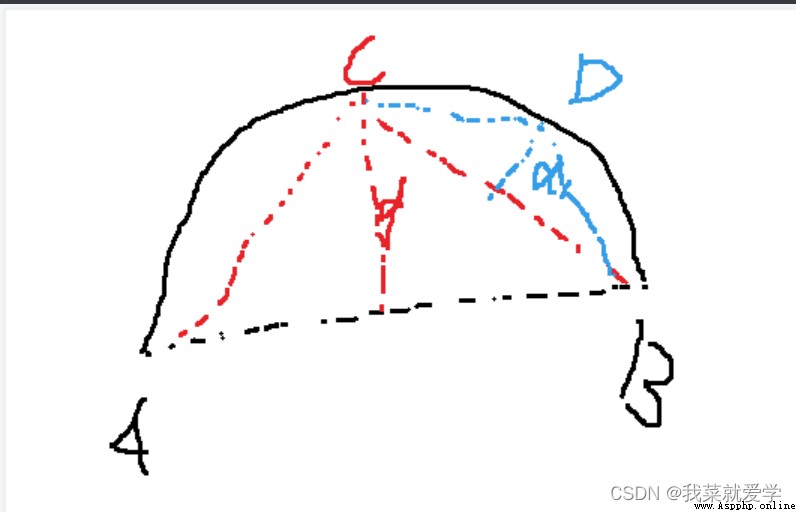
說明:曲線AB,假設C點是到直接AB最大的點,然後過C點做直線AB的垂直線d,若d點小於T(自己設置的阈值),直線AB可以取代曲線AB,若d大於T,不能取代,則同理在曲線CB取一點D,做D到直線CB的曲線,然後再比較阈值。。。。。
#輪廓近似
#二值圖獲取
img=cv.imread("E:\\Pec\\lunk.jpg")
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret,thresh=cv.threshold(gray,127,255,cv.THRESH_BINARY)
#獲取輪廓
contours,hierarchy=cv.findContours(thresh,cv.RETR_TREE,cv.CHAIN_APPROX_NONE)
cnt=contours[2]
draw_img=img.copy()
res=cv.drawContours(draw_img,contours,-1,(0,255,0),5)
cv_show("res",res)
#取近似
epsilon=0.15*cv.arcLength(cnt,True)#設置的比較阈值,一般是周長的百分比
#百分比越小,變化越不明顯
approx=cv.approxPolyDP(cnt,epsilon,True)#做近似
draw_img=img.copy()
res=cv.drawContours(draw_img,[approx],-1,(0,0,255),2)
cv_show("res",res)
img=cv.imread("E:\\Pec\\lunk.jpg")
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret,thresh=cv.threshold(gray,127,255,cv.THRESH_BINARY)
contours,hierarchy=cv.findContours(thresh,cv.RETR_TREE,cv.CHAIN_APPROX_NONE)
cnt=contours[3]
x,y,w,h=cv.boundingRect(cnt)
image=cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show("image",image)

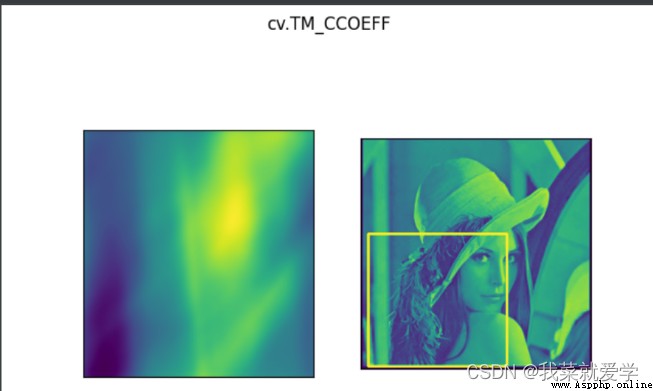
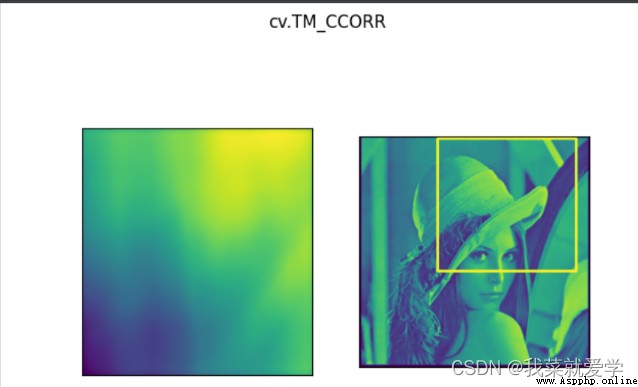
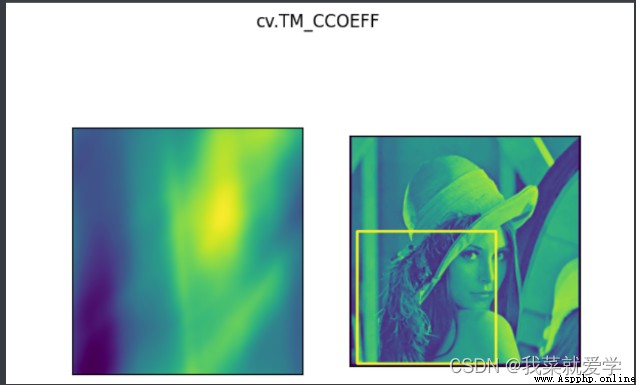
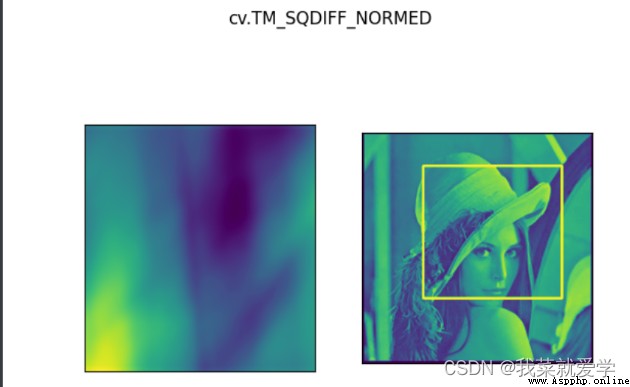
說明:模板匹配和卷積原理很像,模板在原圖像上從原點開始滑動,計算模板與(圖像被模板覆蓋的地方)的差別程度,這個差別程度的計算方法在opencv中有6種,然後將每次計算的結果放入一個矩陣裡,作為結果輸出。如原圖形是AxB大小,而模板是axb大小,則輸出結果是(A-a+1)x(B-b+1)
6種差別程度的計算方法:(盡量用歸一化)
#模板匹配
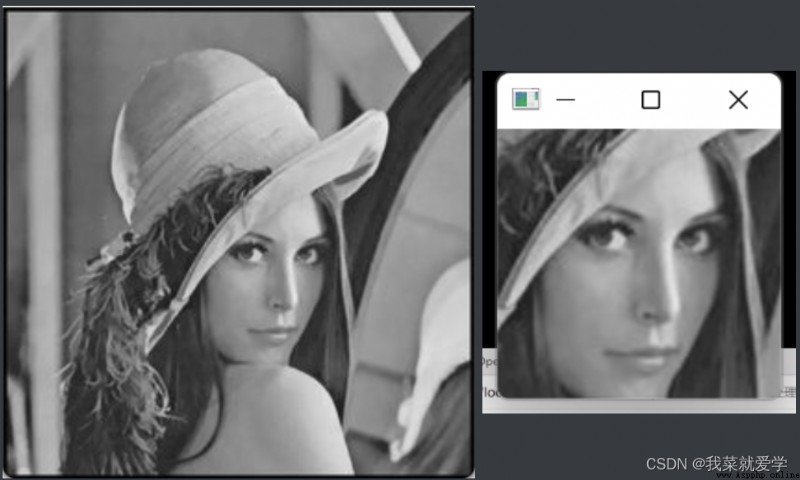
img=cv.imread("E:\\Pec\\lida.jpg",0)
template=cv.imread("E:\\Pec\\face.jpg",0)
#cv_show("lida",img)
#cv_show("tem",template)
h,w=template.shape[:2]
print(img.shape)
print(template.shape)
methods=['cv.TM_CCOEFF','cv.TM_CCORR','cv.TM_CCOEFF','cv.TM_SQDIFF_NORMED'
,'cv.TM_CCORR_NORMED','cv.TM_CCOEFF_NORMED']
#進行模板匹配
res=cv.matchTemplate(img,template,3)
#第三個參數是一個數值,1對應上面的TM_CCOEFF,同理下面
print(res.shape)
min_val,max_val,min_loc,max_loc=cv.minMaxLoc(res)
print(min_val)#最小值
print(max_val)#最大值
print(min_loc)#最小值位置
print(max_loc)#最大值位置
for meth in methods:
img2=img.copy()
#匹配方法的真值
method=eval(meth)#eval函數是以字符串的形式運行代碼,如a1,a2...分別賦予1,2..
print(method)
res=cv.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
#如果是平方差匹配TM_SQDIFF或者歸一化平方差匹配,取最小值
if method in [1,4]:
top_left=min_loc
else:
top_left=max_loc
bottom_right=(top_left[0]+w,top_left[1]+h)
#畫矩形
cv.rectangle(img2,top_left,bottom_right,255,2)
#位置由三個整型數值構成:第一個代表行數,第二個代表列數,第三個代表索引位置。
#舉例:plt.subplot(2, 3, 5) 和plt.subplot(235) 一樣。
plt.subplot(121),plt.imshow(res)
plt.xticks([]),plt.yticks([])#隱藏坐標軸
plt.subplot(122),plt.imshow(img2)
plt.xticks([]), plt.yticks([]) # 隱藏坐標軸
plt.suptitle(meth)
plt.show()
(255, 255)
(146, 153)
(110, 103)
0.7732675671577454
0.9017052054405212
(8, 109)
(67, 35)
4
2
4
1
3
5
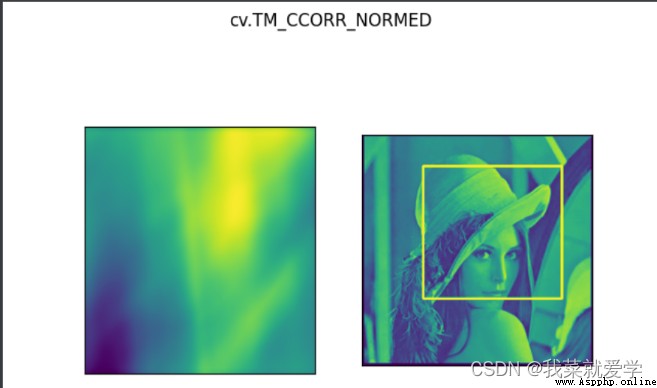
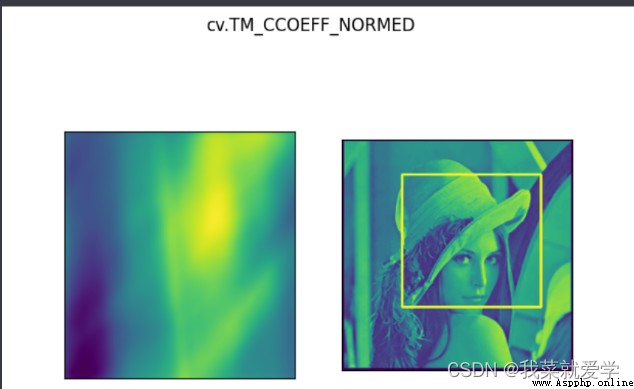
匹配多個對象:
python zip()函數:
zip() 函數用於將可迭代的對象作為參數,將對象中對應的元素打包成一個個元組,然後返回由這些元組組成的列表。
如果各個迭代器的元素個數不一致,則返回列表長度與最短的對象相同,利用 * 號操作符,可以將元組解壓為列表。zip(*loc[::-1])
img_jb1=cv.imread("E:\\Pec\\jinbi1.jpg")
#cv_show("res",img_jb1)
img_jb2=cv.imread("E:\\Pec\\jinbi2.jpg")
#cv_show("res",img_jb2)
h,w=img_jb2.shape[:2]
res=cv.matchTemplate(img_jb1,img_jb2,cv.TM_CCOEFF_NORMED)
#取匹配度大於80%的坐標
threshold=0.7
loc=np.where(res>threshold)
for pt in zip(*loc[::-1]): #*表示可選參數
bootom_right=(pt[0]+w,pt[1]+h)
cv.rectangle(img_jb1,pt,bootom_right,(0,255,0),2)
cv_show("jb",img_jb1)
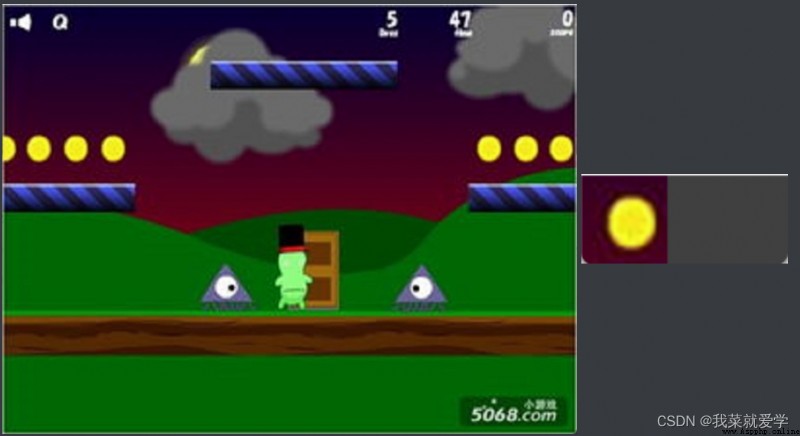
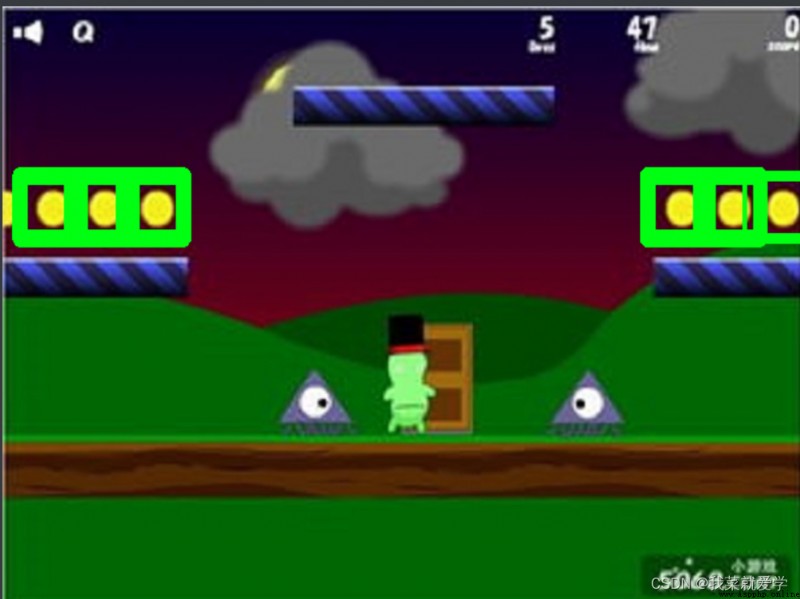
(1)向下采樣方法(縮小)
down=cv.pyrDown(image)
#cv_show("down",down)
(2)向上采樣方法(放大)

up=cv.pyrUp(image)
#cv_show("up",up)
L i = G i − P y r U p ( P y r D o w n ( G i ) ) Li=Gi-PyrUp(PyrDown(Gi)) Li=Gi−PyrUp(PyrDown(Gi))