前言:
作者簡介:渴望力量的哈士奇 ,大家可以叫我 哈士奇 ,一位致力於 TFS - 全棧 賦能的博主
CSDN博客專家認證、新星計劃第三季全棧賽道 MVP 、華為雲享專家、阿裡雲專家博主
如果文章知識點有錯誤的地方,請指正!和大家一起學習,一起進步
人生格言:優於別人,並不高貴,真正的高貴應該是優於過去的自己。
如果感覺博主的文章還不錯的話,還請關注、點贊、收藏三連支持一下博主哦專欄系列(點擊解鎖) 學習路線(點擊解鎖) 知識定位 Python全棧白皮書 零基礎入門篇 以淺顯易懂的方式輕松入門,讓你徹底愛上Python的魅力。 語法進階篇 主要圍繞多線程編程、正則表達式學習、含貼近實戰的項目練習 。 自動化辦公篇 實現日常辦公軟件的自動化操作,節省時間、提高辦公效率。 自動化測試實戰篇 從實戰的角度出發,先人一步,快速轉型測試開發工程師。 數據庫開發實戰篇掌握關系型與非關系數據庫知識,提升數據庫實戰開發能力。 爬蟲入門與實戰更新中數據分析篇更新中前端入門+flask 全棧篇更新中django+vue全棧篇更新中拓展-人工智能入門更新中網絡安全之路 踩坑篇 記錄學習及演練過程中遇到的坑,便於後來居上者 網安知識掃盲篇 三天打魚,不深入了解原理,只會讓你成為腳本小子。 vulhub靶場漏洞復現 讓漏洞復現變得簡單,讓安全研究者更加專注於漏洞原理本身。 shell編程篇 不涉及linux基礎,最終案例會偏向於安全加固方向。 [待完結] WEB漏洞攻防篇2021年9月3日停止更新,轉戰先知社區等安全社區及小密圈 滲透工具使用集錦2021年9月3日停止更新,轉戰先知社區等安全社區及小密圈點點點工程師 測試神器 - Charles 軟件測試數據包抓包分析神器 測試神器 - Fiddler 一文學會 fiddle ,學不會倒立吃翔,稀得! 測試神器 - Jmeter 不僅是性能測試神器,更可用於搭建輕量級接口自動化測試框架。 RobotFrameWorkPython實現的自動化測試利器,該篇章僅介紹UI自動化部分。 Java實現UI自動化文檔寫於2016年,Java實現的UI自動化,仍有借鑒意義。 MonkeyRunner該工具目前的應用場景已不多,文檔已刪,為了排版好看才留著。

該章節的內容為多表連接查詢的內連接,因為 MySQL 是關系型數據庫,數據是拆分重組在多個數據表裡面的。所以我們勢必要從多個數據表中提取數據,通過 SQL 語句的內連接與外連接就能夠實現多表查詢了。這部分內容是需要我們重點學習的,學習的過程中會穿插多種的案例來強化對表連接的語法的運用。(簡單一點來說,其實就是從多張表裡查詢數據集,這一大段是我為了給摘要湊字數用的!)
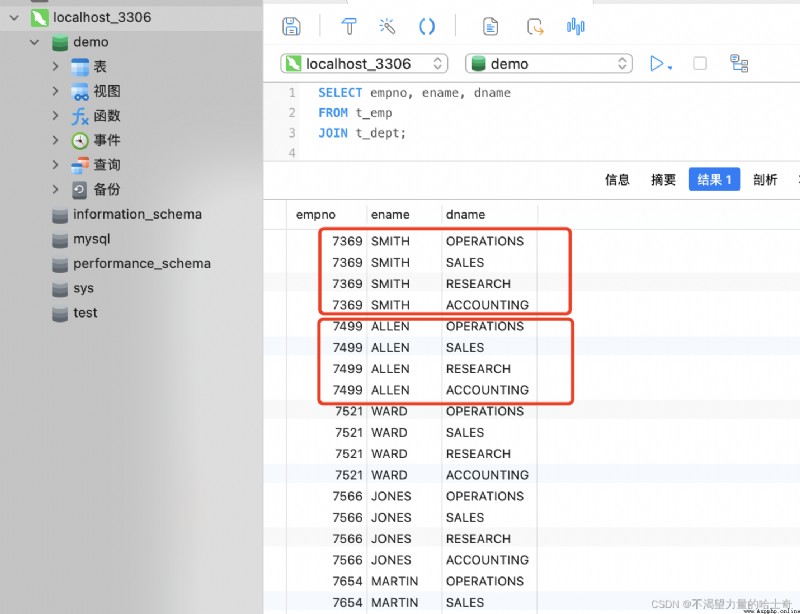
- 如果要從多張表中提取數據,必須指定其關聯的條件。如果沒有定義關聯的條件,就會出現無條件的連接,表與表之間的每一條數據都會進行匹配連接,於是就產生了笛卡爾積。
- 舉個例子,比如說員工表中的某個員工 “deptno” 的部門編號所屬是 “10”,他能夠與 部門表中的 “10” 所進行連接,這就是連接條件;如果沒有關聯的條件,那就是無條件的連接表中的記錄了。
見下方的 SQL 語句與圖片:SELECT empno, ename, dname FROM t_emp JOIN t_dept; -- 這是一中造成笛卡爾積的錯誤語法示例 -- 這種例句實不符合現實邏輯的,所以我們在做表連接的時候一定要給出連接條件才行
- 如果規定了 “連接條件” 的表連接語句,就不會出現笛卡爾積了。
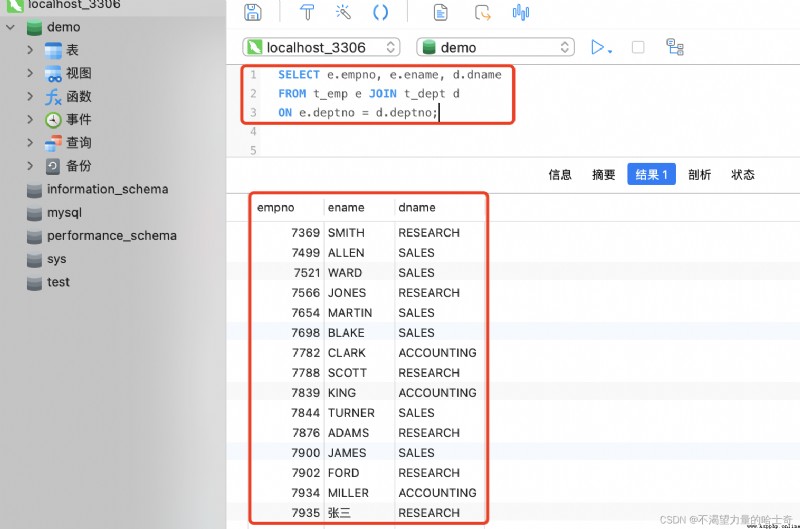
見下方的 SQL 語句與圖片:SELECT e.empno, e.ename, d.dname FROM t_emp e JOIN t_dept d ON e.deptno = d.deptno; -- 使用 ON 子句 規定 "連接條件",這個條件就是 "員工表"中的"部門編號" 要與 "部門表"中的"部門編號"是相等的 -- 需要注意的是,一定要針對連接的表與表之間起一個別名,否則直接使用 "ON deptno = deptno" 的話,MySQL 會不知道這個字段屬於哪個表 -- "t_emp" 表的別名為 "e" ; "t_dept" 表的別名為 "d"
從圖中我們可以看到沒有產生 "笛卡爾積" ,所以說最關鍵的地方就在於 "ON" 子句 規定了表連接。
- 表連接分為兩種:內連接與外連接
- 內連接是結果集中只保留符合連接條件的記錄,不符合連接條件的記錄是絕對不會出現在結果集中的。
(該章節主要介紹的就是 "內連接")- 外連接是不管符不符合連接條件,查詢到的記錄多會保留在結果集中。
(至於為何會這樣,在後續的外連接章節再為大家詳細的介紹吧)
- 內連接是最常見的一種表連接,用於查詢多張關系表符合連接條件的記錄。
(也就是符合連接條件的交集的部分)
內連接常用語法:SELECT ...... FROM 表1 JOIN 表2 ON 連接條件; -- 這是最標准的內連接語法,用 "JOIN" 關鍵字連接兩張表,"ON" 子句規定連接的條件。
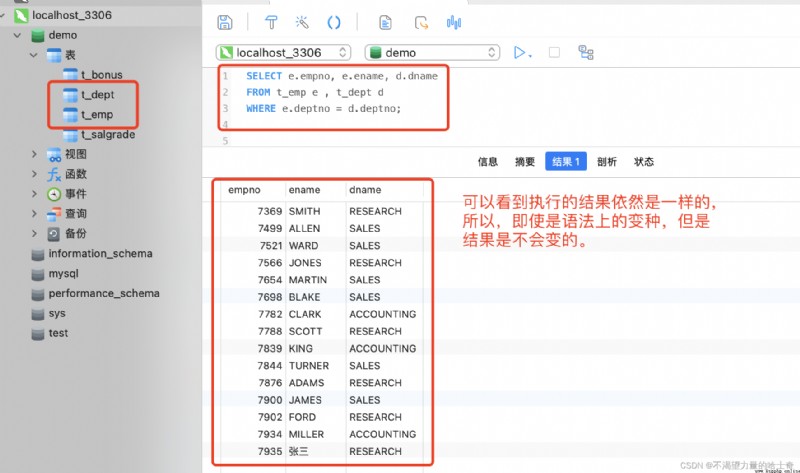
內連接的變種語法①:-- 思考一個問題先:既然 "ON" 子句規定的是連接條件篩選符合條件的記錄,那麼是否可以將連接條件寫在 "WHERE" 子句中呢? -- 答案是完全可以的,與是就有了下面這種語法。 SELECT ...... FROM 表1 JOIN 表2 WHERE 連接條件; -- 忽略 "ON" 子句,使用 "WHERE" 子句來替代
內連接的變種語法②:(基於 "變種語法①" 衍生出來的語法)SELECT ...... FROM 表1, 表2 WHERE 連接條件; -- 將 "JOIN" 關鍵字去掉,使用 "," 來代替。 -- 想連接多少張表,直接在 "FROM" 子句後面寫上表名即可,最後再 "WHERE" 子句裡定義好連接條件就可以了。
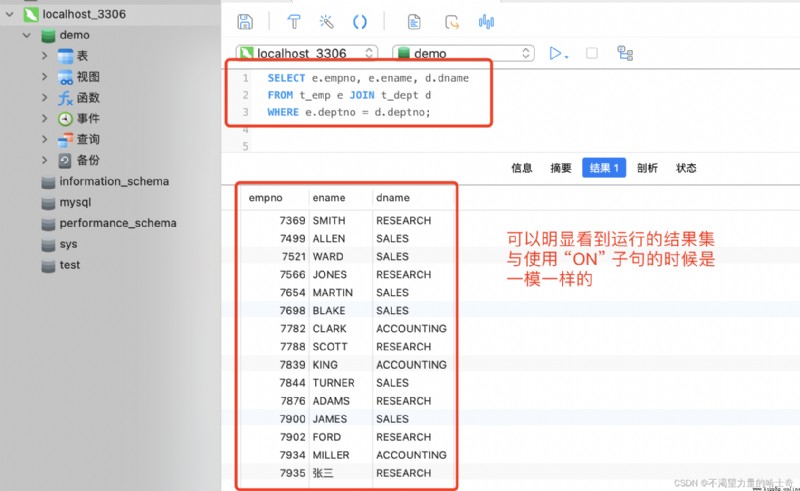
內連接衍生語法 SQL 語句示例如下①:SELECT e.empno, e.ename, d.dname FROM t_emp e JOIN t_dept d WHERE e.deptno = d.deptno; -- 將 "ON" 子句替換為 "WHERE" 子句
內連接衍生語法 SQL 語句示例如下②:SELECT e.empno, e.ename, d.dname FROM t_emp e , t_dept d WHERE e.deptno = d.deptno; -- 將 "JOIN" 關鍵字省略替換為 "," 逗號
PS:以上的寫法都是正確的內連接,在運行效率上沒有什麼區別。當然了,運行結果也都是一樣的。所以內連接攜程什麼樣子,完全就看個人的喜好、好惡了。
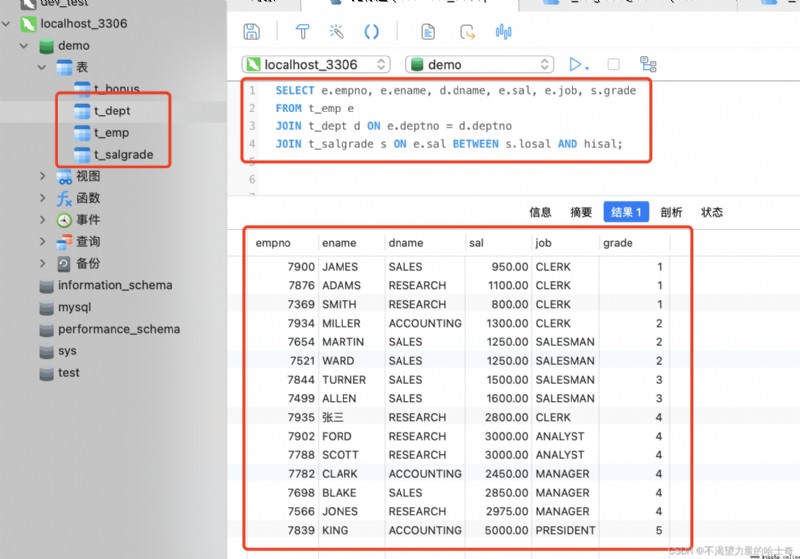
- 查詢每個員工的工號、姓名、部門名稱、底薪、職位、工資等級
SELECT e.empno, e.ename, d.dname, e.sal, e.job, s.grade FROM t_emp e JOIN t_dept d ON e.deptno = d.deptno JOIN t_salgrade s ON e.sal BETWEEN s.losal AND hisal; -- 先利用 "員工表" 的 "部門編號" 關聯 "部門表" 的 "部門編號" -- 再利用 "薪資等級表" 的 "薪資等級區間" 關聯 "員工表" 的 "月薪" 進行等級的匹配
同樣的,在這個小案例裡,我們也發現了一個問題:在內連接的數據表中,不一定必須要有同名的字段,只要字段之間符合邏輯關系就可以了,同樣可以把數據表連接起來。
- 查詢與 “SCOTT” 相同部門的員工都有誰?
這裡需要注意兩個條件
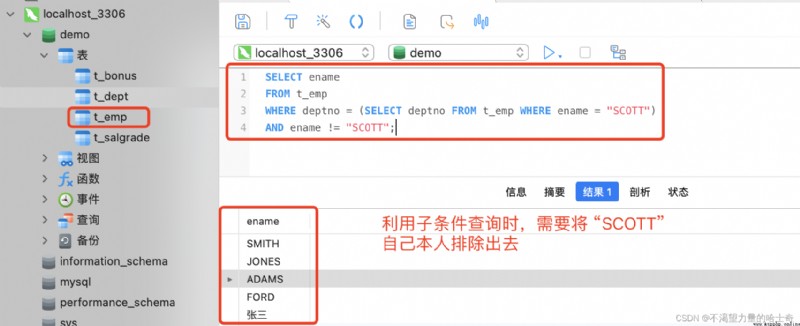
第一個未知:不知道 "SCOTT" 的部門是什麼?第二個未知:不知道誰與 "SCOTT" 是同一個部門的?- `關於未知的條件,大家可能第一時間想到的就是利用子查詢來實現,OK,那就先來使用 “子查詢” 實現
子查詢 SQL 示例如下:SELECT ename FROM t_emp WHERE deptno = (SELECT deptno FROM t_emp WHERE ename = "SCOTT") AND ename != "SCOTT";這個查詢語句,還是非常好理解的哈。非常的符合人的思考邏輯,但是並不推薦這種寫法。因為子查詢的查詢效率是非常的慢的,因為 “FROM” 子句查詢的是 “t_emp” 員工表,從 “員工表” 提取出來的每一個記錄在 “WHERE” 子句裡進行條件匹配的時候會與 “子查詢” 都會重新執行一遍。當 “員工表” 裡存在大量的數據的時候(比如上萬條),則 “WHERE” 子句會將子查詢也都會重新執行一遍。
試想一下,這樣的效率是不是很低的,雖然說這樣的寫法非常的符合人的思考與邏輯思維,但是數據庫執行起來真的會效率非常的低下。所以這個時候,最好的解決方案就得需要利用 “表連接” 的方式來實現了!
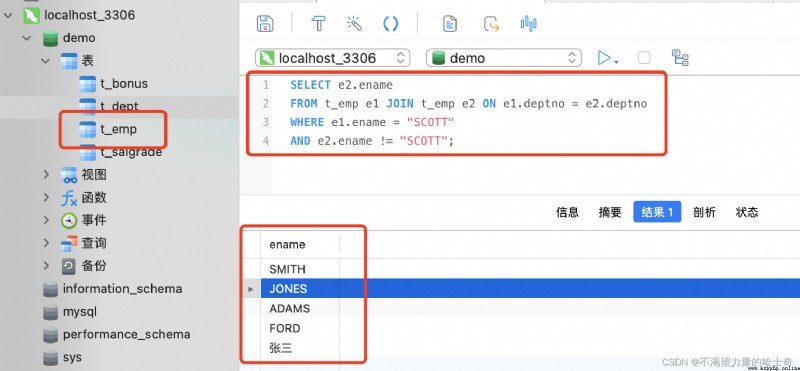
內連接 SQL 示例如下:SELECT e2.ename FROM t_emp e1 JOIN t_emp e2 ON e1.deptno = e2.deptno WHERE e1.ename = "SCOTT" AND e2.ename != "SCOTT"; -- 可能大家會覺得 "員工表" 與 "員工表" (自己與自己)做表連接很奇怪,但是在實際語法上,這是可行且沒有錯誤的 -- 原理其實就是在同一個數據表中,分別提取不同的數據而已;如此語法在效率上要遠遠的超過子查詢的效率從這個案例我們也同樣得到一個結果:“相同的數據表也是可以做表連接的在語法與邏輯關系上都沒有問題。”