import numpy as np
import pandas as pd
對象創建 Series通過傳遞值列表來創建a,讓pandas創建一個默認整數索引 s = pd.Series([1,3,5,np.nan,6,8])
s
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
DataFrame通過傳遞一個Numpy數組、一個日期時間索引和標簽列來創建一個: dates = pd.date_range("2022-06-07",periods=6)
dates
DatetimeIndex(['2022-06-07', '2022-06-08', '2022-06-09', '2022-06-10',
'2022-06-11', '2022-06-12'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list("ABCD"))
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
DataFrame通過傳遞可以轉換為類似系列結構的對象字典來創建a: df2 = pd.DataFrame(
{
"A":1.0,
"B":pd.Timestamp("20130102"),
"C":pd.Series(1,index=list(range(4)),dtype="float32"),
"D":np.array([3]*4,dtype="int32"),
"E":pd.Categorical(["test","train","test","train"]),
"F":"foo",
})
df2
A B C D E F 0 1.02013-01-021.03testfoo
1 1.02013-01-021.03trainfoo
2 1.02013-01-021.03testfoo
3 1.02013-01-021.03trainfoo
df3 = pd.DataFrame(
{
"A":1.0,
"B":pd.Timestamp("20130102"),
"C":pd.Series(1,index=list(range(5)),dtype="float32"),
"D":np.array([3]*5,dtype="int32"),
"E":pd.Categorical(["test","train","test","train","a"]),
"F":"foo",
})
df3
A B C D E F 0 1.02013-01-021.03testfoo
1 1.02013-01-021.03trainfoo
2 1.02013-01-021.03testfoo
3 1.02013-01-021.03trainfoo
4 1.02013-01-021.03afoo
df2
A B C D E F 0 1.02013-01-021.03testfoo
1 1.02013-01-021.03trainfoo
2 1.02013-01-021.03testfoo
3 1.02013-01-021.03trainfoo
# 結果的列DataFrame具有不同的dtypes
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
如果您使用的是IPython,則會自動啟用列名(以及公共屬性)的制表符(Tab鍵)補全。 df2.A
0 1.0
1 1.0
2 1.0
3 1.0
Name: A, dtype: float64
df2.abs
<bound method NDFrame.abs of A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo>
df2.add
<bound method flex_arith_method_FRAME.<locals>.f of A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo>
df2.all
<bound method NDFrame._add_numeric_operations.<locals>.all of A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo>
查看數據 df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
# 前三行
df.head()
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
df.head(3)
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
df.tail()
A B C D 2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
# 後三行
df.tail(3)
A B C D 2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
# 顯示索引
df.index
DatetimeIndex(['2022-06-07', '2022-06-08', '2022-06-09', '2022-06-10',
'2022-06-11', '2022-06-12'],
dtype='datetime64[ns]', freq='D')
# 顯示列
df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
注意:DataFrame.to_numpy()給出底層數據的NumPy表示,請注意,當您的DataFrame列具有不同的數據類型時,這可能是一項昂貴的操作,這歸結為pandas和NumPy之間的根本區別:NumPy數組對整個數組有一個dtype,而pandas 對於df,我們DataFrame的所有浮點值,DataFrame.to_numpy()速度很快並且不需要復制數據: df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.dtypes
A float64
B float64
C float64
D float64
dtype: object
df.to_numpy()
array([[ 0.40526325, 0.46532668, 0.07694617, -0.3115456 ],
[ 0.06912909, 0.9769407 , -0.28743027, 1.08426954],
[-0.20022708, 1.17280586, 1.34307017, 0.56144631],
[-0.34616439, -1.60996101, 1.18171013, 0.04600243],
[-1.83349661, -0.26301183, 0.36815984, 0.16598165],
[-0.61690579, 0.95554251, -0.60358546, 0.89023561]])
df2
A B C D E F 0 1.02013-01-021.03testfoo
1 1.02013-01-021.03trainfoo
2 1.02013-01-021.03testfoo
3 1.02013-01-021.03trainfoo
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
df2.to_numpy()
array([[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo']],
dtype=object)
df.index
DatetimeIndex(['2022-06-07', '2022-06-08', '2022-06-09', '2022-06-10',
'2022-06-11', '2022-06-12'],
dtype='datetime64[ns]', freq='D')
df2.index
Int64Index([0, 1, 2, 3], dtype='int64')
# describe()方法一般用於對數據進行統計學估計,輸出行名分別為:count(行數),mean(平均值),std(標准差),min(最小值),25%(第一四分位數),50%(第二四分位數),75%(第三四分位數),max(最大值)。
df.describe()
A B C D count 6.0000006.0000006.0000006.000000
mean -0.4204000.2829400.3464780.406065
std 0.7759901.0621010.7833760.533062
min -1.833497-1.609961-0.603585-0.311546
25% -0.549220-0.080927-0.1963360.075997
50% -0.2731960.7104350.2225530.363714
75% 0.0017900.9715910.9783230.808038
max 0.4052631.1728061.3430701.084270
# 轉置數據
df.T
2022-06-07 2022-06-08 2022-06-09 2022-06-10 2022-06-11 2022-06-12 A 0.4052630.069129-0.200227-0.346164-1.833497-0.616906
B 0.4653270.9769411.172806-1.609961-0.2630120.955543
C 0.076946-0.2874301.3430701.1817100.368160-0.603585
D -0.3115461.0842700.5614460.0460020.1659820.890236
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df2
A B C D E F 0 1.02013-01-021.03testfoo
1 1.02013-01-021.03trainfoo
2 1.02013-01-021.03testfoo
3 1.02013-01-021.03trainfoo
df2.columns
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
df2.describe()
A C D count 4.04.04.0
mean 1.01.03.0
std 0.00.00.0
min 1.01.03.0
25% 1.01.03.0
50% 1.01.03.0
75% 1.01.03.0
max 1.01.03.0
df2.T
0 1 2 3 A 1.01.01.01.0
B 2013-01-02 00:00:002013-01-02 00:00:002013-01-02 00:00:002013-01-02 00:00:00
C 1.01.01.01.0
D 3333
E testtraintesttrain
F foofoofoofoo
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.T
2022-06-07 2022-06-08 2022-06-09 2022-06-10 2022-06-11 2022-06-12 A 0.4052630.069129-0.200227-0.346164-1.833497-0.616906
B 0.4653270.9769411.172806-1.609961-0.2630120.955543
C 0.076946-0.2874301.3430701.1817100.368160-0.603585
D -0.3115461.0842700.5614460.0460020.1659820.890236
# sort_index()方法專門用於對index排序
# axis=0對應的是對左邊一列的index進行排序(列排); axis=1對應的是對上邊一行的index進行排序(行排)
# ascending=False代表降序
df.sort_index(axis=1,ascending=False)
D C B A 2022-06-07 -0.3115460.0769460.4653270.405263
2022-06-08 1.084270-0.2874300.9769410.069129
2022-06-09 0.5614461.3430701.172806-0.200227
2022-06-10 0.0460021.181710-1.609961-0.346164
2022-06-11 0.1659820.368160-0.263012-1.833497
2022-06-12 0.890236-0.6035850.955543-0.616906
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.sort_index(axis=0,ascending=False)
A B C D 2022-06-12 -0.6169060.955543-0.6035850.890236
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-07 0.4052630.4653270.076946-0.311546
df.sort_index(axis=1,ascending=False)
D C B A 2022-06-07 -0.3115460.0769460.4653270.405263
2022-06-08 1.084270-0.2874300.9769410.069129
2022-06-09 0.5614461.3430701.172806-0.200227
2022-06-10 0.0460021.181710-1.609961-0.346164
2022-06-11 0.1659820.368160-0.263012-1.833497
2022-06-12 0.890236-0.6035850.955543-0.616906
df.sort_index(axis=0,ascending=False)
A B C D 2022-06-12 -0.6169060.955543-0.6035850.890236
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-07 0.4052630.4653270.076946-0.311546
df.sort_index(axis=0,ascending=True)
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.T
2022-06-07 2022-06-08 2022-06-09 2022-06-10 2022-06-11 2022-06-12 A 0.4052630.069129-0.200227-0.346164-1.833497-0.616906
B 0.4653270.9769411.172806-1.609961-0.2630120.955543
C 0.076946-0.2874301.3430701.1817100.368160-0.603585
D -0.3115461.0842700.5614460.0460020.1659820.890236
# 對df進行轉置,然後按軸排序(降序)
df.T.sort_index(axis=1,ascending=False)
2022-06-12 2022-06-11 2022-06-10 2022-06-09 2022-06-08 2022-06-07 A -0.616906-1.833497-0.346164-0.2002270.0691290.405263
B 0.955543-0.263012-1.6099611.1728060.9769410.465327
C -0.6035850.3681601.1817101.343070-0.2874300.076946
D 0.8902360.1659820.0460020.5614461.084270-0.311546
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
# 按值排序
df.sort_values(by="B")
A B C D 2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-12 -0.6169060.955543-0.6035850.890236
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
"
df.sort_values(
by,
axis: 'Axis' = 0,
ascending=True,
inplace: 'bool' = False,
kind: 'str' = 'quicksort',
na_position: 'str' = 'last',
ignore_index: 'bool' = False,
key: 'ValueKeyFunc' = None,
)
"
df.sort_values(axis=1,by="2022-06-10")
B A D C 2022-06-07 0.4653270.405263-0.3115460.076946
2022-06-08 0.9769410.0691291.084270-0.287430
2022-06-09 1.172806-0.2002270.5614461.343070
2022-06-10 -1.609961-0.3461640.0460021.181710
2022-06-11 -0.263012-1.8334970.1659820.368160
2022-06-12 0.955543-0.6169060.890236-0.603585
df.sort_values(axis=0,by="B")
A B C D 2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-12 -0.6169060.955543-0.6035850.890236
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
選擇 雖然用於選擇和設置的標准Python/NumPy表達式很直觀,並且在交互工作中派上用場,但對於生產代碼,我們推薦優化的pandas數據訪問方法.at、、、、.iat和.loc .iloc 獲取 選擇單個列,這會產生a Series,相當於df.A: df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df["A"]
2022-06-07 0.405263
2022-06-08 0.069129
2022-06-09 -0.200227
2022-06-10 -0.346164
2022-06-11 -1.833497
2022-06-12 -0.616906
Freq: D, Name: A, dtype: float64
df["D"]
2022-06-07 -0.311546
2022-06-08 1.084270
2022-06-09 0.561446
2022-06-10 0.046002
2022-06-11 0.165982
2022-06-12 0.890236
Freq: D, Name: D, dtype: float64
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df[0:3]
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
df["20220608":"20220611"]
A B C D 2022-06-08 0.0691290.976941-0.287431.084270
2022-06-09 -0.2002271.1728061.343070.561446
2022-06-10 -0.346164-1.6099611.181710.046002
2022-06-11 -1.833497-0.2630120.368160.165982
按標簽選擇 df.loc[dates[0]]
A 0.405263
B 0.465327
C 0.076946
D -0.311546
Name: 2022-06-07 00:00:00, dtype: float64
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.loc()
<pandas.core.indexing._LocIndexer at 0x162f252a130>
df.loc[dates[1]]
A 0.069129
B 0.976941
C -0.287430
D 1.084270
Name: 2022-06-08 00:00:00, dtype: float64
df.loc[dates[2]]
A -0.200227
B 1.172806
C 1.343070
D 0.561446
Name: 2022-06-09 00:00:00, dtype: float64
df.loc[:,]
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.loc[:,["A","B"]]
A B 2022-06-07 0.4052630.465327
2022-06-08 0.0691290.976941
2022-06-09 -0.2002271.172806
2022-06-10 -0.346164-1.609961
2022-06-11 -1.833497-0.263012
2022-06-12 -0.6169060.955543
df.loc[["20220607","20220609"],["C","D"]]
C D 2022-06-07 0.076946-0.311546
2022-06-09 1.3430700.561446
df.loc[["20220607","20220611"],["A","D"]]
A D 2022-06-07 0.405263-0.311546
2022-06-11 -1.8334970.165982
df.loc[["20220611"],["A","D"]]
A D 2022-06-11 -1.8334970.165982
df.loc["20220611",["A","D"]]
A -1.833497
D 0.165982
Name: 2022-06-11 00:00:00, dtype: float64
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.loc[dates[0]]
A 0.405263
B 0.465327
C 0.076946
D -0.311546
Name: 2022-06-07 00:00:00, dtype: float64
df.loc[dates[1]]
A 0.069129
B 0.976941
C -0.287430
D 1.084270
Name: 2022-06-08 00:00:00, dtype: float64
df.loc[dates[1],"A"]
0.06912908863219207
df.loc[dates[1],"C"]
-0.28743026681864575
df.at[dates[0],"A"]
0.40526325343260083
df.at[dates[1],"C"]
-0.28743026681864575
按位置選擇 df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.iloc[3]
A -0.346164
B -1.609961
C 1.181710
D 0.046002
Name: 2022-06-10 00:00:00, dtype: float64
df.iloc[4]
A -1.833497
B -0.263012
C 0.368160
D 0.165982
Name: 2022-06-11 00:00:00, dtype: float64
df.iloc[3:5]
A B C D 2022-06-10 -0.346164-1.6099611.181710.046002
2022-06-11 -1.833497-0.2630120.368160.165982
df.iloc[3:5,0:2]
A B 2022-06-10 -0.346164-1.609961
2022-06-11 -1.833497-0.263012
通過整數位置列表,類似於Numpy/Python樣式 df.iloc[[1,2,4],[0,2]]
A C 2022-06-08 0.069129-0.28743
2022-06-09 -0.2002271.34307
2022-06-11 -1.8334970.36816
df.iloc[1:3,:]
A B C D 2022-06-08 0.0691290.976941-0.287431.084270
2022-06-09 -0.2002271.1728061.343070.561446
df.iloc[1:3,2:3]
C 2022-06-08 -0.28743
2022-06-09 1.34307
df.iloc[:,1:3]
B C 2022-06-07 0.4653270.076946
2022-06-08 0.976941-0.287430
2022-06-09 1.1728061.343070
2022-06-10 -1.6099611.181710
2022-06-11 -0.2630120.368160
2022-06-12 0.955543-0.603585
df.iloc[1:4,1:3]
B C 2022-06-08 0.976941-0.28743
2022-06-09 1.1728061.34307
2022-06-10 -1.6099611.18171
df.iloc[1,1]
0.9769407016879463
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.iloc[3,3]
0.04600243177073029
df.iat[1,1]
0.9769407016879463
df.iat[3,3]
0.04600243177073029
布爾索引 df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df["A"]
2022-06-07 0.405263
2022-06-08 0.069129
2022-06-09 -0.200227
2022-06-10 -0.346164
2022-06-11 -1.833497
2022-06-12 -0.616906
Freq: D, Name: A, dtype: float64
df["A"]>0
2022-06-07 True
2022-06-08 True
2022-06-09 False
2022-06-10 False
2022-06-11 False
2022-06-12 False
Freq: D, Name: A, dtype: bool
df[df["A"]>0]
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
df
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df[df["B"] < 0]
A B C D 2022-06-10 -0.346164-1.6099611.181710.046002
2022-06-11 -1.833497-0.2630120.368160.165982
df3 = df.copy()
df3
A B C D 2022-06-07 0.4052630.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df3["E"] = ["zero","one","two","three","four","five"]
df3
A B C D E 2022-06-07 0.4052630.4653270.076946-0.311546zero
2022-06-08 0.0691290.976941-0.2874301.084270one
2022-06-09 -0.2002271.1728061.3430700.561446two
2022-06-10 -0.346164-1.6099611.1817100.046002three
2022-06-11 -1.833497-0.2630120.3681600.165982four
2022-06-12 -0.6169060.955543-0.6035850.890236five
df3["E"]
2022-06-07 zero
2022-06-08 one
2022-06-09 two
2022-06-10 three
2022-06-11 four
2022-06-12 five
Freq: D, Name: E, dtype: object
df3["E"].isin(["two"])
2022-06-07 False
2022-06-08 False
2022-06-09 True
2022-06-10 False
2022-06-11 False
2022-06-12 False
Freq: D, Name: E, dtype: bool
df3["E"].isin(["two","four"])
2022-06-07 False
2022-06-08 False
2022-06-09 True
2022-06-10 False
2022-06-11 True
2022-06-12 False
Freq: D, Name: E, dtype: bool
df3[df3["E"].isin(["two","four"])]
A B C D E 2022-06-09 -0.2002271.1728061.343070.561446two
2022-06-11 -1.833497-0.2630120.368160.165982four
設置 s1 = pd.Series([1,2,3,4,5,6],index=pd.date_range("20220607",periods=6))
s1
2022-06-07 1
2022-06-08 2
2022-06-09 3
2022-06-10 4
2022-06-11 5
2022-06-12 6
Freq: D, dtype: int64
df.at[dates[0],"A"] = 0
df
A B C D 2022-06-07 0.0000000.4653270.076946-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df
A B C D 2022-06-07 0.0000000.0000000.000000-0.311546
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.iat[0,3]=0
df
A B C D 2022-06-07 0.0000000.0000000.0000000.000000
2022-06-08 0.0691290.976941-0.2874301.084270
2022-06-09 -0.2002271.1728061.3430700.561446
2022-06-10 -0.346164-1.6099611.1817100.046002
2022-06-11 -1.833497-0.2630120.3681600.165982
2022-06-12 -0.6169060.955543-0.6035850.890236
df.loc[:,"D"]
2022-06-07 0.000000
2022-06-08 1.084270
2022-06-09 0.561446
2022-06-10 0.046002
2022-06-11 0.165982
2022-06-12 0.890236
Freq: D, Name: D, dtype: float64
df.loc[:,"D"] = np.array([5] * len(df))
df
A B C D 2022-06-07 0.0000000.0000000.0000005
2022-06-08 0.0691290.976941-0.2874305
2022-06-09 -0.2002271.1728061.3430705
2022-06-10 -0.346164-1.6099611.1817105
2022-06-11 -1.833497-0.2630120.3681605
2022-06-12 -0.6169060.955543-0.6035855
df.loc[:,"F"] = np.array([i for i in range(6)])
df
A B C D F 2022-06-07 0.0000000.0000000.00000050
2022-06-08 0.0691290.976941-0.28743051
2022-06-09 -0.2002271.1728061.34307052
2022-06-10 -0.346164-1.6099611.18171053
2022-06-11 -1.833497-0.2630120.36816054
2022-06-12 -0.6169060.955543-0.60358555
df.loc[:,"E"] = np.array([5] * len(df))
df
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df4 = df.copy()
df4
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df4 > 0
A B C D F E 2022-06-07 FalseFalseFalseTrueFalseTrue
2022-06-08 TrueTrueFalseTrueTrueTrue
2022-06-09 FalseTrueTrueTrueTrueTrue
2022-06-10 FalseFalseTrueTrueTrueTrue
2022-06-11 FalseFalseTrueTrueTrueTrue
2022-06-12 FalseTrueFalseTrueTrueTrue
df4[df4>0]
A B C D F E 2022-06-07 NaNNaNNaN5NaN5
2022-06-08 0.0691290.976941NaN51.05
2022-06-09 NaN1.1728061.3430752.05
2022-06-10 NaNNaN1.1817153.05
2022-06-11 NaNNaN0.3681654.05
2022-06-12 NaN0.955543NaN55.05
-df4
A B C D F E 2022-06-07 -0.000000-0.000000-0.000000-50-5
2022-06-08 -0.069129-0.9769410.287430-5-1-5
2022-06-09 0.200227-1.172806-1.343070-5-2-5
2022-06-10 0.3461641.609961-1.181710-5-3-5
2022-06-11 1.8334970.263012-0.368160-5-4-5
2022-06-12 0.616906-0.9555430.603585-5-5-5
# 條件符合的不變,條件不符合的變為相反數
df4[df4>0] = -df4
df4
A B C D F E 2022-06-07 0.0000000.0000000.000000-50-5
2022-06-08 -0.069129-0.976941-0.287430-5-1-5
2022-06-09 -0.200227-1.172806-1.343070-5-2-5
2022-06-10 -0.346164-1.609961-1.181710-5-3-5
2022-06-11 -1.833497-0.263012-0.368160-5-4-5
2022-06-12 -0.616906-0.955543-0.603585-5-5-5
df4
A B C D F E 2022-06-07 0.0000000.0000000.000000-50-5
2022-06-08 -0.069129-0.976941-0.287430-5-1-5
2022-06-09 -0.200227-1.172806-1.343070-5-2-5
2022-06-10 -0.346164-1.609961-1.181710-5-3-5
2022-06-11 -1.833497-0.263012-0.368160-5-4-5
2022-06-12 -0.616906-0.955543-0.603585-5-5-5
df3
A B C D E 2022-06-07 0.4052630.4653270.076946-0.311546zero
2022-06-08 0.0691290.976941-0.2874301.084270one
2022-06-09 -0.2002271.1728061.3430700.561446two
2022-06-10 -0.346164-1.6099611.1817100.046002three
2022-06-11 -1.833497-0.2630120.3681600.165982four
2022-06-12 -0.6169060.955543-0.6035850.890236five
df6 = df.copy()
df6
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df6>0
A B C D F E 2022-06-07 FalseFalseFalseTrueFalseTrue
2022-06-08 TrueTrueFalseTrueTrueTrue
2022-06-09 FalseTrueTrueTrueTrueTrue
2022-06-10 FalseFalseTrueTrueTrueTrue
2022-06-11 FalseFalseTrueTrueTrueTrue
2022-06-12 FalseTrueFalseTrueTrueTrue
df6[df6>0]
A B C D F E 2022-06-07 NaNNaNNaN5NaN5
2022-06-08 0.0691290.976941NaN51.05
2022-06-09 NaN1.1728061.3430752.05
2022-06-10 NaNNaN1.1817153.05
2022-06-11 NaNNaN0.3681654.05
2022-06-12 NaN0.955543NaN55.05
df6
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
-df6
A B C D F E 2022-06-07 -0.000000-0.000000-0.000000-50-5
2022-06-08 -0.069129-0.9769410.287430-5-1-5
2022-06-09 0.200227-1.172806-1.343070-5-2-5
2022-06-10 0.3461641.609961-1.181710-5-3-5
2022-06-11 1.8334970.263012-0.368160-5-4-5
2022-06-12 0.616906-0.9555430.603585-5-5-5
df6[df6>0] = -df6
df6
A B C D F E 2022-06-07 0.0000000.0000000.000000-50-5
2022-06-08 -0.069129-0.976941-0.287430-5-1-5
2022-06-09 -0.200227-1.172806-1.343070-5-2-5
2022-06-10 -0.346164-1.609961-1.181710-5-3-5
2022-06-11 -1.833497-0.263012-0.368160-5-4-5
2022-06-12 -0.616906-0.955543-0.603585-5-5-5
df6
A B C D F E 2022-06-07 0.0000000.0000000.000000-50-5
2022-06-08 -0.069129-0.976941-0.287430-5-1-5
2022-06-09 -0.200227-1.172806-1.343070-5-2-5
2022-06-10 -0.346164-1.609961-1.181710-5-3-5
2022-06-11 -1.833497-0.263012-0.368160-5-4-5
2022-06-12 -0.616906-0.955543-0.603585-5-5-5
df7 = -df6
df7
A B C D F E 2022-06-07 -0.000000-0.000000-0.000000505
2022-06-08 0.0691290.9769410.287430515
2022-06-09 0.2002271.1728061.343070525
2022-06-10 0.3461641.6099611.181710535
2022-06-11 1.8334970.2630120.368160545
2022-06-12 0.6169060.9555430.603585555
df7[df7>0]
A B C D F E 2022-06-07 NaNNaNNaN5NaN5
2022-06-08 0.0691290.9769410.28743051.05
2022-06-09 0.2002271.1728061.34307052.05
2022-06-10 0.3461641.6099611.18171053.05
2022-06-11 1.8334970.2630120.36816054.05
2022-06-12 0.6169060.9555430.60358555.05
df7[df7>0]=0
df7
A B C D F E 2022-06-07 -0.0-0.0-0.0000
2022-06-08 0.00.00.0000
2022-06-09 0.00.00.0000
2022-06-10 0.00.00.0000
2022-06-11 0.00.00.0000
2022-06-12 0.00.00.0000
缺失數據 df
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df1 = df.reindex(index=dates[0:4],columns=list(df.columns) + ["E"])
df1.loc[dates[0] :dates[1],"E"] = 1
df1
A B C D F E E 2022-06-07 0.0000000.0000000.000005011
2022-06-08 0.0691290.976941-0.287435111
2022-06-09 -0.2002271.1728061.343075255
2022-06-10 -0.346164-1.6099611.181715355
df1.dropna(how="any")
A B C D F E E 2022-06-07 0.0000000.0000000.000005011
2022-06-08 0.0691290.976941-0.287435111
2022-06-09 -0.2002271.1728061.343075255
2022-06-10 -0.346164-1.6099611.181715355
df1 = df1[df1>0]
df1
A B C D F E E 2022-06-07 NaNNaNNaN5NaN11
2022-06-08 0.0691290.976941NaN51.011
2022-06-09 NaN1.1728061.3430752.055
2022-06-10 NaNNaN1.1817153.055
df1.dropna(how="any")
A B C D F E E df6
A B C D F E 2022-06-07 0.0000000.0000000.000000-50-5
2022-06-08 -0.069129-0.976941-0.287430-5-1-5
2022-06-09 -0.200227-1.172806-1.343070-5-2-5
2022-06-10 -0.346164-1.609961-1.181710-5-3-5
2022-06-11 -1.833497-0.263012-0.368160-5-4-5
2022-06-12 -0.616906-0.955543-0.603585-5-5-5
-df6
A B C D F E 2022-06-07 -0.000000-0.000000-0.000000505
2022-06-08 0.0691290.9769410.287430515
2022-06-09 0.2002271.1728061.343070525
2022-06-10 0.3461641.6099611.181710535
2022-06-11 1.8334970.2630120.368160545
2022-06-12 0.6169060.9555430.603585555
df8 = -df6[-df6>0]
df8
A B C D F E 2022-06-07 NaNNaNNaN5NaN5
2022-06-08 0.0691290.9769410.28743051.05
2022-06-09 0.2002271.1728061.34307052.05
2022-06-10 0.3461641.6099611.18171053.05
2022-06-11 1.8334970.2630120.36816054.05
2022-06-12 0.6169060.9555430.60358555.05
# 刪除任何缺少數據的行
df8.dropna(how="any")
A B C D F E 2022-06-08 0.0691290.9769410.28743051.05
2022-06-09 0.2002271.1728061.34307052.05
2022-06-10 0.3461641.6099611.18171053.05
2022-06-11 1.8334970.2630120.36816054.05
2022-06-12 0.6169060.9555430.60358555.05
df1
A B C D F E E 2022-06-07 NaNNaNNaN5NaN11
2022-06-08 0.0691290.976941NaN51.011
2022-06-09 NaN1.1728061.3430752.055
2022-06-10 NaNNaN1.1817153.055
df1.fillna(value=5)
A B C D F E E 2022-06-07 5.0000005.0000005.0000055.011
2022-06-08 0.0691290.9769415.0000051.011
2022-06-09 5.0000001.1728061.3430752.055
2022-06-10 5.0000005.0000001.1817153.055
df1
A B C D F E E 2022-06-07 NaNNaNNaN5NaN11
2022-06-08 0.0691290.976941NaN51.011
2022-06-09 NaN1.1728061.3430752.055
2022-06-10 NaNNaN1.1817153.055
pd.isna(df1)
A B C D F E E 2022-06-07 TrueTrueTrueFalseTrueFalseFalse
2022-06-08 FalseFalseTrueFalseFalseFalseFalse
2022-06-09 TrueFalseFalseFalseFalseFalseFalse
2022-06-10 TrueTrueFalseFalseFalseFalseFalse
操作 統計 df
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df.mean()
A -0.487944
B 0.205386
C 0.333654
D 5.000000
F 2.500000
E 5.000000
dtype: float64
df.mean(1)
2022-06-07 1.666667
2022-06-08 1.959773
2022-06-09 2.385941
2022-06-10 2.037597
2022-06-11 2.045275
2022-06-12 2.455842
Freq: D, dtype: float64
df.mean(0)
A -0.487944
B 0.205386
C 0.333654
D 5.000000
F 2.500000
E 5.000000
dtype: float64
使用具有不同維度且需要對齊的對象進行操作。此外,pandas會自動沿指定維度進行廣播: s = pd.Series([1,3,5,np.nan,6,8],index=dates).shift(2)
s
2022-06-07 NaN
2022-06-08 NaN
2022-06-09 1.0
2022-06-10 3.0
2022-06-11 5.0
2022-06-12 NaN
Freq: D, dtype: float64
pd.Series([1,3,5,np.nan,6,8],index=dates).shift(3)
2022-06-07 NaN
2022-06-08 NaN
2022-06-09 NaN
2022-06-10 1.0
2022-06-11 3.0
2022-06-12 5.0
Freq: D, dtype: float64
pd.Series([1,3,5,np.nan,6,8],index=dates).shift(1)
2022-06-07 NaN
2022-06-08 1.0
2022-06-09 3.0
2022-06-10 5.0
2022-06-11 NaN
2022-06-12 6.0
Freq: D, dtype: float64
pd.Series([1,3,5,np.nan,6,8],index=dates)
2022-06-07 1.0
2022-06-08 3.0
2022-06-09 5.0
2022-06-10 NaN
2022-06-11 6.0
2022-06-12 8.0
Freq: D, dtype: float64
dates
DatetimeIndex(['2022-06-07', '2022-06-08', '2022-06-09', '2022-06-10',
'2022-06-11', '2022-06-12'],
dtype='datetime64[ns]', freq='D')
pd.Series([1,3,5,np.nan,7,8],index=dates)
2022-06-07 1.0
2022-06-08 3.0
2022-06-09 5.0
2022-06-10 NaN
2022-06-11 7.0
2022-06-12 8.0
Freq: D, dtype: float64
# 默認情況下,shift函數是在行方向上移動一個單位
# shift(2)在行方向上移動兩個單位
s = pd.Series([1,3,5,np.nan,7,8],index=dates).shift(2)
s
2022-06-07 NaN
2022-06-08 NaN
2022-06-09 1.0
2022-06-10 3.0
2022-06-11 5.0
2022-06-12 NaN
Freq: D, dtype: float64
應用 df
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
np.cumsum
<function numpy.cumsum(a, axis=None, dtype=None, out=None)>
df.apply(np.cumsum)
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.28743010110
2022-06-09 -0.1310982.1497471.05564015315
2022-06-10 -0.4772620.5397862.23735020620
2022-06-11 -2.3107590.2767742.605510251025
2022-06-12 -2.9276651.2323162.001924301530
df
A B C D F E 2022-06-07 0.0000000.0000000.000000505
2022-06-08 0.0691290.976941-0.287430515
2022-06-09 -0.2002271.1728061.343070525
2022-06-10 -0.346164-1.6099611.181710535
2022-06-11 -1.833497-0.2630120.368160545
2022-06-12 -0.6169060.955543-0.603585555
df.apply(lambda x: x.max() - x.min())
A 1.902626
B 2.782767
C 1.946656
D 0.000000
F 5.000000
E 0.000000
dtype: float64
df.apply(lambda x: x.max() - x.min(),axis=1)
2022-06-07 5.000000
2022-06-08 5.287430
2022-06-09 5.200227
2022-06-10 6.609961
2022-06-11 6.833497
2022-06-12 5.616906
Freq: D, dtype: float64
series,只是一個一維數據結構,它由index和value組成。 dataframe,是一個二維結構,除了擁有index和value之外,還擁有column。 聯系: dataframe由多個series組成,無論是行還是列,單獨拆分出來都是一個series。 直方圖 s = pd.Series(np.random.randint(0,7,size=10))
s
0 2
1 5
2 2
3 4
4 1
5 3
6 0
7 2
8 5
9 4
dtype: int32
s.value_counts()
2 3
5 2
4 2
1 1
3 1
0 1
dtype: int64
字符串的方法 Series 在屬性中配備了一組字符串處理方式str,可以方便地對數組的每個元素進行操作,如下面的代碼片段所示。請注意,模式匹配str通常默認使用正則表達式 s = pd.Series(["A","B","C","Aaba","Baca",np.nan,"CABA","dog","cat"])
s
0 A
1 B
2 C
3 Aaba
4 Baca
5 NaN
6 CABA
7 dog
8 cat
dtype: object
s.str
<pandas.core.strings.accessor.StringMethods at 0x26552ed2a90>
s.str.lower()
0 a
1 b
2 c
3 aaba
4 baca
5 NaN
6 caba
7 dog
8 cat
dtype: object
s.str.upper()
0 A
1 B
2 C
3 AABA
4 BACA
5 NaN
6 CABA
7 DOG
8 CAT
dtype: object
合並 # 生成一個浮點數或N維浮點數組,取數范圍:正態分布的隨機樣本數。
df = pd.DataFrame(np.random.randn(10,4))
df
0 1 2 3 0 0.879358-0.162415-0.122199-1.436661
1 -0.0904630.173721-0.425374-0.509393
2 -1.155403-1.3515600.0327340.085148
3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
pd.DataFrame(np.random.randn(10,4))
0 1 2 3 0 -1.2310200.0629660.248977-2.006465
1 -0.121096-0.7908541.2700020.437691
2 -1.342012-0.213068-0.632990-0.454876
3 -2.299231-0.4491790.7998231.320912
4 -0.214516-0.759868-0.5099290.125942
5 1.743264-0.0472200.5321170.087455
6 -0.1720500.3876250.9032311.419179
7 0.610765-0.666323-0.3968730.956829
8 -0.7401471.3970830.3602410.106912
9 -0.4029851.289189-0.202836-1.308507
df
0 1 2 3 0 0.879358-0.162415-0.122199-1.436661
1 -0.0904630.173721-0.425374-0.509393
2 -1.155403-1.3515600.0327340.085148
3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
# 拆分
df[:3]
0 1 2 3 0 0.879358-0.162415-0.122199-1.436661
1 -0.0904630.173721-0.425374-0.509393
2 -1.155403-1.3515600.0327340.085148
df[3:7]
0 1 2 3 3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
df[7:]
0 1 2 3 7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
pieces=[df[:3],df[3:7],df[7:]]
pieces
[ 0 1 2 3
0 0.879358 -0.162415 -0.122199 -1.436661
1 -0.090463 0.173721 -0.425374 -0.509393
2 -1.155403 -1.351560 0.032734 0.085148,
0 1 2 3
3 -0.808055 -1.637611 0.382922 0.525315
4 0.659453 -0.851103 0.214721 1.031853
5 0.532633 1.506630 1.476901 -1.016453
6 0.860219 3.015384 1.003056 -2.795348,
0 1 2 3
7 0.580518 -2.575408 1.470146 -1.946652
8 -1.104715 0.954115 0.479431 1.001990
9 0.709469 -1.613924 0.424452 -0.641368]
pd.concat(pieces)
0 1 2 3 0 0.879358-0.162415-0.122199-1.436661
1 -0.0904630.173721-0.425374-0.509393
2 -1.155403-1.3515600.0327340.085148
3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
a = [df[3:]]
a
[ 0 1 2 3
3 -0.808055 -1.637611 0.382922 0.525315
4 0.659453 -0.851103 0.214721 1.031853
5 0.532633 1.506630 1.476901 -1.016453
6 0.860219 3.015384 1.003056 -2.795348
7 0.580518 -2.575408 1.470146 -1.946652
8 -1.104715 0.954115 0.479431 1.001990
9 0.709469 -1.613924 0.424452 -0.641368]
pd.concat(a)
0 1 2 3 3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
pd
<module 'pandas' from 'D:\\software\\anaconda\\lib\\site-packages\\pandas\\__init__.py'>
df
0 1 2 3 0 0.879358-0.162415-0.122199-1.436661
1 -0.0904630.173721-0.425374-0.509393
2 -1.155403-1.3515600.0327340.085148
3 -0.808055-1.6376110.3829220.525315
4 0.659453-0.8511030.2147211.031853
5 0.5326331.5066301.476901-1.016453
6 0.8602193.0153841.003056-2.795348
7 0.580518-2.5754081.470146-1.946652
8 -1.1047150.9541150.4794311.001990
9 0.709469-1.6139240.424452-0.641368
[筆記] 向a添加列DataFrame相對較快。但是,添加一行需要一個副本,並且可能很昂貴。我們建議將預先構建的記錄列表傳遞給DataFrame構造函數,而不是DataFrame通過迭代地將記錄附加到它來構建一個。 加入 left = pd.DataFrame({
"key":["foo","foo"],"lval":[1,2]})
left
key lval 0 foo1
1 foo2
right = pd.DataFrame({
"key":["foo","foo"],"rval":[4,5]})
right
key rval 0 foo4
1 bar5
pd.merge(left,right,on="key")
key lval rval 0 foo14
1 foo15
2 foo24
3 foo25
pd
<module 'pandas' from 'D:\\software\\anaconda\\lib\\site-packages\\pandas\\__init__.py'>
left
key lval 0 foo1
1 foo2
right
key rval 0 foo4
1 bar5
# pd.merge(left,right,on="rval") 會報錯,因為沒有相同字段
left = pd.DataFrame({
"key":["foo","bar"],"lval":[1,2]})
left
key lval 0 foo1
1 bar2
right = pd.DataFrame({
"key":["foo","bar"],"rval":[4,5]})
right
key rval 0 foo4
1 bar5
pd.merge(left,right,on="key")
key lval rval 0 foo14
1 bar25
分組 "分組依據"是指涉及以下一個或多個步驟的過程: 根據某些標准將數據分組 將函數獨立應用於每個組 將結果組合成數據結構 df = pd.DataFrame({
"A":["foo","bar","foo","bar","foo","bar","foo","foo"],
"B":["zero","one","two","there","four","five","six","seven"],
"C":np.random.randn(8),
"D":np.random.randn(8),
}
)
df
A B C D 0 foozero0.7295450.301263
1 barone1.6038890.458280
2 footwo0.6333821.820535
3 barthere-0.7231701.917200
4 foofour0.5814050.961305
5 barfive-1.4147550.986130
6 foosix0.5772220.851816
7 fooseven-1.3180730.757913
df.groupby("A")
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002655C66AFD0>
df.groupby("A").sum()
C D A bar -0.5340353.361610
foo 1.2034814.692833
df.index
RangeIndex(start=0, stop=8, step=1)
df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
df.groupby("D").mean()
C D 0.301263 0.729545
0.458280 1.603889
0.757913 -1.318073
0.851816 0.577222
0.961305 0.581405
0.986130 -1.414755
1.820535 0.633382
1.917200 -0.723170
df.groupby("D").sum()
C D 0.301263 0.729545
0.458280 1.603889
0.757913 -1.318073
0.851816 0.577222
0.961305 0.581405
0.986130 -1.414755
1.820535 0.633382
1.917200 -0.723170
df.sum()
A foobarfoobarfoobarfoofoo
B zeroonetwotherefourfivesixseven
C 0.669445
D 8.054443
dtype: object
df.groupby("A").sum()
C D A bar -0.5340353.361610
foo 1.2034814.692833
df.groupby("B").sum()
C D B five -1.4147550.986130
four 0.5814050.961305
one 1.6038890.458280
seven -1.3180730.757913
six 0.5772220.851816
there -0.7231701.917200
two 0.6333821.820535
zero 0.7295450.301263
按照多列分組形成層次索引,我們可以再次應用該sum()函數: df.groupby(["A","B"]).sum()
C D A B bar five -1.4147550.986130
one 1.6038890.458280
there -0.7231701.917200
foo four 0.5814050.961305
seven -1.3180730.757913
six 0.5772220.851816
two 0.6333821.820535
zero 0.7295450.301263
重塑 堆棧 tuples = list(
zip(
*[
["bar","bar","baz","baz","foo","foo","qux","que"],
["one","two","one","two","one","two","one","there"]
]
)
)
tuples
[('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('que', 'there')]
# 構造多變指標(MultiIndex)的四種方式
# from_tuples:列表中的每一個元組 構造MultiIndex
# from_arrays:根據元素的位置,一一對應形成組合 構造MultiIndex
# from_product:通過參數形成的“全組合” 構造MultiIndex
# from_frame:通過 DataFrame 構造MultiIndex
index = pd.MultiIndex.from_tuples(tuples,name=["first","second"])
index
MultiIndex([('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('que', 'there')],
names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8,2),index=index,columns=["A","B"])
df
A B first second bar one -0.4845291.071371
two -0.2951871.255282
baz one -0.3413450.790919
two -1.297284-1.285871
foo one -0.598789-0.624319
two -0.297379-2.395637
qux one -0.1949910.614675
que there 0.8663280.098695
df2 = df[:4]
df2
A B first second bar one -0.4845291.071371
two -0.2951871.255282
baz one -0.3413450.790919
two -1.297284-1.285871
該stack()方法在DataFrame的列中"壓縮"一個級別: stacked = df2.stack()
stacked
first second
bar one A -0.484529
B 1.071371
two A -0.295187
B 1.255282
baz one A -0.341345
B 0.790919
two A -1.297284
B -1.285871
dtype: float64
對於"堆疊"的DataFrame或Series (將aMultiIndexz作為),is index的逆運算,默認情況下會取消堆棧最後一層:stack()unstack() stacked
first second
bar one A -0.484529
B 1.071371
two A -0.295187
B 1.255282
baz one A -0.341345
B 0.790919
two A -1.297284
B -1.285871
dtype: float64
stacked.unstack()
A B first second bar one -0.4845291.071371
two -0.2951871.255282
baz one -0.3413450.790919
two -1.297284-1.285871
stacked.unstack().unstack()
A B second one two one two first bar -0.484529-0.2951871.0713711.255282
baz -0.341345-1.2972840.790919-1.285871
stack()就是把二維表轉化成一維表 unstack() 則為stack的逆函數,即把一維表轉化成二維表的過程 stacked.unstack(1)
second one two first bar A -0.484529-0.295187
B 1.0713711.255282
baz A -0.341345-1.297284
B 0.790919-1.285871
stacked.unstack(2)
A B first second bar one -0.4845291.071371
two -0.2951871.255282
baz one -0.3413450.790919
two -1.297284-1.285871
stacked.unstack(0)
數據透視表 df = pd.DataFrame({
"A":["one","one","two","three"] * 3,
"B":["A","B","C"] * 4,
"C":["foo","foo","foo","bar","bar","bar"]*2,
"D": np.random.randn(12),
"E": np.random.randn(12),
})
df
A B C D E 0 oneAfoo0.0138460.444128
1 oneBfoo1.785051-0.880777
2 twoCfoo2.020651-1.403231
3 threeAbar-0.623111-0.053250
4 oneBbar-0.022848-0.821333
5 oneCbar-0.9627510.691853
6 twoAfoo0.991734-1.796295
7 threeBfoo-0.326107-1.437360
8 oneCfoo1.634899-0.036184
9 oneAbar-0.0991101.219143
10 twoBbar0.1400442.462987
11 threeCbar1.043458-0.416262
pd.pivot_table(df,values="D",index=["A","B"],columns=["C"])
C bar foo A B one A -0.0991100.013846
B -0.0228481.785051
C -0.9627511.634899
three A -0.623111NaN
B NaN-0.326107
C 1.043458NaN
two A NaN0.991734
B 0.140044NaN
C NaN2.020651
時間序列 pandas具有簡單、強大、高效的功能,用於在頻率轉換期間執行重采樣操作(例如,將秒數據轉換為5分鐘數據)。這在但不限於金融應用程序中極為常見 rng = pd.date_range("6/8/2022",periods=100,freq="S")
rng
DatetimeIndex(['2022-06-08 00:00:00', '2022-06-08 00:00:01',
'2022-06-08 00:00:02', '2022-06-08 00:00:03',
'2022-06-08 00:00:04', '2022-06-08 00:00:05',
'2022-06-08 00:00:06', '2022-06-08 00:00:07',
'2022-06-08 00:00:08', '2022-06-08 00:00:09',
'2022-06-08 00:00:10', '2022-06-08 00:00:11',
'2022-06-08 00:00:12', '2022-06-08 00:00:13',
'2022-06-08 00:00:14', '2022-06-08 00:00:15',
'2022-06-08 00:00:16', '2022-06-08 00:00:17',
'2022-06-08 00:00:18', '2022-06-08 00:00:19',
'2022-06-08 00:00:20', '2022-06-08 00:00:21',
'2022-06-08 00:00:22', '2022-06-08 00:00:23',
'2022-06-08 00:00:24', '2022-06-08 00:00:25',
'2022-06-08 00:00:26', '2022-06-08 00:00:27',
'2022-06-08 00:00:28', '2022-06-08 00:00:29',
'2022-06-08 00:00:30', '2022-06-08 00:00:31',
'2022-06-08 00:00:32', '2022-06-08 00:00:33',
'2022-06-08 00:00:34', '2022-06-08 00:00:35',
'2022-06-08 00:00:36', '2022-06-08 00:00:37',
'2022-06-08 00:00:38', '2022-06-08 00:00:39',
'2022-06-08 00:00:40', '2022-06-08 00:00:41',
'2022-06-08 00:00:42', '2022-06-08 00:00:43',
'2022-06-08 00:00:44', '2022-06-08 00:00:45',
'2022-06-08 00:00:46', '2022-06-08 00:00:47',
'2022-06-08 00:00:48', '2022-06-08 00:00:49',
'2022-06-08 00:00:50', '2022-06-08 00:00:51',
'2022-06-08 00:00:52', '2022-06-08 00:00:53',
'2022-06-08 00:00:54', '2022-06-08 00:00:55',
'2022-06-08 00:00:56', '2022-06-08 00:00:57',
'2022-06-08 00:00:58', '2022-06-08 00:00:59',
'2022-06-08 00:01:00', '2022-06-08 00:01:01',
'2022-06-08 00:01:02', '2022-06-08 00:01:03',
'2022-06-08 00:01:04', '2022-06-08 00:01:05',
'2022-06-08 00:01:06', '2022-06-08 00:01:07',
'2022-06-08 00:01:08', '2022-06-08 00:01:09',
'2022-06-08 00:01:10', '2022-06-08 00:01:11',
'2022-06-08 00:01:12', '2022-06-08 00:01:13',
'2022-06-08 00:01:14', '2022-06-08 00:01:15',
'2022-06-08 00:01:16', '2022-06-08 00:01:17',
'2022-06-08 00:01:18', '2022-06-08 00:01:19',
'2022-06-08 00:01:20', '2022-06-08 00:01:21',
'2022-06-08 00:01:22', '2022-06-08 00:01:23',
'2022-06-08 00:01:24', '2022-06-08 00:01:25',
'2022-06-08 00:01:26', '2022-06-08 00:01:27',
'2022-06-08 00:01:28', '2022-06-08 00:01:29',
'2022-06-08 00:01:30', '2022-06-08 00:01:31',
'2022-06-08 00:01:32', '2022-06-08 00:01:33',
'2022-06-08 00:01:34', '2022-06-08 00:01:35',
'2022-06-08 00:01:36', '2022-06-08 00:01:37',
'2022-06-08 00:01:38', '2022-06-08 00:01:39'],
dtype='datetime64[ns]', freq='S')
ts = pd.Series(np.random.randint(0,500,len(rng)),index=rng)
ts
2022-06-08 00:00:00 355
2022-06-08 00:00:01 109
2022-06-08 00:00:02 457
2022-06-08 00:00:03 481
2022-06-08 00:00:04 220
...
2022-06-08 00:01:35 104
2022-06-08 00:01:36 461
2022-06-08 00:01:37 176
2022-06-08 00:01:38 37
2022-06-08 00:01:39 26
Freq: S, Length: 100, dtype: int32
# 重采樣(Resampling)指的是把時間序列的頻度變為另一個頻度的過程
ts.resample("5Min").sum()
2022-06-08 24384
Freq: 5T, dtype: int32
pd.date_range(
start=None,#開始時間
end=None,#截止時間
periods=None,#總長度
freq=None,#時間間隔
tz=None,#時區
normalize=False,#是否標准化到midnight
name=None,#date名稱
closed=None,#首尾是否在內
**kwargs,
)
# freq為D表示每日日歷,為S表示每秒
rng = pd.date_range("6/8/2022 14:30",periods=3,freq="D")
rng
DatetimeIndex(['2022-06-08 14:30:00', '2022-06-09 14:30:00',
'2022-06-10 14:30:00'],
dtype='datetime64[ns]', freq='D')
pd.date_range("6/8/2022 14:30",periods=6,freq="D")
DatetimeIndex(['2022-06-08 14:30:00', '2022-06-09 14:30:00',
'2022-06-10 14:30:00', '2022-06-11 14:30:00',
'2022-06-12 14:30:00', '2022-06-13 14:30:00'],
dtype='datetime64[ns]', freq='D')
# freq="T" 表示分鐘
pd.date_range("6/8/2022 14:30",periods=6,freq="T")
DatetimeIndex(['2022-06-08 14:30:00', '2022-06-08 14:31:00',
'2022-06-08 14:32:00', '2022-06-08 14:33:00',
'2022-06-08 14:34:00', '2022-06-08 14:35:00'],
dtype='datetime64[ns]', freq='T')
pd.date_range("6/8/2022 14:30",periods=6,freq="D")
DatetimeIndex(['2022-06-08 14:30:00', '2022-06-09 14:30:00',
'2022-06-10 14:30:00', '2022-06-11 14:30:00',
'2022-06-12 14:30:00', '2022-06-13 14:30:00'],
dtype='datetime64[ns]', freq='D')
rng
DatetimeIndex(['2022-06-08 14:30:00', '2022-06-09 14:30:00',
'2022-06-10 14:30:00', '2022-06-11 14:30:00',
'2022-06-12 14:30:00', '2022-06-13 14:30:00'],
dtype='datetime64[ns]', freq='D')
ts = pd.Series(np.random.randn(len(rng)),rng)
ts
2022-06-08 14:30:00 -1.849361
2022-06-09 14:30:00 1.354631
2022-06-10 14:30:00 0.412876
2022-06-11 14:30:00 1.465844
2022-06-12 14:30:00 0.665059
2022-06-13 14:30:00 2.036140
Freq: D, dtype: float64
# UTC:協調世界時,全世界唯一的統一時間;
ts_utc = ts.tz_localize("UTC")
ts_utc
2022-06-08 14:30:00+00:00 -1.849361
2022-06-09 14:30:00+00:00 1.354631
2022-06-10 14:30:00+00:00 0.412876
2022-06-11 14:30:00+00:00 1.465844
2022-06-12 14:30:00+00:00 0.665059
2022-06-13 14:30:00+00:00 2.036140
Freq: D, dtype: float64
ts_utc.tz_convert("US/Eastern")
2022-06-08 10:30:00-04:00 -1.849361
2022-06-09 10:30:00-04:00 1.354631
2022-06-10 10:30:00-04:00 0.412876
2022-06-11 10:30:00-04:00 1.465844
2022-06-12 10:30:00-04:00 0.665059
2022-06-13 10:30:00-04:00 2.036140
Freq: D, dtype: float64
rng = pd.date_range("6/8/2022",periods=5,freq="M")
rng
DatetimeIndex(['2022-06-30', '2022-07-31', '2022-08-31', '2022-09-30',
'2022-10-31'],
dtype='datetime64[ns]', freq='M')
pd.date_range("6/8/2022",periods=8,freq="M")
DatetimeIndex(['2022-06-30', '2022-07-31', '2022-08-31', '2022-09-30',
'2022-10-31', '2022-11-30', '2022-12-31', '2023-01-31'],
dtype='datetime64[ns]', freq='M')
ts = pd.Series(np.random.randn(len(rng)),index=rng)
ts
2022-06-30 1.211478
2022-07-31 0.086780
2022-08-31 -0.373740
2022-09-30 -1.602854
2022-10-31 0.428028
Freq: M, dtype: float64
# 操作 to_period 函數允許將日期轉換為特定的時間間隔。使用該方法可以獲取具有許多不同間隔或周期的日期,例如日、周、月、季度等。
ps = ts.to_period()
ps
2022-06 1.211478
2022-07 0.086780
2022-08 -0.373740
2022-09 -1.602854
2022-10 0.428028
Freq: M, dtype: float64
# Period.to_timestamp()函數以指定頻率(在周期的指定結束時間)在目標頻率處返回周期的時間戳表示。
ps.to_timestamp()
2022-06-01 1.211478
2022-07-01 0.086780
2022-08-01 -0.373740
2022-09-01 -1.602854
2022-10-01 0.428028
Freq: MS, dtype: float64
# 可以通過pandas的period_range函數產生時間序列作為series的index。
# 季度為單位 freq="Q-NOV"
prng = pd.period_range("2021Q1","2022Q4",freq="Q-NOV")
prng
PeriodIndex(['2021Q1', '2021Q2', '2021Q3', '2021Q4', '2022Q1', '2022Q2',
'2022Q3', '2022Q4'],
dtype='period[Q-NOV]')
ts = pd.Series(np.random.randn(len(prng)),prng)
ts
2021Q1 -0.506796
2021Q2 -0.481430
2021Q3 -0.078390
2021Q4 -0.080919
2022Q1 0.057916
2022Q2 -0.151808
2022Q3 -0.936490
2022Q4 -0.320068
Freq: Q-NOV, dtype: float64
ts.index = (prng.asfreq("M","e") + 1).asfreq("H","s") + 9
ts.index
PeriodIndex(['2021-03-01 09:00', '2021-06-01 09:00', '2021-09-01 09:00',
'2021-12-01 09:00', '2022-03-01 09:00', '2022-06-01 09:00',
'2022-09-01 09:00', '2022-12-01 09:00'],
dtype='period[H]')
ts.head()
2021-03-01 09:00 -0.506796
2021-06-01 09:00 -0.481430
2021-09-01 09:00 -0.078390
2021-12-01 09:00 -0.080919
2022-03-01 09:00 0.057916
Freq: H, dtype: float64
分類 pandas可以在DataFrame.如需完整文檔 df = pd.DataFrame(
{
"id":[1,2,3,4,5,6],"raw_grade":["a","b","b","a","a","e"]}
)
df
id raw_grade 0 1a
1 2b
2 3b
3 4a
4 5a
5 6e
df["grade"] = df["raw_grade"].astype("category")
df["grade"]
0 a
1 b
2 b
3 a
4 a
5 e
Name: grade, dtype: category
Categories (3, object): ['a', 'b', 'e']
df["grade"].cat.categories = ["very good","good","very bad"]
df
id raw_grade grade 0 1avery good
1 2bgood
2 3bgood
3 4avery good
4 5avery good
5 6every bad
重新排序類別並同時添加缺失的類別(默認情況下Series.cat()返回一個新的方法):Series df["grade"] = df["grade"].cat.set_categories(
["very bad","bad","medium","good","very good"]
)
df["grade"]
0 very good
1 good
2 good
3 very good
4 very good
5 very bad
Name: grade, dtype: category
Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good']
df
id raw_grade grade 0 1avery good
1 2bgood
2 3bgood
3 4avery good
4 5avery good
5 6every bad
df.sort_values(by="grade")
id raw_grade grade 5 6every bad
1 2bgood
2 3bgood
0 1avery good
3 4avery good
4 5avery good
df.groupby("grade").size()
grade
very bad 1
bad 0
medium 0
good 2
very good 3
dtype: int64
繪圖 我們使用標准約定來引用 matplotlib API: import matplotlib.pyplot as plt
plt.close("all")
ts = pd.Series(np.random.randn(1000),index=pd.date_range("6/8/2022",periods=1000))
ts = ts.cumsum()
ts
2022-06-08 -0.416538
2022-06-09 -1.186893
2022-06-10 -0.974144
2022-06-11 -0.929173
2022-06-12 0.371832
...
2025-02-27 14.514577
2025-02-28 15.186525
2025-03-01 15.595083
2025-03-02 16.554780
2025-03-03 17.165945
Freq: D, Length: 1000, dtype: float64
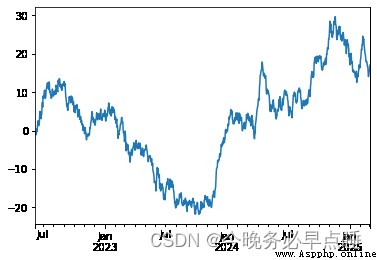
ts.plot()
<AxesSubplot:>
如果在Jupyter Notebook 下運行,繪圖將出現在plot().否則使用matplotlib.pyplot.show顯示它或matplotlib.pyplot.savefig將其寫入文件。 plt
<module 'matplotlib.pyplot' from 'D:\\software\\anaconda\\lib\\site-packages\\matplotlib\\pyplot.py'>
plt.show()
在DataFrame上,該plot()方法可以方便地繪制帶有標簽的所有列 ts.index
DatetimeIndex(['2022-06-08', '2022-06-09', '2022-06-10', '2022-06-11',
'2022-06-12', '2022-06-13', '2022-06-14', '2022-06-15',
'2022-06-16', '2022-06-17',
...
'2025-02-22', '2025-02-23', '2025-02-24', '2025-02-25',
'2025-02-26', '2025-02-27', '2025-02-28', '2025-03-01',
'2025-03-02', '2025-03-03'],
dtype='datetime64[ns]', length=1000, freq='D')
df = pd.DataFrame(
np.random.randn(1000,4),index=ts.index,columns=["A","B","C","D"]
)
df
A B C D 2022-06-08 -1.411527-0.124331-0.7481940.795625
2022-06-09 0.3273561.127876-0.176681-0.140429
2022-06-10 -0.5460870.0566210.8796180.111533
2022-06-11 -0.723865-1.197658-0.1344880.762858
2022-06-12 -0.584152-0.205798-0.4571090.613583
... ............
2025-02-27 0.9526180.809016-1.2567700.544052
2025-02-28 -0.325551-1.333431-2.5934790.753844
2025-03-01 0.0723500.9502981.1128010.644935
2025-03-02 -0.149229-0.704682-1.6479900.780895
2025-03-03 0.9447890.6803620.892620-1.074460
1000 rows × 4 columns
# df.cumsum() 按列相加 上一個位置加下一個位置
df.cumsum()
A B C D 2022-06-08 -1.411527-0.124331-0.7481940.795625
2022-06-09 -1.0841711.003545-0.9248750.655196
2022-06-10 -1.6302591.060166-0.0452570.766730
2022-06-11 -2.354124-0.137492-0.1797451.529588
2022-06-12 -2.938276-0.343290-0.6368542.143171
... ............
2025-02-27 5.42532533.51382433.9726940.586048
2025-02-28 5.09977532.18039431.3792151.339892
2025-03-01 5.17212433.13069232.4920161.984828
2025-03-02 5.02289532.42600930.8440262.765723
2025-03-03 5.96768333.10637231.7366471.691263
1000 rows × 4 columns
plt.figure()
<Figure size 432x288 with 0 Axes>
<Figure size 432x288 with 0 Axes>
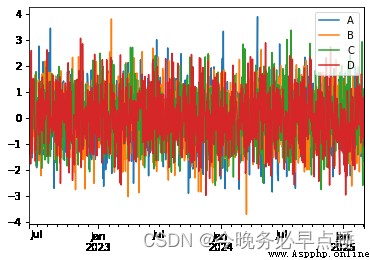
df.plot()
<AxesSubplot:>
plt.legend(loc='best')
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
<matplotlib.legend.Legend at 0x265646b7d90>
輸入/輸出數據 CSV df.to_csv("foo.csv")
pd.read_csv("foo.csv")
Unnamed: 0 A B C D 0 2022-06-08-1.411527-0.124331-0.7481940.795625
1 2022-06-090.3273561.127876-0.176681-0.140429
2 2022-06-10-0.5460870.0566210.8796180.111533
3 2022-06-11-0.723865-1.197658-0.1344880.762858
4 2022-06-12-0.584152-0.205798-0.4571090.613583
... ...............
995 2025-02-270.9526180.809016-1.2567700.544052
996 2025-02-28-0.325551-1.333431-2.5934790.753844
997 2025-03-010.0723500.9502981.1128010.644935
998 2025-03-02-0.149229-0.704682-1.6479900.780895
999 2025-03-030.9447890.6803620.892620-1.074460
1000 rows × 5 columns
HDF5 df.to_hdf("foo.h5","df")
pd
<module 'pandas' from 'D:\\software\\anaconda\\lib\\site-packages\\pandas\\__init__.py'>
pd.read_hdf("foo.h5","df")
A B C D 2022-06-08 -1.411527-0.124331-0.7481940.795625
2022-06-09 0.3273561.127876-0.176681-0.140429
2022-06-10 -0.5460870.0566210.8796180.111533
2022-06-11 -0.723865-1.197658-0.1344880.762858
2022-06-12 -0.584152-0.205798-0.4571090.613583
... ............
2025-02-27 0.9526180.809016-1.2567700.544052
2025-02-28 -0.325551-1.333431-2.5934790.753844
2025-03-01 0.0723500.9502981.1128010.644935
2025-03-02 -0.149229-0.704682-1.6479900.780895
2025-03-03 0.9447890.6803620.892620-1.074460
1000 rows × 4 columns
Excel 讀取和寫入MS Excel # excel_writer : ExcelWriter目標路徑
# sheet_name :excel表名命名
# index:默認為True,顯示index,當index=False 則不顯示行索引(名字)
df.to_excel("foo.xlsx",sheet_name="Sheet1")
pd.read_excel("foo.xlsx","Sheet1",index_col=None,na_values=['NA'])
Unnamed: 0 A B C D 0 2022-06-08-1.411527-0.124331-0.7481940.795625
1 2022-06-090.3273561.127876-0.176681-0.140429
2 2022-06-10-0.5460870.0566210.8796180.111533
3 2022-06-11-0.723865-1.197658-0.1344880.762858
4 2022-06-12-0.584152-0.205798-0.4571090.613583
... ...............
995 2025-02-270.9526180.809016-1.2567700.544052
996 2025-02-28-0.325551-1.333431-2.5934790.753844
997 2025-03-010.0723500.9502981.1128010.644935
998 2025-03-02-0.149229-0.704682-1.6479900.780895
999 2025-03-030.9447890.6803620.892620-1.074460
1000 rows × 5 columns