1.線程是程序執行的最小單位,而進程是操作系統分配資源的最小單位 2.一個進程由一個或多個線程組成,線程是一個進程中代碼的不同執行路線 3.進程之間相互獨立,但同一個進程下的各個線程之間共享程序的內存空間(包括代碼段,數據集,堆等)及一些進程級的資源(如打開文件和信號等),某進程內的線程在其他進程不可見; 4.調度和切換:線程上下文切換比進程上下文切換要快得多
菜鳥教程連接:Python 多線程 | 菜鳥教程
多線程類似於同時執行多個不同程序,多線程運行有如下優點:
線程在執行過程中與進程還是有區別的。每個獨立的進程有一個程序運行的入口、順序執行序列和程序的出口。但是線程不能夠獨立執行,必須依存在應用程序中,由應用程序提供多個線程執行控制。
每個線程都有他自己的一組CPU寄存器,稱為線程的上下文,該上下文反映了線程上次運行該線程的CPU寄存器的狀態。
指令指針和堆棧指針寄存器是線程上下文中兩個最重要的寄存器,線程總是在進程得到上下文中運行的,這些地址都用於標志擁有線程的進程地址空間中的內存。
Python中使用線程有兩種方式:函數或者用類來包裝線程對象。
函數式:調用thread模塊中的start_new_thread()函數來產生新線程。語法如下:
thread.start_new_thread ( function, args[, kwargs] )線程使用有兩種方式:
1:通過調用thread模塊中的start_new_thread()函數來產生新線程。
2:通過類和繼承實現線程的調用
threading 模塊提供的其他方法:
除了使用方法外,線程模塊同樣提供了Thread類來處理線程,Thread類提供了以下方法:
視頻學習連接:python語言愛好者的個人空間_哔哩哔哩_Bilibili
"""創建多線程"""
import threading
import time
"""
# 1.線程是程序執行的最小單位,而進程是操作系統分配資源的最小單位
# 2.一個進程由一個或多個線程組成,線程是一個進程中代碼的不同執行路線
# 3.進程之間相互獨立,但同一個進程下的各個線程之間共享程序的內存空間(包括代碼段,數據集,堆等)
# 及一些進程級的資源(如打開文件和信號等),某進程內的線程在其他進程不可見;
# 4.調度和切換:線程上下文切換比進程上下文切換要快得多
"""
def aa(x):
print(x)
time.sleep(2) # 延遲兩秒
t1 = threading.Thread(target=aa,args=(1,)) # 調用threading.Thread()函數 target=方法名 args(參數, ) 如果沒有參數,則threading.Thread(target=方法名)即可
t2 = threading.Thread(target=aa, args=(2,)) # 傳入參數2
t1.start() # 啟動多線程
t2.start() # 啟動多線程
# 用類來創建多線程
#創建類 繼承自threading.Thread
class MyThread(threading.Thread):
def __init__(self,n): #初始化 並傳遞參數
super(MyThread, self).__init__() #繼承自父類的初始化
self.n = n
#啟動線程的函數 函數名必須是run
def run(self):
print("以類的方式創建多線程",self.n)
#調用類多線程
r1=MyThread(11) #實例化所創建的類
r2=MyThread(22) #實例化所創建的類
r1.start() # 啟動多線程
r2.start() # 啟動多線程多線程的特性:
"""多線程的特性"""
import threading
import time
def run(x):
print(f"程序{x}") # f方法:格式化字符串
time.sleep(2)
# 查看當前的線程
print(threading.current_thread())
#程序主入口
if __name__ == '__main__':
start_time = time.time() # 在程序運行之前獲取當前的時間戳
res=[] #創建空列表接受線程
for i in range(10): #循環執行函數 創建50個多線程
t = threading.Thread(target=run,args=(i, )) #創建線程
t.setDaemon(True)#守護線程 設置之後 線程運行完畢直接結束 不再等待 直接退出整個程序
t.start() #啟動線程
res.append(t) #將執行的線程添加到列表裡
# 查看活動的線程個數
print(threading.active_count()) #if __name__ == '__main__'也屬於一個線程 最終結果會比線程數多一
# for t in res: #遍歷列表 線程列表
# t.join()
# t.join() #等待函數 等t1運行結束之後再開始執行t2
end_time = time.time() # 在程序運行結束後獲取時間戳
print(f"run()函數共運行了{end_time - start_time}秒") # 輸出結束和起始時間的時間差 即為程序
#1970年到現在共走了多少秒
print(time.time()) #查看程序運行時間
run(1) #程序運行次數
run(2) #程序運行次數
print(f"run()函數共運行了{end_time - start_time}秒") #輸出結束和起始時間的時間差 即為程序運行時間
t1 = threading.Thread(target=run,args=(1, ))
t2 = threading.Thread(target=run, args=(2,))
t1.start()
t1.join() #等待函數 等t1運行結束之後再開始執行t2
t2.start()
#查看活動的線程個數
print(threading.active_count())
#查看當前的線程
print(threading.current_thread())如果多個線程共同對某個數據修改,則可能出現不可預料的結果,為了保證數據的正確性,需要對多個線程進行同步。
使用Thread對象的Lock和Rlock可以實現簡單的線程同步,這兩個對象都有acquire方法和release方法,對於那些需要每次只允許一個線程操作的數據,可以將其操作放到acquire和release方法之間。如下:
多線程的優勢在於可以同時運行多個任務(至少感覺起來是這樣)。但是當線程需要共享數據時,可能存在數據不同步的問題。
考慮這樣一種情況:一個列表裡所有元素都是0,線程"set"從後向前把所有元素改成1,而線程"print"負責從前往後讀取列表並打印。
那麼,可能線程"set"開始改的時候,線程"print"便來打印列表了,輸出就成了一半0一半1,這就是數據的不同步。為了避免這種情況,引入了鎖的概念。
鎖有兩種狀態——鎖定和未鎖定。每當一個線程比如"set"要訪問共享數據時,必須先獲得鎖定;如果已經有別的線程比如"print"獲得鎖定了,那麼就讓線程"set"暫停,也就是同步阻塞;等到線程"print"訪問完畢,釋放鎖以後,再讓線程"set"繼續。
經過這樣的處理,打印列表時要麼全部輸出0,要麼全部輸出1,不會再出現一半0一半1的尴尬場面。
"""線程鎖"""
import threading
def run():
# Python中定義函數時,若想在函數內部對函數外的變量進行操作,就需要在函數內部聲明其為global。
global x
lock.acquire() # 申請一把鎖 防止多個線程同時操作同一個變量
# python3裡邊已經解決了這個問題不會讓多個線程同時操作同一個變量 但python2裡存在這個問題
x += 1
lock.release() # 釋放鎖
if __name__ == '__main__':
x = 0
res = []
# 線程鎖
lock = threading.Lock()
for i in range(50):
t = threading.Thread(target=run) # 創建多線程
t.start()
res.append(t)
for t in res:
t.join()
print(x)
"""遞歸鎖"""
import threading
def run1():
global x
lock.acquire() # 申請一把鎖 鎖2
x += 1
lock.release() # 釋放鎖 鎖2
return x
def run2():
global y
lock.acquire() # 申請一把鎖
y += 1
lock.release() # 釋放鎖
return y
def run3():
lock.acquire() # 鎖1
tes1 = run1()
tes2 = run2()
lock.release() # 鎖1
print(tes1, tes2)
if __name__ == '__main__':
x = 0
y = 0
lock = threading.RLock() # 創建線程鎖 RLock()為遞歸鎖(稱為可重入鎖) 防止鎖之間的嵌套
# 可重入鎖必須由獲得它的線程釋放。
# 一旦一個線程獲得了一個可重入鎖,這個線程就可以在不阻塞的情況下再次獲得它;
# 線程必須在每次獲取它時釋放它一次。
for i in range(50):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1: # threading.active_count() 查看正在運行的線程的個數
print(f'正在運行{threading.active_count()}個線程')
print('程序運行結束')
Python的Queue模塊中提供了同步的、線程安全的隊列類,包括FIFO(先入先出)隊列Queue,LIFO(後入先出)隊列LifoQueue,和優先級隊列PriorityQueue。這些隊列都實現了鎖原語,能夠在多線程中直接使用。可以使用隊列來實現線程間的同步。
Queue模塊中的常用方法:
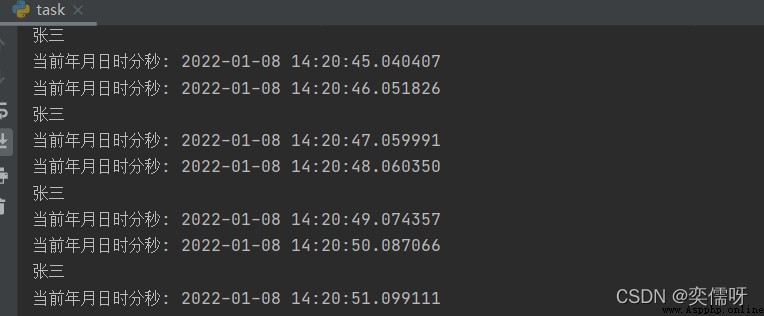
此次任務: 在一個線程中,每秒循環輸出當前的年月日時分秒;與此同時,在另一個線程中,實現張三姓名每2秒打印輸出4次結束
import threading
import datetime
import time
# 用類來創建多線程
#創建類 繼承自threading.Thread
class MyThread(threading.Thread):
def __init__(self): #初始化 並傳遞參數
super(MyThread, self).__init__() #繼承自父類的初始化
# 啟動線程的函數 函數名必須是run
def run(self):
while 1:
day = datetime.datetime.now()
time.sleep(1) # 延遲一秒
print("當前年月日時分秒:", day)
# 用類來創建多線程
#創建類 繼承自threading.Thread
class mythread(threading.Thread):
def __init__(self): #初始化 並傳遞參數
super(mythread, self).__init__() #繼承自父類的初始化
# 啟動線程的函數 函數名必須是run
def run(self):
i=0
while i<4:
time.sleep(2) # 延遲兩秒
print("張三")
i +=1
#程序主入口
if __name__ == '__main__':
#調用類多線程
r1=MyThread() #實例化所創建的類
r2=mythread() #實例化所創建的類
r1.start() # 啟動多線程
r2.start() # 啟動多線程
輸出結果: