使用實例一:獲取需要的文字
1、導入需要使用的模塊
import urllib.request
from lxml import etree
2、發送請求訪問網站,得到服務器響應的頁面源碼
# 請求地址
url = 'https://baidu.com'
# 用戶代理
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/10'
}
# 定制請求頭
request = urllib.request.Request(url=url,headers=headers)
# 發送請求訪問服務器,返回響應對象
response = urllib.request.urlopen(request)
# 解碼響應對象,得到頁面源碼
content = response.read().decode('utf-8')
3、解析服務器響應的文件並返回解析對象
# 解析服務器響應的文件
parse_html = etree.HTML(content)
4、調用xpath路徑,提取數據,xpath的返回數據是列表類型
可以用xpath插件來動態的獲取xpath路徑:(可以將鼠標懸停在需要提取的文本數據上,然後按 shift 鍵就xpath插件的右邊就會自動出現定位該文本的Xpath 表達式,然後再根據需求對表達式修改。)
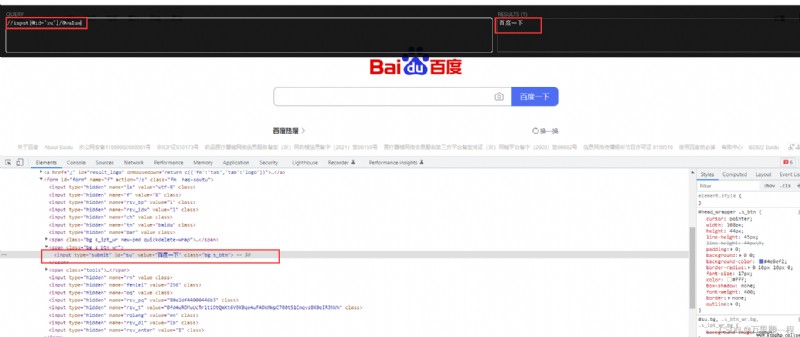
待提取數據的xpath路徑:
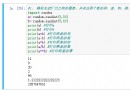
list = parse_html.xpath('//input[@id="su"]/@value')
最後總體代碼實現:
import urllib.request
from lxml import etree
# 請求地址
url = 'https://baidu.com'
# 用戶代理
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/10'
}
# 定制請求頭
request = urllib.request.Request(url=url,headers=headers)
# 發送請求訪問服務器,返回響應對象
response = urllib.request.urlopen(request)
# 解碼響應對象,得到頁面源碼
content = response.read().decode('utf-8')
# 解析服務器響應的文件
parse_html = etree.HTML(content)
# 編寫xpath路徑,獲取想要的數據,xpath的返回值是列表類型
list = parse_html.xpath('//input[@id="su"]/@value')
# 獲得列表的第一個數據
list1 = parse_html.xpath('//input[@id="su"]/@value')[0]
print(list)
print(list1)
執行結果:
['百度一下']
百度一下
使用實例二:從網站上提取圖片
先發送請求訪問網站,得到網站響應文件,然後解析網站響應文件,從網站響應文件中使用xpath表達式定位到需要的圖片地址,然後用 urllib.request.urlretrieve()方法得到圖片。
代碼實例:
import urllib.request
from lxml import etree
# 定制請求對象
def creat_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/fengjingtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/fengjingtupian_'+str(page)+'.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/10'
}
request = urllib.request.Request(url=url,headers=headers)
return request
# 發送請求,獲得返回內容
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下載圖片
def down_image(content):
# 解析服務器響應的文件
parse_html = etree.HTML(content)
# 圖片地址
src_list = parse_html.xpath('//div[@id="container"]//a/img/@src')
# 圖片名
name_list = parse_html.xpath('//div[@id="container"]//a/img/@alt')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:'+src
# 下載圖片到文件夾,路徑為當前項目下的fengjingimage文件夾
urllib.request.urlretrieve(url=url, filename='./fengjingimage/'+name+'.jpg')
if __name__ == '__main__':
start_page = int(input("請輸入起始頁:"))
end_page = int(input("請輸入結束頁:"))
for page in range(start_page,end_page+1):
request = creat_request(page)
content = get_content(request)
down_image(content)
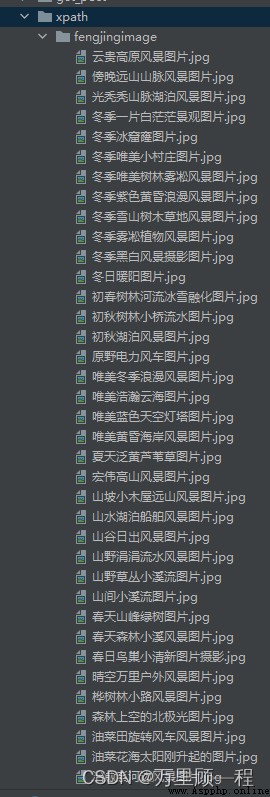
執行結果:
請輸入起始頁:1
請輸入結束頁:2
Process finished with exit code 0
圖片提取成功: