??跳轉文末?? 獲取作者聯系方式,共同學習進步
python:3.8.3
jupyter-notebook : 6.4.0
注意:本文案例可以直接在 jupyter-notebook 上運行,但在 PyCharm 上的話需要代碼的最後一句加上 print 哦!
print() 無疑是我們使用最多的函數,他可以直接輸出、指定間隔/結尾字符、將輸出內容保存到指定文件(應用:記錄自動化腳本異常信息)等。下面列舉它的常見用法。
1 直接輸出
print('hello world')
output:hello world
2 指定間隔字符sep
print('A', 'B', 'C', sep=' Python ')
output:A Python B Python C
3 指定結尾字符
print('hello', 'world', end='Python')
output:hello worldPython
4 將輸出內容保存到outfile.txt文件中
print('hello', 'world', sep=' ', file=open('outfile.txt', 'w', encoding='utf-8'))
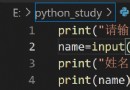
input() 可以接收用戶輸入的內容,並以字符串的形式保存。
name = input('name:')

在 jupyter notebook 上執行的效果可能和別的編輯器不同,但操作都是輸入完後,按 “回車” 即可。
type() 返回指定值的數據類型。
type([1, 2])
output:list
isintance() 判斷傳入的值是否為指定類型,返回 True/False 。
isinstance('Python新視野', str)
output:True
str() 將指定值轉為字符串類型。
str(1.23)
output:‘1.23’
eval() 將字符串轉成有效的表達式來求值或者計算結果。可以將字符串轉化成列表(list),元組(tuple),字典(dict),集合(set)等。
res = eval("{'name': 'Python'}")
type(res)
output:dict
capitalize() 返回字符串中的首字母大寫,其余小寫的字符串
cap_str = 'python新視野'.capitalize()
cap_str
output:‘Python新視野’
center() 返回一個指定寬度的居中字符串,左右部分空余部分用指定字符填充。
width:長度
fillchar:空余部分填充的字符,默認使用空格
center_str = ‘Python新視野’.center(15, “!”)
center_str
output:’!!!Python新視野!!!’
str.count(sub, start, end) 返回 sub 在 str 中出現的次數,可以通過 [start, end] 指定范圍,若不指定,則默認查找整個字符串。
sub: 子串
start: 開始的索引,默認為 0
end: 結束的索引,默認為字符串的長度
name = ‘python python’
name.count(‘p’), name.count(‘p’, 1)
output:(2, 1)
1 find() 從左往右掃描字符串,返回 sub 第一次出現的下標。可以通過 [start, end] 指定范圍,若不指定,則默認查找整個字符串。如最後未找到字符串則返回 -1。
sub: 子串
start: 開始檢索的位置,默認為 0
end: 結束檢索的位置,默認為字符串的長度
name = ‘Python’
name.find(‘Py’), name.find(‘Py’, 1)
output:(0, -1)
2 rfind 與 find() 的用法相似,只是從右往左開始掃描,即從字符串末尾向字符串首部掃描。
name = 'Python'
name.rfind('Py'), name.rfind('Py', 1)
output:(0, -1)
1 index() 和 find() 用法相同,唯一的不同是如果找不到 sub 會報錯。
示例 ??
name = 'Python'
name.index('Py', 0)
output:0
示例 ??
name = 'Python'
name.index('Py', 1)
output:ValueError: substring not found
2 rindex() 和 index() 用法相同,不過是從右邊開始查,它的查詢與 index() 相同。
name = 'Python'
name.rindex('Py', 0)
output:0
isalnum() 判斷字符串中是否所有字符都是字母(可以為漢字)或數字,是 True ,否 False,空字符串返回 False。
示例 ??
'Python新視野'.isalnum()
output:True
示例 ??
'Python-sun'.isalnum()
output:False
'-' 是符號,所以返回 False。
isalpha() 判斷字符串中是否所有字符都是字母(可以為漢字),是 True ,否 False,空字符串返回 False。
示例 ??
'Python新視野'.isalpha()
output:True
示例 ??
'123Python'.isalpha()
output:False
其中包含了數字,返回 False
isdigit() 判斷字符串中是否所有字符都是數字(Unicode數字,byte數字(單字節),全角數字(雙字節),羅馬數字),是 True ,否 False,空字符串返回 False。
示例 ??
'四123'.isdigit()
output:False
其中包含了漢字數字,返回 False
示例 ??
b'123'.isdigit()
output:True
byte 數字返回 True 。
字符串中只包含空格( 、 、 、 、),是 True ,否 False,空字符串返回 False。
符號
含義
換行
回車
換頁
橫向制表符
縱向制表符
'
'.isspace()
output:True
join(iterable) 以指定字符串作為分隔符,將 iterable 中所有的元素(必須是字符串)合並為一個新的字符串。
','.join(['Python', 'Java', 'C'])
output:‘Python,Java,C’
1 ljust() 返回一個指定寬度左對齊的字符串
width:長度
fillchar:右部空余部分填充的字符,默認使用空格
ljust_str = ‘Python新視野’.ljust(15, “!”)
ljust_str
output:‘Python新視野!!!’
2 rjust() 返回一個指定寬度右對齊的字符串,與 ljust 操作正好相反。
width:長度
fillchar:左部空余部分填充的字符,默認使用空格
rjust_str = ‘Python新視野’.rjust(15, “!”)
rjust_str
output:’!!!Python新視野’
1 lower() 將指定字符串轉換為小寫。
lower_str = 'Python新視野'.lower()
lower_str
output:‘python新視野’
2 islower() 判斷字符串所有區分大小寫的字符是否都是小寫形式,是 True ,否 False,空字符串或字符串中沒有區分大小寫的字符返回 False 。
'python-sun'.islower()
output:True
'python-sun' 區分大小寫的字符有 'pythonsun',並且都是小寫,所以返回 True 。
1 lstrip() 會在字符串左側根據指定的字符進行截取,若未指定默認截取左側空余(空格, , , 等)部分。
name = '+++Python新視野+++'
name.lstrip('+')
output:‘Python新視野+++’
2 rstrip() 與 lstrip() 用法相似,只是截取右側的內容。
name = '+++Python新視野+++'
name.rstrip('+')
output:’+++Python新視野’
3 strip() 實際是 lstrip() 與 rstrip() 的結合,它會截取字符串兩邊指定的字符。
name = '+++Python新視野+++'
name.strip('+')
output:‘Python新視野’
1 str.split(sep=None, maxsplit=-1) 使用 sep 作為分隔符將字符串進行分割,返回字符串中的單詞列表。
seq: 用來分割字符串的分隔符。None(默認值)表示根據任何空格進行分割,返回結果中不包含空格。
maxsplit: 指定最大分割次數。-1(默認值)表示不限制。
split_str = ‘P y t h o n 新 視 野’
split_str.split(maxsplit=2)
output:[‘P’, ‘y’, ‘t h o n 新 視 野’]
使用默認的空格進行分割,設置最大的分割次數為2
2 str.splitlines 返回字符串中的行列表,它按照行 (' ', ',' ') 分隔,返回分隔後的列表。它只有一個參數 keepends 表示是否在結果中保留換行符,False (默認)不保留,True 保留。
示例 ??
split_str = 'P
y
t h o n 新 視 野'
split_str.splitlines()
output:[‘P’, ‘y’, ’ t h o n 新 視 野’]
示例 ??
split_str = 'P
y
t h o n 新 視 野'
split_str.splitlines(keepends=True)
output:[‘P ’, ‘y ’, ’ t h o n 新 視 野’]
1 startswith(prefix[, start[, end]]) 檢查字符串是否是以指定子字符串 substr 開頭,是 True ,否 False,空字符串會報錯。如果指定 start 和 end ,則在指定范圍內檢查。
startswith_str = 'Python新視野'
startswith_str.startswith('thon', 2)
output:True
從第 3 個字符開始檢測
2 str.endswith(suffix[, start[, end]]) 與 startswith 用法相同,不同之處是檢查字符串是否以指定子字符串結尾,是 True ,否 False,空字符串會報錯。
endswith_str = 'Python新視野'
endswith_str.endswith('thon', 0, 6)
output:True
從第 1 個字符開始檢測,到第 7 個字符結束(不包含第 7 個),注意這裡的范圍和字符串切片其實是一樣的道理,都是前閉後開。
1 title() 返回字符串中每一個單詞首字母大寫。
title_str = 'python新視野 python新視野'.title()
title_str
output:‘Python新視野 Python新視野’
2 istitle() 判斷字符串是否滿足每一個單詞首字母大寫,是 True ,否 False,空字符串返回 False。
'Abc Def '.istitle()
output:True
1 upper() 將指定字符串中字母轉換為大寫。
upper_str = 'Python新視野'.upper()
upper_str
output:‘PYTHON新視野’
2 isupper() 判斷字符串所有區分大小寫的字符是否都是大寫形式,是 True ,否 False,空字符串或字符串中沒有區分大小寫的字符返回 False 。
'PYTHON-SUN'.isupper()
output:True
list() 將可迭代對象轉成列表。
示例 ??
list((0,1,2)) + list({0,1,2}) + list('012')
output:[0, 1, 2, 0, 1, 2, ‘0’, ‘1’, ‘2’]
將元組、集合、字符串轉換成列表並通過運算符連接。
示例 ??
list(range(3))
output:[0, 1, 2]
將可迭代對象轉換成列表
lst = ['Python', 'Java']
lst.append('C')
lst
output:[‘Python’, ‘Java’, ‘C’]
extend() 在列表的末尾添加可迭代對象(列表、元組、字典、字符串)中的元素來擴展列表。
1 追加列表
lst = ['Python', 'Java', 'C']
lst.extend([1, 2, 3])
lst
output:[‘Python’, ‘Java’, ‘C’, 1, 2, 3]
2 追加字符串
lst = ['Python', 'Java', 'C']
lst.extend('123')
lst
output:[‘Python’, ‘Java’, ‘C’, ‘1’, ‘2’, ‘3’]
將字符串中的每一個字符當做一個元素追加到原列表末尾
3 追加集合
lst = ['Python', 'Java', 'C']
lst.extend({1,2,3})
lst
output:[‘Python’, ‘Java’, ‘C’, 1, 2, 3]
4 追加字典
lst = ['Python', 'Java', 'C']
lst.extend({1: 'b', 2: 'a'})
lst
output:[‘Python’, ‘Java’, ‘C’, 1, 2]
只將字典的 key 值追加到原列表末尾
insert(index, object) 將指定對象插入到列表的 index 位置,原本 index 位置上及 > index 的元素的元素整體後移。
示例 ??
lst = ['Python', 'Java', 'C']
lst.insert(1, 'C++')
lst
output:[‘Python’, ‘C++’, ‘Java’, ‘C’]
示例 ??
lst = ['Python', 'Java', 'C']
lst.insert(6, 'C++')
lst
output:[‘Python’, ‘Java’, ‘C’, ‘C++’]
當 index 的值大於列表長度時,會在列表末尾添加。
pop(index=-1) 移除列表中指定位置元素(默認最後一個),並且返回移除元素的值。若指定的 index 值超過列表長度則會報錯。
lst = ['Python', 'Java', 'C']
lst.pop(1), lst
output:(‘Java’, [‘Python’, ‘C’])
lst.remove(value) 移除列表中第一次出現的 value ,無返回值,直接修改列表;如果 value 不在列表中則報錯。
示例 ??
lst = ['Python', 'Java', 'C', 'Python']
lst.remove('Python')
lst
output:[‘Java’, ‘C’, ‘Python’]
只刪除了第一次出現的 Python
示例 ??
lst = ['Python', 'Java', 'C', 'Python']
lst.remove('HTML')
lst
output:ValueError: list.remove(x): x not in list
HTML 不在列表中,發生錯誤
list.clear() 移除列表中所有的元素,無返回值。
lst = ['Python', 'Java', 'C']
lst.clear()
lst
output:[]
index(value, start, stop) 返回列表中查找的第一個與value匹配的元素下標,可通過 [start, stop) 指定查找范圍。
示例 ??
lst = ['Python', 'Java', 'C',
'Python', 'Python']
lst.index('Python')
output:0
不指定范圍,在列表全部元素中查找
示例 ??
lst = ['Python', 'Java', 'C',
'Python', 'Python']
lst.index('Python', 1, 3)
output:ValueError: ‘Python’ is not in list
指定范圍 [1, 3) ,即在[‘Java’, ‘C’]中查找 Python 很明顯不存在,發生報錯
count(value) 返回 value 在列表中出現的次數。若未在列表中找到 value 則返回 0 。
示例 ??
lst = ['Python', 'Java', 'C',
'Python', 'Python']
lst.count('Python')
output:3
示例 ??
lst = ['Python', 'Java', 'C',
'Python', 'Python']
lst.count('Py')
output:0
列表中無元素 'Py',返回 0 。
reverse() 將列表逆序排列,無返回值。
lst = [1, 5, 9, 2]
lst.reverse()
lst
output:[2, 9, 5, 1]
sort() 對列表進行指定方式的排序,修改原列表,該排序是穩定的(即兩個相等元素的順序不會因為排序而改變)。
False 為升序,True 為降序。示例 ??
lst = [1, 5, 9, 2]
lst.sort()
lst
output:[1, 2, 5, 9]
示例 ??
lst = ['Python', 'C', 'Java']
lst.sort(key=lambda x:len(x), reverse=False)
lst
output:[‘C’, ‘Java’, ‘Python’]
指定 key 計算列表中每個元素的長度,並按照長度進行升序排序
copy() 對列表進行拷貝,返回新生成的列表,這裡的拷貝是淺拷貝,下面會說明為什麼特意說它是淺拷貝。
示例 ??
lst = [[1,2,3], 'a' ,'b']
lst_copy = lst.copy()
lst_copy.pop()
lst, lst_copy
output:([[1, 2, 3], ‘a’, ‘b’], [[1, 2, 3], ‘a’])
對 lst 進行 copy ,然後刪除列表 lst_copy 的最後一個元素,此時的 lst 的最後一個元素並未被刪除,說明兩個列表指向的地址確實不一樣。
示例 ??
lst = [[1,2,3], 'a' ,'b']
lst_copy = lst.copy()
lst_copy[0].pop()
lst_copy.pop()
lst, lst_copy
output:([[1, 2], ‘a’, ‘b’], [[1, 2], ‘a’, ‘b’])
這裡執行和上一個示例一樣的操作,只是這次再刪除一個數據,即列表嵌套的子列表中最後一個元素,觀察結果,發現這時不僅僅是 lst_copy 的列表發生改變,原列表 lst 中嵌套的字列表也發生了改變。說明兩個列表指向的地址不一樣,但子列表中指向的地址是相同的。
(1)直接賦值,傳遞對象的引用而已。原始列表改變,被賦值的對象也會做相同改變。
(2)淺拷貝,沒有拷貝子對象,所以原始數據子對象改變,拷貝的子對象也會發生變化。
(3)深拷貝,包含對象裡面的子對象的拷貝,所以原始對象的改變不會造成深拷貝裡任何子元素的改變,二者完全獨立。
1 先看直接賦值
lst = [1,2,3,[1,2]]
list1 = lst
# --直接賦值--
lst.append('a')
list1[3].append('b')
print(lst,'地址:',id(lst))
print(list1,'地址:',id(list1))
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2112498512768
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2112498512768
無論 lst 還是 list1 發生改變,二者都會受到影響。
2 淺拷貝需要用到 copy 模塊,或者用 list.copy() 效果一樣
from copy import copy
lst = [1, 2, 3, [1, 2]]
list2 = copy(lst)
# --淺拷貝--
lst.append('a')
list2[3].append('b')
print(lst,'地址:',id(lst))
print(list2,'地址:',id(list2))
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2112501949184
# [1, 2, 3, [1, 2, 'b']] 地址: 2112495897728
lst 與 list2 地址不同,但子列表的地址仍是相同的,修改子列表中的元素時,二者都會受到影響。
3 深拷貝需要用到 copy 模塊中的 deepcopy ,此時兩個列表完全獨立。
from copy import deepcopy
lst = [1, 2, 3, [1, 2]]
list3 = deepcopy(lst)
# --深拷貝--
lst.append('a')
list3[3].append('b')
print(lst,'地址:',id(lst))
print(list3,'地址:',id(list3))
# [1, 2, 3, [1, 2], 'a'] 地址: 2112506144192
# [1, 2, 3, [1, 2, 'b']] 地址: 2112499460224
根據結果可以看到修改子列表中的值時,原列表未發生改變。
tuple() 將可迭代對象轉換成元組。
tuple([0,1,2]) + tuple(range(3)) + tuple({0,1,2}) + tuple('012')
output:(0, 1, 2, 0, 1, 2, 0, 1, 2, ‘0’, ‘1’, ‘2’)
將可迭代對象轉換成列表並通過運算符連接。
clear() 清除字典的所有內容。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.clear()
dic
output:{}
fromkeys() 創建一個新字典,以序列 iterable 中元素做字典的鍵,value 為字典所有鍵對應的初始值。
iterable: 可迭代對象,新字典的鍵。
value: 可選參數, 設置鍵序列對應的值,默認為 None。
dict.fromkeys([‘CSDN’, ‘公眾號’],
‘Python新視野’)
output:{‘CSDN’: ‘Python新視野’, ‘公眾號’: ‘Python新視野’}
get(key, default=None) 根據指定的 key 值查找,如果 key 在字典中,則返回 key 的值,否則為 None。
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.get('CSDN')
output:‘Dream丶killer’
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
print(dic.get('微信'))
output:None
字典中沒有 key 等於 '微信',返回 None,jupyter notebook 對於 None 如果不加 print 默認不輸出,所以這裡加上print 來打印結果
items() 返回視圖對象,是一個可遍歷的 key/value 對,可以使用 list() 將其轉換為列表。
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
list(dic.items())
output:[(‘CSDN’, ‘Dream丶killer’), (‘公眾號’, ‘Python新視野’)]
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
for key, value in dic.items():
print('key: ', key, 'value: ', value)
# key: CSDN value: Dream丶killer
# key: 公眾號 value: Python新視野
keys() 返回一個視圖對象,值為字典的 key ,可將其轉換成列表。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.keys()
output:dict_keys([‘CSDN’, ‘公眾號’])
setdefault(key, default=None) 如果鍵不在字典中,則插入值為 None 的鍵。如果鍵在字典中,則返回鍵的值。
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.setdefault('CSDN', 'python-sun')
output:‘Dream丶killer’
字典中有 CSDN 這個 key 值,返回 CSDN 對應的值,不需要插入
示例 ??
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.setdefault('微信', 'python-sun')
dic
output:{‘CSDN’: ‘Dream丶killer’, ‘公眾號’: ‘Python新視野’, ‘微信’: ‘python-sun’}
字典中沒有 微信 這個 key 值,返回 None ,執行插入,並根據設置的參數 python-sun 來進行賦值。
dict.update(dict1) 把字典 dict1 的 key/value 對更新到 dict 裡,當 dict1 的 key 出現在 dict 中則修改 dict 中的值,如果 key 沒有出現在 dict 中,則添加這一對 key/value 。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic1 = {'CSDN': 'new_name',
'微信': 'python-sun'}
dic.update(dic1)
dic
output:{‘CSDN’: ‘new_name’, ‘公眾號’: ‘Python新視野’, ‘微信’: ‘python-sun’}
values() 返回一個視圖對象,值為字典的 value ,可將其轉換成列表。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.values()
output:dict_values([‘Dream丶killer’, ‘Python新視野’])
pop() 刪除指定 key 的 key/value ,如果 key 沒有找到,則報錯。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.pop('CSDN')
dic
output:{‘公眾號’: ‘Python新視野’}
popitem() 刪除字典中末尾的元素,並返回一個元組的(鍵,值)對。字典為空則報錯。
dic = {'CSDN': 'Dream丶killer',
'公眾號': 'Python新視野'}
dic.popitem()
output:(‘公眾號’, ‘Python新視野’)
向集合中添加一個元素,但如果該元素已經出現在集合中,則不起作用。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1.add('python')
set1
output:{‘’, ‘Python新視野’, ‘python’, ‘python-sun’}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1.add('python-sun')
set1
output:{‘’, ‘Python新視野’, ‘python-sun’}
添加的元素 python-sun 已經出現在集合中,所以 set1 不發生變化
clear() 移除集合中的所有元素。
set1 = {'',
'Python新視野',
'python-sun'}
set1.clear()
set1
output:set()
1 difference() 返回多個集合的差集,通俗來講就是返回第一個 set 中哪些元素沒有在其他 set 中出現。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python', ''}
set3 = {'Python新視野'}
set1.difference(set2, set3)
output:{‘python-sun’}
set1 中的元素只有 python-sun 沒有在 set2 與 set3 中出現過,所以以及集合的形式返回 {'python-sun'}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python', ''}
set3 = {'Python新視野', 'python-sun'}
set1.difference(set2, set3)
output:set()
set1 中的元素都在 set2 與 set3 中出現過,所以返回空集合 set()
2 difference_update() 方法與 difference() 方法的區別在於 difference() 方法返回一個移除相同元素的新集合,而 difference_update() 方法是直接移除原集合中的元素,無返回值。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python', ''}
set3 = {'Python新視野'}
set1.difference_update(set2, set3)
set1
output:{‘python-sun’}
set1 中的元素 與 Python新視野 都有在 set2 與 set3 中出現過,所以從 set1 中移除這些值
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python', ''}
set3 = {'Python新視野', 'python-sun'}
set1.difference_update(set2, set3)
set1
output:set()
set1 中的元素都在 set2 與 set3 中出現過,set1 移除所有值後為空集合 set()
discard() 刪除集合中指定的元素。如果指定移除的元素不在集合中,則不移除。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1.discard('')
set1
output:{‘Python新視野’, ‘python-sun’}
指定的元素存在於 set1 ,將它存 set1 中移除
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1.discard('python')
set1
output:{‘’, ‘Python新視野’, ‘python-sun’}
指定的元素不在 set1 內,set1 不做改變
1 intersection() 返回集合的交集。沒有交集則返回空集 set() 。
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python-sun', ''}
set3 = {'Python新視野', 'python-sun'}
set1.intersection(set2, set3)
output:{‘python-sun’}
返回 set1、set2、set3 中同時出現的元素
2 intersection_update() 方法與 intersection() 方法的區別在於 intersection() 方法將集合的交集作為新集合返回,而 intersection_update() 方法是直接修改原集合中的元素,只保留交集元素,無返回值。
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python-sun', ''}
set3 = {'Python新視野', 'python-sun'}
set1.intersection_update(set2, set3)
set1
output:{‘python-sun’}
set1 中只有 'python-sun 同時在 set2 與 set3 中出現過,因此移除 set1 中其他元素
isdisjoint() 判斷兩個集合是否包含相同的元素,有則返回 False,無則返回 True。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python-sun', ''}
set1.isdisjoint(set2)
output:False
set1 與 set2 中有兩個相同元素,返回 False
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python'}
set1.isdisjoint(set2)
output:True
set1 與 set2 中無相同元素,返回 True
set2.issubset(set1) 判斷集合 set2 是否為 set1 集合的子集。是則返回 True,否則返回 False。
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python-sun', ''}
set2.issubset(set1)
output:True
set2 是 set1 集合的子集,故返回 True ,使用時需注意 set1 與 set2 的位置順序。如果寫成 set1.issubset(set2) 則會返回 False
set1.issuperset(set2) 判斷集合 set2 是否為 set1 集合的子集。是則返回 True,否則返回 False。它與 issubset() 用法相同,只有參數的位置相反而已。
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python-sun', ''}
set1.issuperset(set2)
output:True
pop() 移除並返回集合中的任意元素。如果該集合為空集則報錯。
set1 = {'',
'Python新視野',
'python-sun'}
set1.pop()
output:‘python-sun’
remove() 從集合中移除指定的元素,如果該元素不在集合中,則發生報錯。
set1 = {'',
'Python新視野',
'python-sun'}
set1.remove('')
set1
output:{‘Python新視野’, ‘python-sun’}
symmetric_difference() 返回兩個集合中不重復的元素集合,即兩個集合的補集,與 ^ 的作用相同。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python', 'python-sun', ''}
set1.symmetric_difference(set2)
output:{‘Python新視野’, ‘python’}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python',
'python-sun',
''}
set1 ^ set2
output:{‘Python新視野’, ‘python’}
結果與上面相同
set1.symmetric_difference_update(set2) 移除 set1 中在 set2 相同的元素,並將 set2 集合中不同的元素插入到 set1 中。簡單來說就是把 set1 與 set2 的補集賦值給 set1。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python',
'python-sun',
''}
set1.symmetric_difference_update(set2)
set1
output:{‘Python新視野’, ‘python’}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python',
'python-sun',
''}
set1 = set1 ^ set2
set1
output:{‘Python新視野’, ‘python’}
union() 返回多個集合的並集。與 | 的作用相同。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python',
'python-sun',
''}
set3 = {'ABC'}
set1.union(set2, set3)
output:{‘ABC’, ‘’, ‘Python新視野’, ‘python’, ‘python-sun’}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set2 = {'python',
'python-sun',
''}
set3 = {'ABC'}
set1 | set2 | set3
output:{‘ABC’, ‘’, ‘Python新視野’, ‘python’, ‘python-sun’}
update() 使用本身和其他的聯合來更新集合。
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1.update([1,2,3])
set1
output:{1, 2, 3, ‘’, ‘Python新視野’, ‘python-sun’}
示例 ??
set1 = {'',
'Python新視野',
'python-sun'}
set1 = set1 | set([1,2,3])
set1
output:{1, 2, 3, ‘’, ‘Python新視野’, ‘python-sun’}
使用 | 也可以達到相同的效果。
對於剛入門 Python 或是想要入門 Python 的小伙伴,可以通過下方小卡片聯系作者**,一起交流學習,都是從新手走過來的,有時候一個簡單的問題卡很久,但可能別人的一點撥就會恍然大悟,由衷的希望大家能夠共同進步。另有整理的近千套簡歷模板,幾百冊電子書等你來領取哦!**
也可以直接加本人微信,備注:【交流群】,我拉你進Python交流群???
??? 關注小卡片,回復“交流群”,一起學習Python???
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦