import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
def calc_distance(dataset, centroids):
n, l = dataset.shape
m, l = centroids.shape
dataset = dataset.reshape(n, 1, l)
centroids = centroids.reshape(1, m, l)
sum = np.sum(np.square(dataset[..., :] - centroids[..., :]), axis=-1)
distance = np.sqrt(sum)
return distance
def kmeans(dataset, k):
data_num = len(dataset)
# 第一列存樣本屬於哪一簇
# 第二列存樣本的到簇的中心點的誤差
clusterAssment = np.zeros((data_num, 2))
centroids = dataset[np.random.choice(data_num, k, replace=False)]
last_nearest = np.zeros((data_num,))
while True:
distances = calc_distance(dataset, centroids)
current_nearest = np.argmin(distances, axis=1)
if (last_nearest == current_nearest).all():
break
clusterAssment = np.hstack([np.expand_dims(current_nearest, axis=1),
np.expand_dims(distances[np.arange(data_num), current_nearest], axis=1)])
# update cluster
for idx in range(k):
centroids[idx] = np.mean(dataset[current_nearest == idx], axis=0)
last_nearest = current_nearest
return centroids, clusterAssment
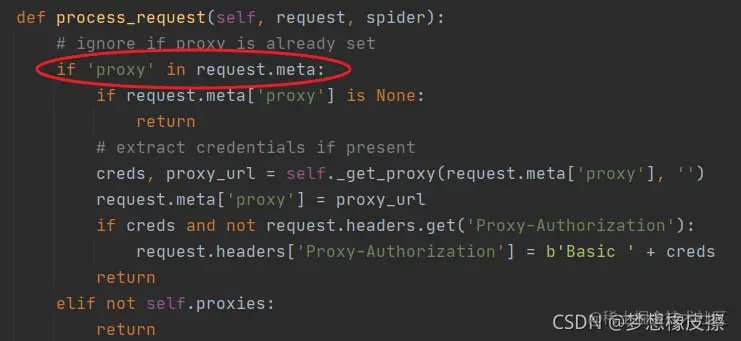 Python scratch proxy middleware is one of the contents that a crawler must master
Python scratch proxy middleware is one of the contents that a crawler must master
p{margin:10px 0}.markdown-body
 Explain the first parameter key of the python list method sort() [simple and clear explanation]
Explain the first parameter key of the python list method sort() [simple and clear explanation]
Python list (list) Methods sor
 [Python crawler combat] Do not produce novels, only porters of the website, too awesome~ (with source code)
[Python crawler combat] Do not produce novels, only porters of the website, too awesome~ (with source code)
前言遇見你時,漫天星河皆為浮塵不知從什麼時候開始.小說開始掀