我從2021年6月13號寫下第一篇Python的系列專欄算起,陸續更新了二十七篇Python系列文章。在此感謝讀者朋友們的支持和閱讀,特別感謝一鍵三連的小伙伴。
本專欄起名【Python從入門到精通】,主要分為基礎知識和項目實戰兩個部分,目前基礎知識部分已經完全介紹完畢。下一階段就是寫Python項目實戰以及爬蟲相關的知識點。
為了對前期學習的Python基礎知識做一個總結歸納,以幫助讀者朋友們更好的學習下一部分的實戰知識點,故在此我寫下此文,共勉,同進。
同時為了方便大家交流學習,我這邊還建立了一個Python的學習群。群裡都是一群熱愛學習的小伙伴,不乏一些牛逼的大佬。大佬帶飛,我相信進入群裡的小伙伴一定會走的更快,飛的更高。 歡迎掃碼進群。
下面就通過一個思維導圖,展示本專欄Python基礎知識部分的總覽圖。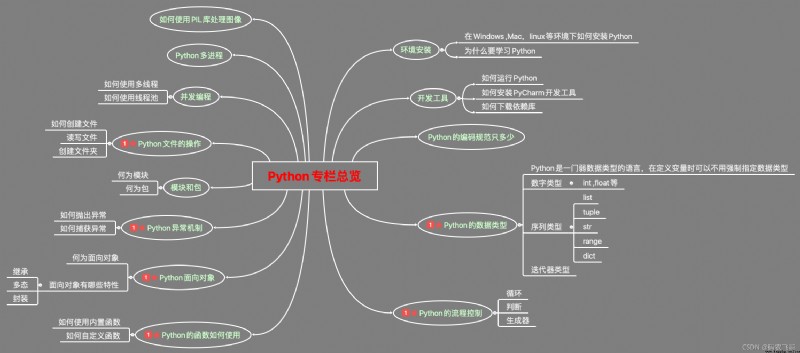
本專欄從零基礎出發,從環境的搭建到高級知識點的學習,一步步走來,相信各位讀者朋友們早已掌握相關的知識點。接下來就做一個詳細的回顧。
Python是一門開源免費的,通用型的腳本編程語言。它需要在運行時將代碼一行行解析成CPU能識別的機器碼。它是一門解析型的語言,何為解析型語言呢?就是在運行時通過解析器將源代碼一行行解析成機器碼。而像C語言,C++等則是編譯型的語言,即通過編譯器將所有的源代碼一次性編譯成二進制指令,生成一個可執行的程序。解析型語言相對於編譯型語言的好處就是天然具有跨平台的特點,一次編碼,到處運行。
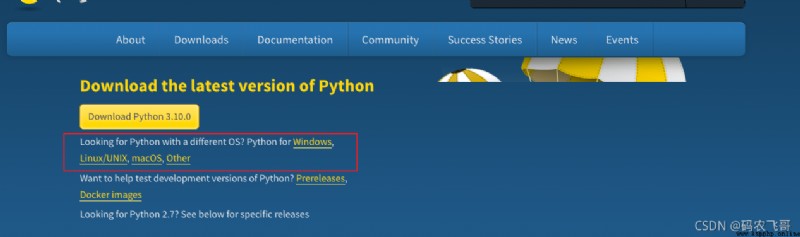
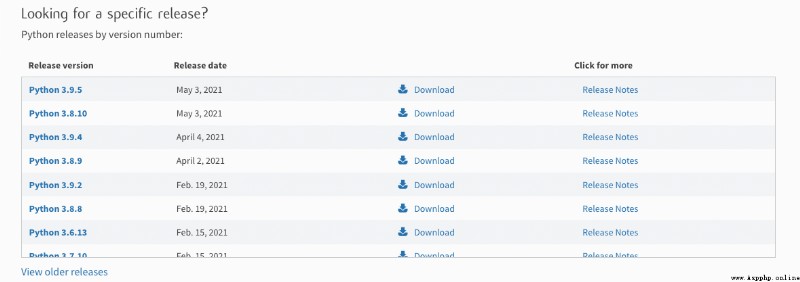
python3 驗證安裝的結果,如果出現如下結果就表明安裝Python編譯器安裝成功了。
工欲善其事必先利其器,在實際開發中我們都是通過IDE(集成開發環境)來進行編碼,為啥要使用IDE呢?這是因為IDE集成了語言編輯器,自動建立工具,除錯器等等工具可以極大方便我們快速的進行開發。打個比方 我們可以將集成開發環境想象成一個台式機。雖然只需要主機就能運行起來,但是,還是需要顯示器,鍵盤等才能用的爽。
PyCharm就是這樣一款讓人用的很爽的IDE開發工具。下面就簡單介紹一下它的安裝過程
點擊鏈接 https://www.jetbrains.com/pycharm/download/
進入下來頁面,PyCharm 有專業版和社區版。其中,專業版需要購買才能使用,而社區版是免費的。社區版對於日常的Python開發完全夠用了。所以我們選擇PyCharm的社區版進行下載安裝。點擊如下圖所示的按鈕進行安裝包的下載。
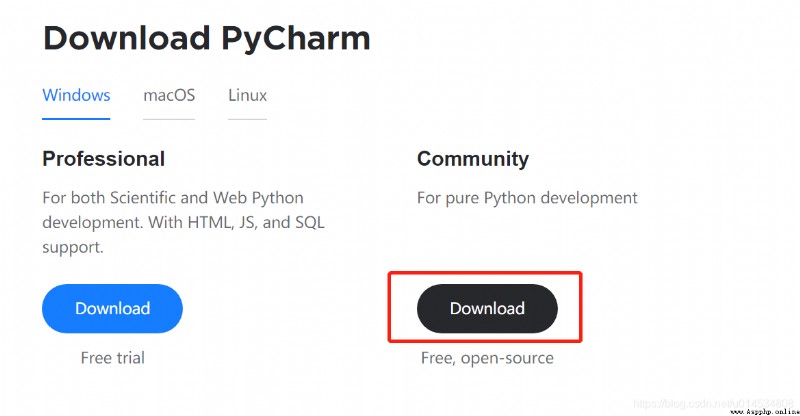
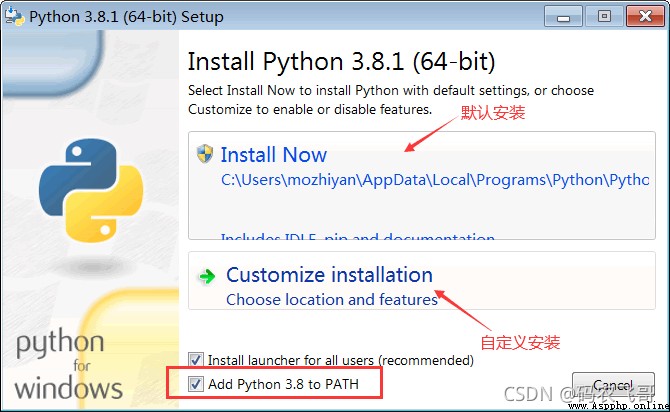
安裝包下載好之後,我們雙擊安裝包即可進行安裝,安裝過程比較簡單,基本只需要安裝默認的設置每一步點擊Next按鈕即可,不過當出現下圖的窗口時需要設置一下。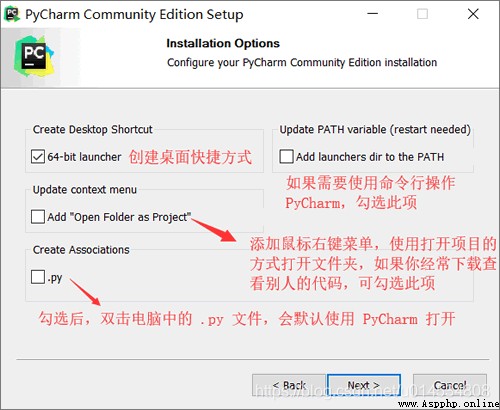
設置好之後點擊 Next 進入下一步的安裝,知道所有的安裝都完成。
這裡使用只需要注意一點,就是設置解釋器,默認的話在Project Interpreter的選擇框中是提示的是 No interpreter,即沒有選中解釋器,所以,我們需要手動添加。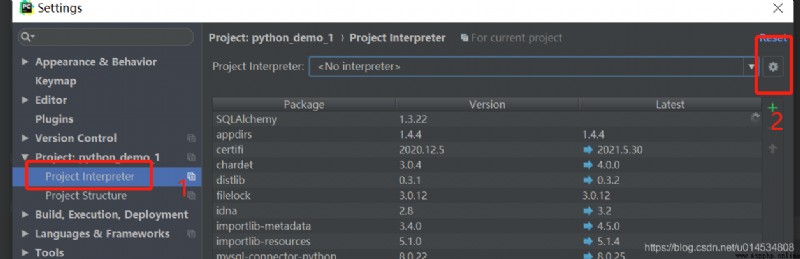
所以需要點擊設置按鈕設置解釋器,這裡選擇 Add Local 設置本地的解釋器。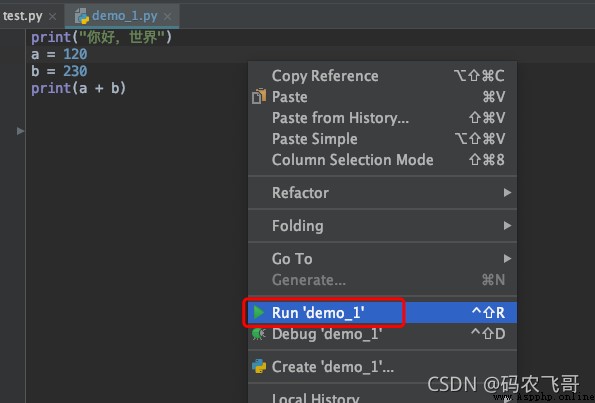
打開解釋器的設置頁面之後,默認選中的是Virtualenv Environment 這個tab頁,
這裡Location是用來設置項目的虛擬環境,具體可以參考pycharm的使用小結,設置虛擬環境,更換鏡像源
Base interpreter 用來設置解釋器的路徑。
至此,開發Python的腳手架已經弄好,接下來就是編碼了。
如下創建了一個名為demo_1.py的文件,然後在文件中寫入了如下幾行代碼
print("你好,世界")
a = 120
b = 230
print(a + b)
運行這些代碼只需要簡單的右鍵選中 Run ‘demo_1’ 或者 Debug ‘demo_1’ ,這兩者的區別是Run demo_1是以普通模式運行代碼,而 Debug ‘demo_1’ 是以調試模式運行代碼。
運行結果就是:
詳細內容可以查看【Python從入門到精通】(二)怎麼運行Python呢?有哪些好的開發工具
首先介紹的是Python的注釋,Python的注釋分為兩種:單行注釋和多行注釋。
單行注釋
Python使用 # 號作為單行注釋的符號,其語法格式為:#注釋內容 從#號開始直到這行結束為止的所有內容都是注釋。例如:
多行注釋
多行注釋指一次注釋程序中多行的內容(包含一行) ,Python使用三個連續的 單引號’’’ 或者三個連續的雙引號"“” 注釋多行內容。其語法格式是如下:
‘’’
三個連續的單引號的多行注釋
注釋多行內容
‘’’
或者
"""
三個連續的雙引號的多行注釋
注釋多行內容
"""
多行注釋通常用來為Python文件、模塊、類或者函數等添加版權或者功能描述信息(即文檔注釋)
不同於其他編程語言(如Java,或者C)采用大括號{}分割代碼塊,Python采用代碼縮進和冒號 : 來區分代碼塊之間的層次。如下面的代碼所示:
a = -100
if a >= 0:
print("輸出正數" + str(a))
print('測試')
else:
print("輸出負數" + str(a))
其中第一行代碼a = -100和第二行代碼if a >= 0:是在同一作用域(也就是作用范圍相同),所以這兩行代碼並排。而第三行代碼print("輸出正數" + str(a)) 的作用范圍是在第二行代碼裡面,所以需要縮進。第五行代碼也是同理。第二行代碼通過冒號和第三行代碼的縮進來區分這兩個代碼塊。
Python的縮進量可以使用空格或者Tab鍵來實現縮進,通常情況下都是采用4個空格長度作為一個縮進量的。
這裡需要注意的是同一個作用域的代碼的縮進量要相同,不然會導致IndentationError異常錯誤,提示縮進量不對,如下面代碼所示:第二行代碼print("輸出正數" + str(a)) 縮進了4個空格,而第三行代碼print('測試')只縮進了2個空格。
if a >= 0:
print("輸出正數" + str(a))
print('測試')
在Python中,對於類定義,函數定義,流程控制語句就像前面的if a>=0:,異常處理語句等,行尾的冒號和下一行縮進,表示下一個代碼塊的開始,而縮進的結束則表示此代碼的結束。
詳細內容可以查看【Python從入門到精通】(三)Python的編碼規范,標識符知多少?
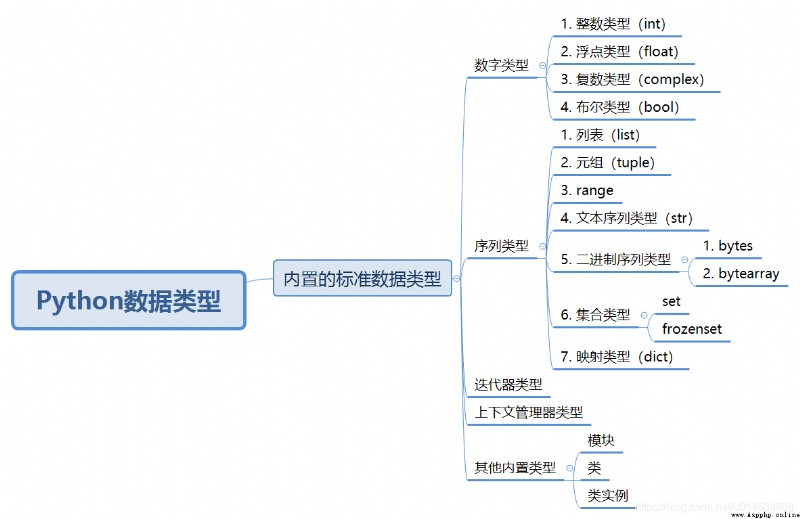
Python3中的整數是不分類型,也就是說沒有長整數類型(Long)或者短整數類型(short)之分,它的取值范圍是是無限的,即不管多大或者多小的數字,Python都能輕松的應對。如下就是兩個極大或者極小的整數。
>>> 100000-0000000000000000000000000000000000000000
1000000000000000000000000000000000000000000000
>>> print(-1000000000000000000000000000000000000000000000)
-1000000000000000000000000000000000000000000000
可以看出再大或者再小的數字都不會出現溢出的情況,這說明了Python對整數的處理能力非常強。
Python中可以用多種進制的來表示整數。
十進制形式
我們平時常見的整數就是十進制形式,它由 0~9 共十個數字排列組合而成。
注意,使用十進制形式的整數不能以 0 作為開頭,除非這個數值本身就是 0。
二進制形式
由 0 和 1 兩個數字組成,書寫時以0b或0B開頭。例如,1001對應十進制數是 9。
八進制形式
八進制整數由 0~7 共八個數字組成,以0o或0O開頭。注意,第一個符號是數字 0,第二個符號是大寫或小寫的字母 O。
十六進制形式
由 0~9 十個數字以及 A~F(或 a~f)六個字母組成,書寫時以0x或0X開頭。
a=0b1001
print(‘a=’,a)
b=0o207
print(‘b=’,b)
c=0x45
print(‘c=’,c)
運行結果是:
a= 9
b= 135
c= 69
Python 3.x允許使用下劃線_作為數字(包括整數和小數)的分隔符,通常每隔三個數字添加一個下劃線,比如:click = 1_301_547
在編程語言中,小數通常以浮點數的形式存儲,浮點數和定點數是相對的;小數在存儲過程中如果小數點發生移動,就稱為浮點數;如果小數點不動,就稱為定點數。
Python中的小數有兩種書寫形式:
十進制形式
這就是我們經常看到的小數形式,比如101.1;234.5;0.23
指數形式
Python小數點指數形式的寫法為:aEn或aen
a為尾數部分,是一個十進制,n為指數部分,是一個十進制,E或者e是固定的字符,用於分割尾數部分和指數部分,真的表達式是 a×10n。
舉個栗子:
2.3E5=2.3x10的5次方
依然還舉個栗子:
x=10.01
print(‘x=’,x)
y=-0.031
print(‘y=’,y)
z=2.3E10
print(‘z=’,z)
w=-0.00000001
print(‘w=’,w)
運行結果是:
x= 10.01
y= -0.031
z= 23000000000.0
w= -1e-08
布爾類型用來表示真(對)或假(錯),比如常見的3>2 比較算式,這個是正確的,Python中使用True來代表;再比如2>3 比較算式,這個是錯誤的,用False來代表。
print(3>2)
print(2>3)
print('True==1的結果是:',True==1)
print('False==0的結果是:',False==0)
運行結果是:
True
False
True==1的結果是: True
False==0的結果是: True
詳細內容可以查看【Python從入門到精通】(四)Python的內置數據類型有哪些呢?數字了解一下
序列(sequence)指的是一塊可存放多個元素的內存空間,這些元素按照一定的順序排列。每個元素都有自己的位置(索引),可以通過這些位置(索引)來找到指定的元素。如果將序列想象成一個酒店,那麼酒店裡的每個房間就相當於序列中的每個元素,房間的編號就相當於元素的索引,可以通過編號(索引)找到指定的房間(元素)。
了解完了序列的基本概念,那麼在Python中一共有哪些序列類型呢?如下圖所示: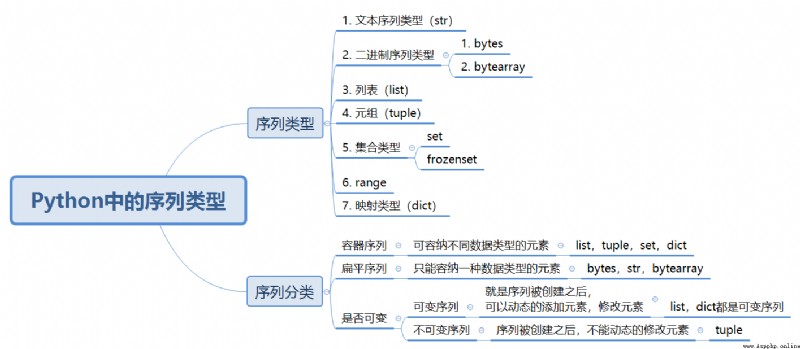
從圖中可以看出在Python中共有7種序列類型,分別是文本序列類型(str);二進制序列類型 bytes和bytearray;列表(list);元組(tuple);集合類型(set和frozenset);范圍類型(range)以及字典類型(dict)。
按照能存儲的元素可以將序列類型劃分為兩大類:分別是:容器序列和扁平序列
容器序列:即可容納不同數據類型的元素的序列;有 list;tuple;set;dict
舉個栗子:
list=['runoob',786,2.23,'john',70.2]
這裡的list保存的元素有多種數據類型,既有字符串,也有小數和整數。
扁平序列:即只能容納相同數據類型的元素的序列;有bytes;str;bytearray,以str為例,同一個str只能都存儲字符。
按照序列是否可變,又可分為可變序列和不可變序列。
這裡的可變的意思是:序列創建成功之後,還能不能進行修改操作,比如插入,修改等等,如果可以的話則是可變的序列,如果不可以的話則是不可變序列。
可變序列有列表( list);字典(dict)等,
不可變的序列有元祖(tuple),後面的文章會詳細的對這些數據類型做詳細介紹。
在介紹序列概念的時候,說到了序列中元素的索引,那麼什麼是序列的索引呢?其實就是位置的下標。 如果對C語言中的數組有所了解的話,我們知道數組的索引下標都是從0開始依次遞增的正數,即第一個元素的索引下標是0,第n個元素的索引下標是n-1。序列的索引也是同理,默認情況下都是從左向右記錄索引,索引值從0開始遞增,即第一個元素的元素的索引值是0,第n個元素的索引值是n-1。如下圖所示:
當然與C語言中數組不同的是,Python還支持索引值是負數,該類的索引是從右向左計數。換句話說,就是從最後一個元素開始計數,從索引值-1開始遞減,即第n個元素的索引值是-1,第1個元素的索引值是-n,如下圖所示:
切片操作是訪問序列元素的另一種方式,它可以訪問一定范圍內的元素,通過切片操作,可以生成一個新的序列。切片操作的語法格式是:
sname[start : end : step]
各個參數的含義分別是:
sname: 表示序列的名稱
start:表示切片的開始索引位置(包括該位置),此參數也可以不指定,不指定的情況下會默認為0,也就是從序列的開頭開始切片。
end:表示切片的結束索引位置(不包括該位置),如果不指定,則默認為序列的長度。
step: 表示步長,即在切片過程中,隔幾個存儲位置(包括當前位置)取一次元素,也就是說,如果step的值大於1,比如step為3時,則在切片取元素時,會隔2個位置去取下一個元素。
還是舉個栗子說明下吧:
str1=‘好好學習,天天向上’
print(str1[7])
print(str1[0:7])
print(str1[1:4:2])
print(str1[-1])
print(str1[-9:-2])
運行的結果是:
向
好好學習,天天
好習
上
好好學習,天天
Python支持類型相同的兩個序列使用"+"運算符做想加操作,它會將兩個序列進行連接,但是不會去除重復的元素,即只做一個簡單的拼接。
str='他叫小明'
str1='他很聰明'
print(str+str1)
運行結果是:他叫小明他很聰明
Python支持使用數字n乘以一個序列,其會生成一個新的序列,新序列的內容是原序列被重復了n次的結果。
str2='你好呀'
print(str2*3)
運行結果是:你好呀你好呀你好呀 ,原序列的內容重復了3次。
Python中可以使用in關鍵字檢查某個元素是否為序列中的成員,其語法格式為:
value in sequence
其中,value表示要檢查的元素,sequence表示指定的序列。
舉個栗子:查找天字是否在字符串str1中。
str1='好好學習,天天向上'
print('天' in str1)
運行結果是:True
*由若干個字符組成的集合就是一個字符串(str)**,Python中的字符串必須由雙引號""或者單引號’'包圍。其語法格式是:
"字符串內容"
'字符串內容'
如果字符串中包含了單引號需要做特殊處理。比如現在有這樣一個字符串str4='I'm a greate coder' 直接這樣寫有問題的。
處理的方式有兩種:
對引號進行轉義,通過轉義符號進行轉義即可:
str4=‘I’m a greate coder’
使用不同的引號包圍字符串
str4=“I’m a greate coder”
這裡外層用雙引號,包裹字符串裡的單引號。
通過+運算符
現有字符串好,,要求將字符串牛逼拼接到其後面,生成新的字符串好,牛逼
舉個例子:
str6 = '好,'
# 使用+ 運算符號
print('+運算符拼接的結果=',(str6 + '牛逼'))
運行結果是:
+運算符拼接的結果= 好,牛逼
切片操作是訪問字符串的另一種方式,它可以訪問一定范圍內的元素,通過切片操作,可以生成一個新的字符串。切片操作的語法格式是:
sname[start : end : step]
各個參數的含義分別是:
sname: 表示字符串的名稱
start:表示切片的開始索引位置(包括該位置),此參數也可以不指定,不指定的情況下會默認為0,也就是從序列的開頭開始切片。
end:表示切片的結束索引位置(不包括該位置),如果不指定,則默認為序列的長度。
step: 表示步長,即在切片過程中,隔幾個存儲位置(包括當前位置)取一次元素,也就是說,如果step的值大於1,比如step為3時,則在切片取元素時,會隔2個位置去取下一個元素。
還是舉個栗子說明下吧:
str1=‘好好學習,天天向上’
print(str1[7])
print(str1[0:7])
print(str1[1:4:2])
print(str1[-1])
print(str1[-9:-2])
運行的結果是:
向
好好學習,天天
好習
上
好好學習,天天
Python提供了split()方法用於分割字符串,split() 方法可以實現將一個字符串按照指定的分隔符切分成多個子串,這些子串會被保存到列表中(不包含分隔符),作為方法的返回值反饋回來。該方法的基本語法格式如下:
str.split(sep,maxsplit)
此方法中各部分參數的含義分別是:
str: 表示要進行分割的字符串
sep: 用於指定分隔符,可以包含多個字符,此參數默認為None,表示所有空字符,包括空格,換行符" “、制表符” "等
maxsplit: 可選參數,用於指定分割的次數,最後列表中子串的個數最多為maxsplit+1,如果不指定或者指定為-1,則表示分割次數沒有限制。
在 split 方法中,如果不指定 sep 參數,那麼也不能指定 maxsplit 參數。
舉例說明下:
str = ‘https://feige.blog.csdn.net/’
print(‘不指定分割次數’, str.split(‘.’))
print(‘指定分割次數為2次’,str.split(‘.’,2))
運行結果是:
不指定分割次數 ['https://feige', 'blog', 'csdn', 'net/']
指定分割次數為2次 ['https://feige', 'blog', 'csdn.net/']
合並字符串與split的作用剛剛相反,Python提供了join() 方法來將列表(或元組)中包含的多個字符串連接成一個字符串。其語法結構是:
newstr = str.join(iterable)
此方法各部分的參數含義是:
newstr: 表示合並後生成的新字符串
str: 用於指定合並時的分隔符
iterable: 做合並操作的源字符串數據,允許以列表、元組等形式提供。
依然是舉例說明:
list = [‘’, ‘好好學習’, ‘非常棒’]
print(‘通過.來拼接’, ‘.’.join(list))
print(‘通過-來拼接’, ‘-’.join(list))
運行結果是:
通過.來拼接 .好好學習.非常棒
通過-來拼接 -好好學習-非常棒
startswith()方法用於檢索字符串是否以指定字符串開頭,如果是返回True;反之返回False。其語法結構是:
str.startswith(sub[,start[,end]])
此方法各個參數的含義是:
str: 表示原字符串
sub: 要檢索的子串‘
start: 指定檢索開始的起始位置索引,如果不指定,則默認從頭開始檢索
end: 指定檢索的結束位置索引,如果不指定,則默認一直檢索到結束。
舉個栗子說明下:
str1 = ‘https://feige.blog.csdn.net/’
print(‘是否是以https開頭’, str1.startswith(‘https’))
print(‘是否是以feige開頭’, str1.startswith(‘feige’, 0, 20))
運行結果是:
是否是以https開頭 True
是否是以feige開頭 False
endswith()方法用於檢索字符串是否以指定字符串結尾,如果是則返回True,反之則返回False。其語法結構是:
str.endswith(sub[,start[,end]])
此方法各個參數的含義與startswith方法相同,再此就不在贅述了。
Python中提供了3種方法用於字符串大小寫轉換
title()方法用於將字符串中每個單詞的首字母轉成大寫,其他字母全部轉為小寫。轉換完成後,此方法會返回轉換得到的字符串。如果字符串中沒有需要被轉換的字符,此方法會將字符串原封不動地返回。其語法結構是str.title()
lower()用於將字符串中的所有大寫字母轉換成小寫字母,轉換完成後,該方法會返回新得到的子串。如果字符串中原本就都是小寫字母,則該方法會返回原字符串。 其語法結構是str.lower()
upper()用於將字符串中的所有小寫字母轉換成大寫字母,如果轉換成功,則返回新字符串;反之,則返回原字符串。其語法結構是:str.upper()。
舉例說明下吧:
str = ‘feiGe勇敢飛’
print(‘首字母大寫’, str.title())
print(‘全部小寫’, str.lower())
print(‘全部大寫’, str.upper())
運行結果是:
首字母大寫 Feige勇敢飛
全部小寫 feige勇敢飛
全部大寫 FEIGE勇敢飛
Python中提供了三種方法去除字符串中空格(刪除特殊字符)的3種方法,這裡的特殊字符,指的是指表符( )、回車符( ),換行符( )等。
strip(): 刪除字符串前後(左右兩側)的空格或特殊字符
lstrip():刪除字符串前面(左邊)的空格或特殊字符
rstrip():刪除字符串後面(右邊)的空格或特殊字符
Python的str是不可變的,因此這三個方法只是返回字符串前面或者後面空白被刪除之後的副本,並不會改變字符串本身
舉個例子說明下:
str = ’
勇敢飛 ’
print(‘去除前後空格(特殊字符串)’, str.strip())
print(‘去除左邊空格(特殊字符串)’, str.lstrip())
print(‘去除右邊空格(特殊字符串)’, str.rstrip())
運行結果是:
去除前後空格(特殊字符串) 勇敢飛
去除左邊空格(特殊字符串) 勇敢飛
去除右邊空格(特殊字符串)
勇敢飛
最早的字符串編碼是ASCll編碼,它僅僅對10個數字,26個大小寫英文字母以及一些特殊字符進行了編碼,ASCII碼最多只能表示256個字符,每個字符只需要占用1個字節。為了兼容各國的文字,相繼出現了GBK,GB2312,UTF-8編碼等,UTF-8是國際通用的編碼格式,它包含了全世界所有國家需要用到的字符,其規定英文字符占用1個字節,中文字符占用3個字節。
encode() 方法為字符串類型(str)提供的方法,用於將 str 類型轉換成 bytes 類型,這個過程也稱為“編碼”。其語法結構是:str.encode([encoding="utf-8"][,errors="strict"])
將bytes類型的二進制數據轉換成str類型。這個過程也稱為"解碼",其語法結構是:bytes.decode([encoding="utf-8"][,errors="strict"])
舉個例子說明下:
str = ‘加油’
bytes = str.encode()
print(‘編碼’, bytes)
print(‘解碼’, bytes.decode())
運行結果是:
編碼 b'??????é£???¥????21'
解碼 加油
默認的編碼格式是UTF-8,編碼和解碼的格式要相同,不然會解碼失敗。
在實際工作中我們經常要將一個數據對象序列化成字符串,也會將一個字符串反序列化成一個數據對象。Python自帶的序列化模塊是json模塊。
json.dumps() 方法是將Python對象轉成字符串
json.loads()方法是將已編碼的 JSON 字符串解碼為 Python 對象
舉個例子說明下:
import json
dict = {‘學號’: 1001, ‘name’: “張三”, ‘score’: [{‘語文’: 90, ‘數學’: 100}]}
str = json.dumps(dict,ensure_ascii=False)
print(‘序列化成字符串’, str, type(str))
dict2 = json.loads(str)
print(‘反序列化成對象’, dict2, type(dict2))
運行結果是:
序列化成字符串 {"name": "張三", "score": [{"數學": 100, "語文": 90}], "學號": 1001} <class 'str'>
反序列化成對象 {'name': '張三', 'score': [{'數學': 100, '語文': 90}], '學號': 1001} <class 'dict'>
詳細內容可以查看
【Python從入門到精通】(五)Python內置的數據類型-序列和字符串,沒有女友,不是保姆,只有拿來就能用的干貨
【Python從入門到精通】(九)Python中字符串的各種騷操作你已經爛熟於心了麼?【收藏下來就挺好的】
列表作為Python序列類型中的一種,其也是用於存儲多個元素的一塊內存空間,這些元素按照一定的順序排列。其數據結構是:
[element1, element2, element3, ..., elementn]
element1~elementn表示列表中的元素,元素的數據格式沒有限制,只要是Python支持的數據格式都可以往裡面方。同時因為列表支持自動擴容,所以它可變序列,即可以動態的修改列表,即可以修改,新增,刪除列表元素。看個爽圖吧!
首先介紹的是對列表的操作:包括列表的創建,列表的刪除等!其中創建一個列表的方式有兩種:
第一種方式:
通過[]包裹列表中的元素,每個元素之間通過逗號,分割。元素類型不限並且同一列表中的每個元素的類型可以不相同,但是不建議這樣做,因為如果每個元素的數據類型都不同的話則非常不方便對列表進行遍歷解析。所以建議一個列表只存同一種類型的元素。
list=[element1, element2, element3, ..., elementn]
例如:test_list = ['測試', 2, ['', '小偉'], (12, 23)]
PS: 空列表的定義是list=[]
第二種方式:
通過list(iterable)函數來創建列表,list函數是Python內置的函數。該函數傳入的參數必須是可迭代的序列,比如字符串,列表,元組等等,如果iterable傳入為空,則會創建一個空的列表。iterable不能只傳一個數字。
classmates1 = list('')
print(classmates1)
生成的列表是:['碼', '農', '飛', '哥']
向列表中新增元素的方法有四種,分別是:
第一種: 使用**+運算符將多個列表**連接起來。相當於在第一個列表的末尾添加上另一個列表。其語法格式是listname1+listname2
name_list = ['', '小偉', '小小偉']
name_list2 = ['python', 'java']
print(name_list + name_list2)
輸出結果是:['', '小偉', '小小偉', 'python', 'java'],可以看出將name_list2中的每個元素都添加到了name_list的末尾。
第二種:使用append()方法添加元素
append()方法用於向列表末尾添加元素,其語法格式是:listname.append(p_object)其中listname表示要添加元素的列表,p_object表示要添加到列表末尾的元素,可以是字符串,數字,也可以是一個序列。舉個栗子:
name_list.append('Adam')
print(name_list)
name_list.append(['test', 'test1'])
print(name_list)
運行結果是:
['', '小偉', '小小偉', 'Adam']
['', '小偉', '小小偉', 'Adam', ['test', 'test1']]
可以看出待添加的元素都成功的添加到了原列表的末尾處。並且當添加的元素是一個序列時,則會將該序列當成一個整體。
第三種:使用extend()方法
extend()方法跟append()方法的用法相同,同樣是向列表末尾添加元素。元素的類型只需要Python支持的數據類型即可。不過與append()方法不同的是,當添加的元素是序列時,extend()方法不會將列表當成一個整體,而是將每個元素添加到列表末尾。還是上面的那個例子:
name_list = ['', '小偉', '小小偉']
name_list.extend('Adam')
print(name_list)
name_list.extend(['test', 'test1'])
print(name_list)
運行結果是:
['', '小偉', '小小偉', 'A', 'd', 'a', 'm']
['', '小偉', '小小偉', 'A', 'd', 'a', 'm', 'test', 'test1']
從結果看出,當添加字符串時會將字符串中的每個字符作為一個元素添加到列表的末尾處,當添加的列表時會將列表中的每個元素添加到末尾處。
第四種:使用insert()方法
前面介紹的幾種插入方法,都只能向列表的末尾處插入元素,如果想在列表指定位置插入元素則無能為力。insert()方法正式用於處理這種問題而來的。其語法結構是listname.insert(index, p_object) 其中index表示指定位置的索引值,insert()會將p_object插入到listname列表第index個元素的位置。與append()方法相同的是,如果待添加的元素的是序列,則insert()會將該序列當成一個整體插入到列表的指定位置處。舉個栗子:
name_list = ['', '小偉', '小小偉']
name_list.insert(1, 'Jack')
print(name_list)
name_list.insert(2, ['test', 'test1'])
print(name_list)
運行結果是:
['', 'Jack', '小偉', '小小偉']
['', 'Jack', ['test', 'test1'], '小偉', '小小偉']
說完了列表中元素新增的方法,接著讓我們來看看修改列表中的元素相關的方法。修改列表元素的方法有兩種:
第一種:修改單個元素:
修改單個元素的方法就是對某個索引上的元素進行重新賦值。其語法結構是:listname[index]=newValue,就是將列表listname中索引值為index位置上的元素替換成newValue。
舉個栗子:
name_list = ['', '小偉', '小小偉']
name_list[1] = 'Sarah'
print(name_list)
運行結果:['', 'Sarah', '小小偉'] 從結果可以看出索引為1處的元素值被成功修改成了Sarch。
第二種:通過切片語法修改一組元素
通過切片語法可以修改一組元素,其語法結構是:listname[start:end:step],其中,listname表示列表名稱,start表示起始位置,end表示結束位置(不包括),step表示步長,如果不指定步長,Python就不要求新賦值的元素個數與原來的元素個數相同,這意味著,該操作可以為列表添加元素,也可以為列表刪除元素。舉個栗子:
name_list = ['', '小偉', '小小偉']
name_list[0:1] = ['飛哥', '牛逼']
print(name_list)
運行結果是:['飛哥', '牛逼', '小偉', '小小偉'] ,從結果可以看出將原列表中索引為0處的元素值已經被替換為飛哥,並且插入了牛逼 這個元素。
刪除列表中元素的方法共有四種。
第一種:根據索引值刪除元素的del關鍵字
根據索引值刪除元素的del關鍵字有兩種形式,一種是刪除單個元素,del listname[index],一種是根據切片刪除多個元素del listname[start : end],其中,listname表示列表名稱,start表示起始索引,end表示結束索引,del會刪除從索引start到end之間的元素,但是不包括end位置的元素。還是舉個栗子:
name_list = ['', '小偉', '小小偉', '超人']
name_list2 = name_list
print('原始的name_list={0}'.format(name_list))
print('原始的name_list2={0}'.format(name_list2))
# 刪除索引0到2之間的元素,即刪除索引0和索引1兩個位置的元素
del name_list[0:2]
print('使用del刪除元素後name_list={0}'.format(name_list))
print('使用del刪除元素後name_list2={0}'.format(name_list2))
del name_list
print('使用del刪除列表後name_list2={0}'.format(name_list2))
運行結果是:
原始的name_list=['', '小偉', '小小偉', '超人']
原始的name_list2=['', '小偉', '小小偉', '超人']
使用del刪除元素後name_list=['小小偉', '超人']
使用del刪除元素後name_list2=['小小偉', '超人']
使用del刪除列表後name_list2=['小小偉', '超人']
可以看出用del刪除列表元素時是真實的刪除了內存數據的,但是用del刪除列表時,則只是刪除了變量,name_list2所指向的內存數據還是存在的。
第二種:根據索引值刪除元素的pop()方法
根據索引值刪除元素的pop()方法的語法結構是:listname.pop(index),其中,listname表示列表名稱,index表示索引值,如果不寫index參數,默認會刪除列表中最後一個元素,類似於數據結構中的出棧操作。舉個例子:
name_list = ['', '小偉', '小小偉', '超人']
# 刪除list末尾的元素
name_list.pop()
print(name_list)
# 刪除指定位置的元素,用pop(i)方法,其中i是索引位置
name_list.pop(1)
print(name_list)
運行結果是:
['', '小偉', '小小偉']
['', '小小偉']
第三種:根據元素值進行刪除的remove()方法
根據元素值進行刪除的remove()方法,其語法結構是:listname.remove(object),其中listname表示列表的名稱,object表示待刪除的元素名稱。需要注意的是:如果元素在列表中不存在則會報ValueError的錯誤。舉個栗子:
name_list = ['', '小偉', '小小偉', '超人']
name_list.remove('小小偉')
print(name_list)
運行結果是:['', '小偉', '超人']。
第四種:刪除列表中的所有元素clear()方法
通過clear()方法可以刪除掉列表中的所有元素,其語法結構是:listname.clear(),其中listname表示列表的名稱。還是舉個栗子吧:
name_list = ['', '小偉', '小小偉', '超人']
name_list.clear()
print(name_list)
運行結果是:[],可以看出列表中元素被全部清空了。
說完了第五淺列表元素的刪除,略感疲憊。接著進行第六淺吧!看看列表中元素的查找以及訪問。看完這個之後,列表相關的內容也就告一段落了。
訪問列表中的元素有兩種方式,分別是通過索引定位訪問單個元素,通過切片訪問多個元素。
第一種:通過索引定位訪問單個元素,其語法結構是:listname[index] ,其中listname表示列表的名字,index表示要查找元素的索引值。
第二種:通過切片的方式訪問多個元素,其語法結構是:listname[start:end:step]。其中,listname表示列表的名字,start表示開始索引,end表示結束索引(不包括end位置),step表示步長。同樣是舉個栗子:
list2 = ['', '小偉', '小小偉',123]
print(list2[0]) # 輸出列表的第一個元素
print(list2[1:3]) # 輸出第二個至第三個元素
print(list2[2:]) # 輸出從第三個開始至列表末尾的所有元素
運行結果是:
['小偉', '小小偉']
['小小偉', 123]
indext()方法用來查找某個元素在列表中出現的位置(也就是索引),如果該元素在列表中不存在,則會報ValueError錯誤。其語法結構是:listname.index(object, start, end) 其中listname表示列表的名字,object表示要查找的元素,start表示起始索引,end表示結束索引(不包括)。
name_list = ['', '小偉', '小小偉', '超人']
print(name_list.index('小偉', 0, 2))
運行結果是:1
前面介紹了使用+運算符,使用append方法,使用extend方法都可以新增元素,那麼他們到底有啥區別呢?還是舉例說明吧;
name_list = ['', '小偉', '小小偉', '超人']
name_list2 = ['牛魔王']
name_list3 = name_list + name_list2
print("原始的name_list的值={0};內存地址={1}".format(name_list, id(name_list)))
print("使用+運算符後name_list3的值={0};內存地址={1}".format(name_list3, id(name_list3)))
print("使用+運算符後name_list的值{0};內存地址={1}".format(name_list, id(name_list)))
name_list4 = name_list.append('牛魔王')
print('使用append方法後name_list4的值={0};內存地址={1}'.format(name_list4, id(name_list4)))
print("使用append方法後name_list的值{0};內存地址={1}".format(name_list, id(name_list)))
name_list5 = name_list.extend('牛魔王')
print('使用extend方法後name_list5的值={0};內存地址={1}'.format(name_list4, id(name_list4)))
print("使用extend方法後name_list的值{0};內存地址={1}".format(name_list, id(name_list)))
運行結果是:
原始的name_list的值=['', '小偉', '小小偉', '超人'];內存地址=2069467533448
使用+運算符後name_list3的值=['', '小偉', '小小偉', '超人', '牛魔王'];內存地址=2069467533896
使用+運算符後name_list的值['', '小偉', '小小偉', '超人'];內存地址=2069467533448
使用append方法後name_list4的值=None;內存地址=2012521616
使用append方法後name_list的值['', '小偉', '小小偉', '超人', '牛魔王'];內存地址=2069467533448
使用extend方法後name_list5的值=None;內存地址=2012521616
使用extend方法後name_list的值['', '小偉', '小小偉', '超人', '牛魔王', '牛', '魔', '王'];內存地址=2069467533448
從運行結果可以看出如下幾點:
說完了列表,接著讓我們來看看另外一個重要的序列–元組(tuple),和列表類似,元組也是由一系列按特定書序排序的元素組成,與列表最重要的區別是,元組屬於不可變序列,即元組一旦被創建,它的元素就不可更改了。
第一種:使用()直接創建
使用()創建元組的語法結構是tuplename=(element1,element2,....,elementn),其中tuplename表示元組的變量名,element1~elementn表示元組中的元素。小括號不是必須的,只要將元素用逗號分隔,Python就會將其視為元組。還是舉個栗子:
#創建元組
tuple_name = ('', '小偉', '小小偉', '超人')
print(tuple_name)
#去掉小括號創建元組
tuple2 = '', '小偉', '小小偉', '超人'
print(type(tuple2))
運行結果是:
('', '小偉', '小小偉', '超人')
<class 'tuple'>
第二種:使用tuple()函數創建
與列表類似的,我們可以通過tuple(iterable)函數來創建元組,如果iterable傳入為空,則創建一個空的元組,iterable 參數必須是可迭代的序列,比如字符串,列表,元組等。同樣的iterable不能傳入一個數字。舉個栗子:
name_list = ['', '小偉', '小小偉', '超人']
print(tuple(name_list))
print(tuple(''))
運行結果是:
('', '小偉', '小小偉', '超人')
('碼', '農', '飛', '哥')
由於元組是不可變序列,所以沒有修改元素相關的方法,只能對元組中的元素進行查看。查看元素的方式也與列表類似,共兩種方式:
第一種:通過索引(index)訪問元組中的元素,其語法結構是tuplename[index]
第二種:通過切片的方式訪問,其語法結構是:tuplename[start:end:step]
相關參數的描述在此不再贅述了。依然是舉例說明:
tuple_name = ('', '小偉', '小小偉', '超人')
# 獲取索引為1的元素值
print(tuple_name[1])
#獲取索引為1到索引為2之間的元素值,不包括索引2本身
print(tuple_name[0:2])
運行結果是:
小偉
('', '小偉')
元組中的元素不能修改,不過可以通過 + 來生成一個新的元組。
詳細內容可以查看【Python從入門到精通】(六)Python內置的數據類型-列表(list)和元組(tuple),九淺一深,十個章節,不信你用不到
創建字典的方式有很多種,下面羅列幾種比較常見的方法。
第一種:使用 {} 符號來創建字典,其語法結構是dictname={'key1':'value1', 'key2':'value2', ..., 'keyn':valuen}
第二種:使用fromkeys方法,其語法結構是dictname = dict.fromkeys(list,value=None), 其中,list參數表示字典中所有鍵的列表(list),value參數表示默認值,如果不寫則為所有的值都為空值None。
第三種:使用dict方法,其分為四種情況:
dict() -> 創建一個空字典
dict(mapping) -> 創建一個字典,初始化時其鍵值分別來自於mapping中的key,value。
dict(iterable) -> 創建一個字典,初始化時會遍歷iterable得到其鍵值。
for k, v in iterable:
d[k] = v
dict(**kwargs) -> **kwargs 是可變函數,其調用的語法格式是:dict(key1=value1,key2=value2,...keyn=valuen),例如:dict(name='', age=17, weight=63)
這三種創建字典的方式都介紹完了,下面就來看看示例說明吧:
#1. 創建字典
d = {‘name’: ‘’, ‘age’: 18, ‘height’: 185}
print(d)
list = [‘name’, ‘age’, ‘height’]
dict_demo = dict.fromkeys(list)
dict_demo1 = dict.fromkeys(list, ‘測試’)
print(dict_demo)
print(dict_demo1)
demo = [(‘name’, ‘’), (‘age’, 19)]
dict_demo2 = dict(demo)
print(dict_demo2)
dict_demo21 = dict(name=‘’, age=17, weight=63)
print(dict_demo21)
運行結果是:
{'name': '', 'age': 18, 'height': 185}
{'name': None, 'age': None, 'height': None}
{'name': '測試', 'age': '測試', 'height': '測試'}
{'name': '', 'age': 19}
{'name': '', 'age': 17, 'weight': 63}
說完了字典的創建之後,接著就讓我們來看看字典的訪問。字典不同於列表和元組,字典中的元素不是依次存儲在內存區域中的;所以,字典中的元素不能通過索引來訪問,只能是通過鍵來查找對應的值。 ,其有兩種不同的寫法。
第一種方式的語法格式是dictname[key] ,其中dictname表示字典的名稱,key表示指定的鍵。如果指定的鍵不存在的話,則會報KeyError 錯誤。
第二種方式的語法格式是dictname.get(key),其中dictname表示字典的名稱,key表示指定的鍵。如果指定的鍵不存在的話,則會返回None。
舉個栗子說明下吧,下面代碼的意思是根據鍵名為name 查找其對應的值。
dict_demo5 = {‘name’: ‘’, ‘age’: 18, ‘height’: 185}
print(dict_demo5[‘name’])
print(dict_demo5.get(‘name’))
print(‘鍵不存在的情況返回結果=’,dict_demo5.get(‘test’))
運行結果是:
鍵不存在的情況返回結果= None
添加鍵值對的方法很簡單,其語法結構是dictname[key]=value,如果key在字典中不存在的話,則會新增一個鍵值對。如果key在字典中存在的話,則會更新原來鍵所對應的值。依然是舉例說明下:本例中代碼的結果是增加鍵值對 sex='男',把鍵height對應的值改成了190。
# 添加鍵值對
dict_demo6 = {'name': '', 'age': 18, 'height': 185}
dict_demo6['sex'] = '男'
print('新增鍵值對的結果={0}'.format(dict_demo6))
# 修改鍵值對
dict_demo6['height'] = 190
print('修改鍵值對的結果={0}'.format(dict_demo6))
運行結果是:
新增鍵值對的結果={'age': 18, 'name': '', 'height': 185, 'sex': '男'}
修改鍵值對的結果={'age': 18, 'name': '', 'height': 190, 'sex': '男'}
當然修改和刪除鍵值對也可以通過update方法來實現,其具體的語法格式是:dictname.update(dict) ,其中,dictname為字典的名稱,dict為要修改的字典的值。該方法既可以新增鍵值對,也可以修改鍵值對。 該方法沒有返回值,即是在原字典上修改元素的。下面例子中就是將鍵name的值改成了飛飛1024,鍵age對應的值改成了25。並新增了鍵值對 like=學習。
# update方法
dict_demo7 = {'name': '', 'age': 18, 'height': 185, 'width': 100}
dict_demo7.update({'name': '飛飛1024', 'age': 25, 'like': '學習'})
print('update方法返回結果={}', dict_demo7)
運行結果為:
update方法返回結果={} {'height': 185, 'like': '學習', 'width': 100, 'name': '飛飛1024', 'age': 25}
刪除鍵值對的方法有三種:
第一種是del dictname[key],使用del關鍵字,其中dictname為字典的名稱,key為要刪除的鍵。如果鍵不存在的話則會報KeyError錯誤。
第二種方式是通過pop方法,其語法結構是:dictname.pop(key)。該方法是用於刪除指定鍵值對,沒有返回值,如果key不存在的話不會報錯。
第三種方式是通過popitem方法,其語法結構是:dictname.popitem()。該方法用於刪除字典中最後一個鍵值對。舉例說明下吧:
dict_demo10 = {‘name’: ‘’, ‘age’: 18, ‘height’: 185, ‘width’: 100}
del dict_demo6[‘height’]
print(‘刪除鍵height對之後的結果=’, dict_demo6)
dict_demo10.pop(‘width’)
print(‘pop方法調用刪除鍵width之後結果=’, dict_demo10)
dict_demo10 = {‘name’: ‘’, ‘age’: 18, ‘height’: 185, ‘width’: 100}
dict_demo10.popitem()
print(‘popitem方法調用之後結果=’, dict_demo10)
運行結果是:
刪除鍵height對之後的結果= {'name': '', 'sex': '男', 'age': 18}
pop方法調用刪除鍵width之後結果= {'name': '', 'height': 185, 'age': 18}
popitem方法調用之後結果= {'name': '', 'age': 18, 'height': 185}
可以看出popitem方法刪除的鍵是最後一個鍵width。
詳細內容可以查看【Python從入門到精通】(七)Python字典(dict)讓人人都能找到自己的另一半(鍵值對,成雙成對)
列表推導式的語法格式是
[表達式 for 迭代變量 in 可迭代對象 [if 條件表達式] ]
此格式中,[if 條件表達式]不是必須的,可以使用,也可以省略。下面就是輸出1~10的列表的乘積的一個例子:
L = [x * x for x in range(1, 11)]
print(L)
此表達式相當於
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
運行結果是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
來點復雜的吧,下面就是輸出
print([x for x in range(1, 11) if x % 2 == 0])
運行結果是[2, 4, 6, 8, 10]
再來點復雜的,使用多個循環,生成推導式。
d_list = [(x, y) for x in range(5) for y in range(4)]
print(d_list)
運行結果是:
[(0, 0), (0, 1), (0, 2), (0, 3), (1, 0), (1, 1), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (3, 0), (3, 1), (3, 2), (3, 3), (4, 0), (4, 1), (4, 2), (4, 3)]
上面代碼,x是遍歷range(5)的迭代變量(計數器),因此該x可迭代5次,y是遍歷range(4)的計數器,因此該y可迭代4次。因此,該(x,y)表達式一共迭代了20次。它相當於下面這樣一個嵌套表達式。
dd_list = []
for x in range(5):
for y in range(4):
dd_list.append((x, y))
print(dd_list)
元組推導式與列表推導式類似,其語法結構是:
(表達式 for 迭代變量 in 可迭代對象 [if 條件表達式] )
此格式中,[if 條件表達式]不是必須的,可以使用,也可以省略。下面就是輸出1~10的元組的乘積的一個例子:
d_tuple = (x * x for x in range(1, 11))
print(d_tuple)
運行結果是:
<generator object <genexpr> at 0x103322e08>
從上面的執行結果可以看出,使用元組推導式生成的結果並不是一個元組,而是一個生成器對象。
使用tuple()函數,可以直接將生成器對象轉換成元組。例如:
d_tuple = (x * x for x in range(1, 11))
print(tuple(d_tuple))
輸出結果是(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)
字典推導式的語法結構是:
{表達式 for 迭代變量 in 可迭代對象 [if 條件表達式]}
其中[if 條件表達式]可以使用,也可以省略。舉個例子:
key_list = ['姓名:', '年齡:18', '愛好:寫博客']
test_dict = {key.split(':')[0]: key.split(':')[1] for key in key_list}
print(test_dict)
運行結果是:
{'愛好': '寫博客', '年齡': '18', '姓名': ''}
通過yield關鍵字配合循環可以做一個生成器,就像下面這樣
def generate():
a = 2
while True:
a += 1
yield a
b = generate()
print(b)
print(next(b))
print(next(b))
print(next(b))
運行結果
<generator object generate at 0x7fc01af19b30>
3
4
5
這裡generate方法返回的就是一個生成器對象generator,因為它內部使用了yield關鍵字,
調用一次next()方法返回一個生成器中的結果。這就很像單例模式中的懶漢模式,他並並不像餓漢模式一樣事先將列表數據生成好。
流程控制有三種結構,一種是順序結構,一種是選擇(分支)結構,一種是循環結構。
順序結構:就是讓程序按照從頭到尾的順序執行代碼,不重復執行任何一行代碼,也不跳過任何一行代碼。一步一個腳印表示的就是這個意思。
選擇(分支)結構:就是讓程序根據不同的條件執行不同的代碼,比如:根據年齡判斷某個人是否是成年人。
循環結構: 就是讓程序循環執行某一段代碼。順序的流程這裡不做介紹了。
只使用if語句是Python中最簡單的形式。如果滿足條件則執行表達式。則跳過表達式的執行。其偽代碼是:
if 條件為真:
代碼塊
如果if 後面的條件為真則執行代碼塊。否則則跳過代碼的執行。
其流程圖是: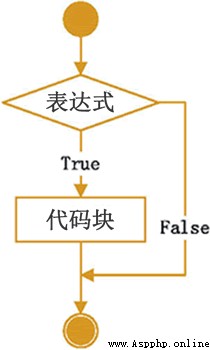
就是說只使用if的話,則表達式成立的話執行代碼塊,不成立的話就結束。
下面就是一個簡單的例子,如果滿足a==1這個條件則打印a,否則跳過該語句。
a = 1
if a == 1:
print(a)
if else語句是if的變體,如果滿足條件的話則執行代碼塊1,否則則執行代碼塊2。其偽代碼是:
if 條件為真:
代碼塊1
else
代碼塊2
流程圖是: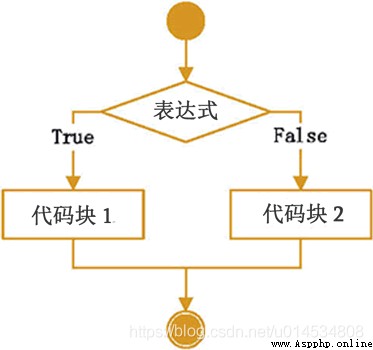
同時使用if和else的話,則表達式成立的話執行一個代碼塊,表達式不成立的話則執行另一個代碼塊。
舉個簡單的例子吧。
age = 3
if age >= 18:
print('your age is', age)
print('adult')
else:
print("your age is", age)
print('kid')
根據輸入的年齡判斷某人是否是成年人。如果age大於等於18歲,則輸出adult,否則輸出kid。
if elif else語句針對的就是多個條件判斷的情況,如果if條件不滿足則執行elif的條件,如果elif的條件也不滿足的話,則執行else裡面的表達式。其偽代碼是:
if 條件為真:
表達式a
elif 條件為真:
表達式b
....
elif 條件為真:
表達是n-1
else
表達式n
其中elif可以有多個,但是elif不能單獨使用,必須搭配if和else一起使用。
需要注意的是if,elif和else後面的代碼塊一定要縮進,而且縮進量要大於if,elif和else本身,建議的縮進量是4個空格。同一代碼中所有語句都要有相同的縮進。 依然是舉例說明:
bmi = 80.5 / (1.75 * 1.75)
if bmi < 18.5:
print('過輕')
elif 18.5 <= bmi < 25:
print('正常')
elif 25 <= bmi < 28:
print('過重')
elif 28 <= bmi < 32:
print('肥胖')
else:
print('嚴重肥胖')
pass
下面就是根據bmi標准來判斷一個人是過輕,正常還是肥胖。pass是Python中的關鍵字,用來讓解釋器跳過此處,什麼都不做。
while是作為循環的一個關鍵字。其偽代碼是:
while 條件表達式:
代碼塊
一定要保證循環條件有變成假的時候,否則這個循環將成為一個死循環,即該循環無法結束。 其流程圖是: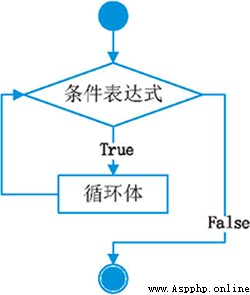
如果while中的表達式成立的話則執行循環體,否則的話則直接結束。
舉個栗子:計算從1~100的求和,這就是一個經典的運用循環的場景
sum = 0
n = 1
while n <= 100:
sum = sum + n
n = n + 1
print('sum=', sum)
運行結果是sum= 5050,這個循環的結束條件是n>100,也就是說當n>100是會跳出循環。
在介紹range函數時用到了for關鍵字,這裡介紹一下for關鍵字的使用。其語法結構是:
for 迭代變量 in 字符串|列表|元組|字典|集合:
代碼塊
字符串,列表,元祖,字典,集合都可以還用for來迭代。其流程圖是: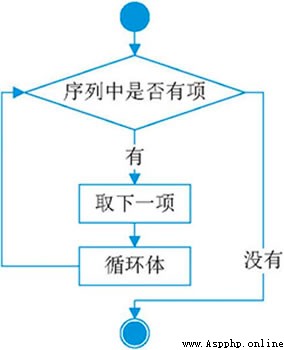
for 循環就是:首先根據in 關鍵字判斷序列中是否有項,如果有的話則取下一項,接著執行循環體。如果沒有的話則直接結束循環。
詳細內容可以查看【Python從入門到精通】(十)Python流程控制的關鍵字該怎麼用呢?列表推導式,生成器【收藏下來,常看常新】
函數是按照固定格式封裝組織的可以重復使用的代碼段。它能提高應用的模塊性和代碼的重復利用率。
函數定義的語法格式是:
def 函數名(參數列表):
代碼塊
[return [返回值]]
函數名:其實就是一個符合Python語法的標識符,函數名最好能體現該函數的功能,比如: save_user。
形參列表:設置該函數可以接收多少個參數,多個參數之間用逗號(,)分割。需要注意的是沒有參數的話,也需要留一對空的()[return[返回值]]:整體作為函數的可選參數,用於設置該函數的返回值。也就是說,一個函數,
可以有返回值,也可以沒有返回值。
調用函數的語法格式是:
[返回值]=函數名([形參值])
函數名即指的是要調用的函數的名稱,形參值指的是當初創建函數時要求傳入的各個形參的值。
如果該函數有返回值,我們可以通過一個變量來接收該值,當然也可以不接收。需要注意的是,函數有多少個形參,那麼調用的時候就需要傳入多少個值,
且順序必須和創建函數時一致。即便該函數沒有參數,函數名後的小括號也不能省略。
舉個栗子吧:
def my_abs(x):
"""
返回絕對值
:param x:
:return:
"""
if not isinstance(x, (int, float)):
raise TypeError('傳入的數據類型不對')
if x >= 0:
return x
else:
return -x
調用代碼是:
x = my_abs(-3)
print(x)
print(my_abs.__doc__)
運行結果是:
3
返回絕對值
:param x:
:return:
這是一個獲取絕對值的函數,其函數名是my_abs,通過函數名可以讓人大致明白函數的作用。形式參數是x。通過__doc__可以查看函數的說明文檔。其返回值是處理後的值。
介紹函數值傳遞和引用傳遞之前首先需要了解兩個概念。
形式參數(簡稱形參):在定義函數時,函數名後面括號中的參數就是形式參數,可以將形參想象成劇本中的角色。
實際參數(簡稱實參):在調用函數時,函數名後面括號中的參數稱為實際參數,也就是函數的調用者給函數的參數,可以將實參想象成演角色的演員。
函數參數傳遞方式分為兩種:分別是值傳遞和引用傳遞:
值傳遞:適用於實參類型為不可變類型(字符串,數字,元組)
引用(地址)傳遞:適用於實參類型為可變類型(列表,字典)
值傳遞和引用傳遞的區別是:函數參數進行值傳遞時,若形參發生改變,不會影響實參的值。而應用傳遞的話,改變形參的值,實參的值也會一同改變。依然是舉例說明:
函數param_test會將形參obj變成 obj+obj。如果是值傳遞則調用函數param_test之後,實參的值不變。如果是引用傳遞的話則調用param_test之後,實參的值也會變成 obj+obj。
def param_test(obj):
obj += obj
print(‘形參值為:’, obj)
print(‘**值傳遞’)
a = ‘’
print(‘a的值為:’, a)
param_test(a)
print(‘實參的值為:’, a)
print(“**引用傳遞”)
b = [1, 2, 3]
print(‘b的值為:’, b)
param_test(b)
print(‘實參的值為:’, b)
運行結果是:
*******值傳遞*****
a的值為:
形參值為:
實參的值為:
*******引用傳遞*****
b的值為: [1, 2, 3]
形參值為: [1, 2, 3, 1, 2, 3]
實參的值為: [1, 2, 3, 1, 2, 3]
位置參數,有時也被稱為必備參數,指的是必須按照正確的順序將實參傳到函數中,換句話說,調用函數時傳入實參的數量和位置必須和定義函數時保持一致。如果不一致的話,則在程序運行時Python解釋器會報TypeError異常。舉個例子,下面演示調用函數事參數傳入的數量不對的情況。
def girth(width , height):
return 2 * width+height
#調用函數時,必須傳遞 2 個參數,否則會引發錯誤
print(girth(3))
運行之後直接報Traceback錯誤。
Traceback (most recent call last):
File "/Volumes/Develop/Python_learn/PycharmProjects/python_demo_1/demo/function/locate_fun.py", line 6, in <module>
print(girth(3))
TypeError: girth() missing 1 required positional argument: 'height'
傳入參數的位置不對的情況,本例中本想傳入name的值為,age的值為18。結果入參順序不對導致得到的結果不對。
def print_info(name, age):
print('姓名=' + name + " 年齡=" + str(age))
print_info(18,'')
那麼怎麼處理這種情況呢?有兩種方式:
嚴格按照形參的數量和位置入參。
按照關鍵字參數入參,所謂的關鍵字參數就是指使用形參的名字來確定輸入的參數值。通過此方式制定函數實參時,不再需要與形參的位置完全一致,只要將參數名寫正確即可。還是以上面的函數為例:
利用關鍵字參數來調用函數的話則是這樣寫:
def print_info(name, age):
print(‘姓名=’ + name + " 年齡=" + str(age))
print_info(age=18,name=‘’)
運行結果是:
姓名= 年齡=18
可以看出關鍵字參數入參時,不需要保證入參的順序跟形參的順序保持一致。
前面介紹的位置參數,就是說調用函數時必須要傳入該參數。但是有些場景下我們並不想傳入所有的參數。這種情況下就可以使用默認參數了。不過需要注意的是:指定有默認值的形式參數必須在所有沒默認值的參數的最後,否則會產生語法錯誤。其語法格式是:
def 函數名(...,形參名,形參名=默認值):
代碼塊
下面給出一個示例,該函數是記錄學生的信息,有兩個有默認值的參數,分別是age和city。它們都被置於函數的形參列表最後處。
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print("gender:", gender)
print("age:", age)
print("city:", city)
print(enroll('張三', '一年級'))
print('************************** ')
print(enroll('李四', '二年級', 7))
運行結果是:
name: 張三
gender: 一年級
age: 6
city: Beijing
None
**************************
name: 李四
gender: 二年級
age: 7
city: Beijing
None
從上面代碼可以看出:1. 可以不用傳入有默認值的參數。2. 如果傳入默認的參數,則會覆蓋掉默認值。
Python函數可變參數(*args,**kwargs),又稱為不定長參數,即傳入函數中的實際參數可以是任意多個,Python定義可以變參數,主要有以下兩種形式:
在形參前添加一個*,格式是*args。表示創建一個名為args的空元組,該元組可以接受任意多個外界傳入的非關鍵字實參。必須以非關鍵字參數的形式給普通參數傳值,否則Python解釋器會把所有參數都優先傳給可變參數。
**kwargs表示創建一個名為kwargs的空字典,該字典可以接受任意多個以關鍵字參數賦值的實參。舉個??,下面就是根據傳入的值求和。
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n
return sum
print(calc(10, 9))
運行的結果是:19。
再舉個例子呗:
def record(str, **kwargs):
print('str=', str)
print('kwargs=', kwargs)
record('測試', name='', age=20)
record('測試2')
運行結果是:
str= 測試
kwargs= {'age': 20, 'name': ''}
str= 測試2
kwargs= {}
從上面代碼可以看出,可變參數可以不用傳入,不傳的話則會創建一個空元組或者空字典。
Python不僅有可變參數,將多個參數打包到一個元組或者字典中,還支持逆向參數收集,即直接將列表,元組,字典作為函數參數。不過調用函數時要對實參加上*號。就像下面這樣:
def param_test(name, age):
print('name=', name)
print('age=', age)
data = ['', 18]
param_test(*data)
運行結果是:
name=
age= 18
一個函數可以有返回值,也可以沒有返回值,有返回值的語法結構是:
return [返回值]
返回值可以指定,也可以省略不寫。如果不寫的話就默認為是None,即空值。
通常情況下,一個函數只有一個返回值,實際上Python也是如此,
只不過Python函數能以返回列表或元組的方式,將要返回的多個值保存到序列中,從而間接實現返回多個值的目的。
在函數中,提前將要返回的多個值存儲到一個列表或元組中,然後函數返回該列表或元組
函數直接返回多個值,之間用逗號(,)分隔,Python會自動將多個值封裝到一個元組中,其返回值仍是一個元組。下面就舉例說明下:
def multi_return():
return_tuple = (‘張三’, 12)
return return_tuple
def multi_return2():
return ‘張三’, 12
print(multi_return())
result = multi_return2()
print(‘multi_return2返回值是=,類型是=’, result, type(result))
運行結果是
('張三', 12)
multi_return2返回值是=,類型是= ('張三', 12) <class 'tuple'>
Python函數參數傳遞機制有兩種:分別是值傳遞和引用傳遞。那麼這兩種方式有啥區別呢?各自具體的參數傳遞機制又是啥呢?這個章節就將來解答這兩個問題。首先來看看值傳遞。如下代碼定義了一個swap函數,有兩個入參a,b。這個函數的工作就是交換入參a,b的值。
def swap(a, b):
a, b = b, a
print("形參a=", a, 'b=', b)
return a, b
a, b = '', '加油'
print("調用函數前實參的a=", a, 'b=', b)
swap(a, b)
print("調用函數後實參的a=", a, 'b=', b)
運行結果是:
調用函數前實參的a= b= 加油
形參a= 加油 b=
調用函數後實參的a= b= 加油
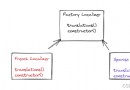
可以看出形參被成功的改變了,但是並沒有影響到實參。這到底是為啥呢?這其實是由於swap函數中形參a,b的值分別是實參a,b值的副本,也就是說在調用swap之後python會對入參a,b分別copy一份給swap函數的形參。對副本的改變當然不影響原來的數值啦。 語言的描述是空洞的,畫個圖說明下吧:在Python中一個方法對應一個棧幀,棧是一種後進先出的結構。上面說的過程可以用下面的調用圖來表示: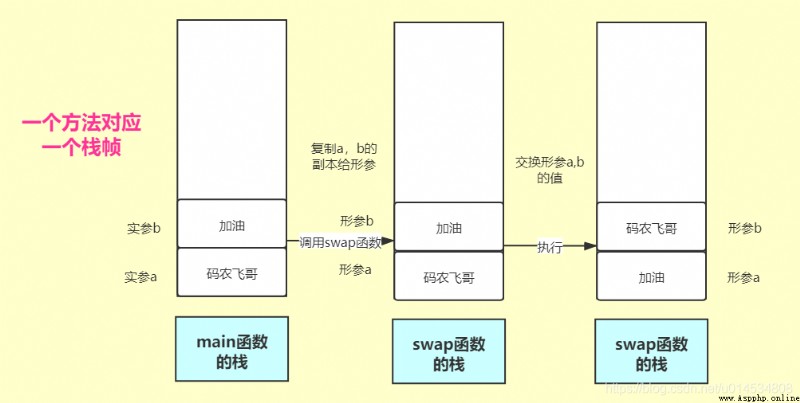
可以看出當執行a, b = '', '加油' 代碼是,Python會在main函數棧中初始化a,b的值。當調用swap函數時,又把main函數中a,b的值分別copy一份傳給swap函數棧。當swap函數對a,b的值進行交換時,也就只影響到a,b的副本了,而對a,b本身沒影響。
但是對於列表,字典這兩的數據類型的話,由於數據是存儲在堆中,棧中只存儲了引用,所以在修改形參數據時實參會改變。。如下代碼演示:
def swap(dw):
# 下面代碼實現dw的a、b兩個元素的值交換
dw['a'], dw['b'] = dw['b'], dw['a']
print("swap函數裡,a =", dw['a'], " b =", dw['b'])
dw = {'a': '', 'b': '加油'}
print("調用函數前外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
swap(dw)
print("調用函數後外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
運行結果是:
調用函數前外部 dw 字典中,a = b = 加油
swap函數裡,a = 加油 b =
調用函數後外部 dw 字典中,a = 加油 b =
可以清晰的看出調用函數之後傳入的實參dw的值確實改變了。這說明他是引用傳遞的,那麼引用傳遞與值傳遞有啥區別呢?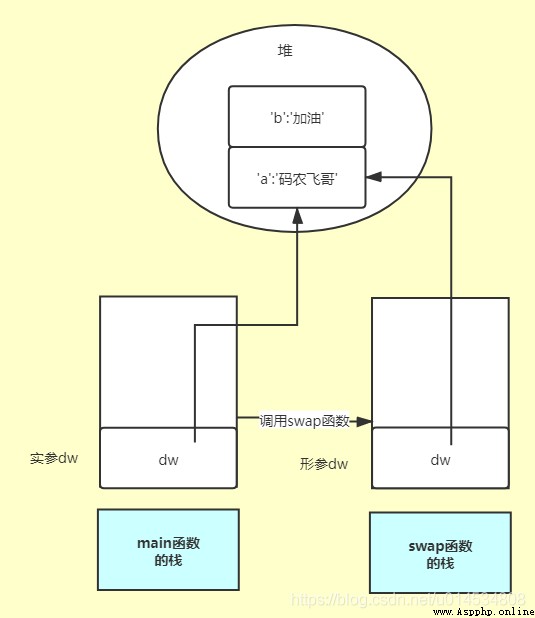
從上圖可以看出字典的數據是存儲在堆中的,在main函數的棧中通過引用來指向字典存儲的內存區域,當調用swap函數時,python會將dw的引用復制一份給形參,當然復制的引用指向的是同一個字典存儲的內存區域。當通過副本引用來操作字典時,字典的數據當然也改變。綜上所述:引用傳遞本質上也是值傳遞,只不過這個值是指引用指針本身,而不是引用所指向的值。 為了驗證這個結論我們可以稍微改造下上面的代碼:
def swap(dw):
# 下面代碼實現dw的a、b兩個元素的值交換
dw['a'], dw['b'] = dw['b'], dw['a']
print("swap函數裡,a =", dw['a'], " b =", dw['b'])
dw = None
print("刪除形參對字典的引用",dw)
dw = {'a': '', 'b': '加油'}
print("調用函數前外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
swap(dw)
print("調用函數後外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
運行的結果是:
調用函數前外部 dw 字典中,a = b = 加油
swap函數裡,a = 加油 b =
刪除形參對字典的引用
調用函數後外部 dw 字典中,a = 加油 b =
刪除了形參對字典的引用後,實參還是能獲取到字典的值。這就充分說明了傳給形參的是實參的引用的副本。
詳細內容可以查看:【Python從入門到精通】(十一)Python的函數的方方面面【收藏下來保證有用!!!】
【Python從入門到精通】(十二)Python函數的高級知識點,更深入的吸收知識,不做知識的牙簽(不淺嘗辄止)【收藏下來保證有用!!!】
面向對象(Object-oriented Programming,簡稱 OOP)的思想其本質上是一種對事物抽象封裝的思想。
封裝就是將隱藏具體的細節內容,就好像用戶使用電腦,只需要簡單的操作鍵盤和鼠標就可以實現一些功能。而無需了解計算機內部是如何實現的。
而在Python語言中的面向對象的封裝是將描述特性的數據(屬性)和描述行為(方法)封裝在一起。
比如現在要描述一個人的話,我們首先會從兩方面描述:
從表面特征描述:例如: 膚色,身高,體重,年齡
從所具有的行為描述:例如:會吃飯,會走路,會說話。
如果通過代碼來實現的話,其表面特征可以用變量來表示,其行為可以用各種方法來表示。
class Person:
# 膚色
colour = ‘黃色’
# 身高
height = ‘180cm’
# 體重
weight = ‘60KG’
# 年齡
age = 18
def eat(self):
print('吃飯')
def walk(self):
print('走路')
def speak(self):
print('說話')
zhangsan=Person()
lisi=Person()
wanger=Person()
通過構建一個Person類就可以將人的特性和行為都封裝起來。人都是有共性的,也就是說可以通過這個類來創建出各種不同的對象。這裡不得不說面向對象裡的幾個核心概念。
類可以理解成可以理解成是一個模板,根據這個模板可以創建出許許多多的具體對象,可以把類想象成是一個模子亦或者是一張圖紙。
類並不能直接直接被使用, 通過類創建出來的具體的實例(又稱為對象)才能被使用。這就像汽車的圖紙與車本身的關系。大多數情況下,圖紙並不能被普通人所使用,但是通過圖紙創建出的一輛輛汽車能被使用。就像上面通過Person類可以創造出張三,李四,王二麻子。
zhangsan=Person()
lisi=Person()
wanger=Person()
類中所有的變量都是類的屬性,比如上面的身高height,體重weight等屬性。
類中的所有函數都被稱為方法,不過,和函數有所不同的是類方法至少要包含一個 self 參數(後續會做詳細介紹)。就像上面Person類的eat方法,walk方法。另外,就是類中的方法不能單獨使用,必須通過類創建的對象調用。
類的定義必須要通過class關鍵字修飾,類名的命名規范建議是每個單詞的首字母大寫,其余字母小寫。
class 類名:
多個(>=0)類屬性
多個(>=0)類的方法
就像上面的Person類,其有屬性height,weight等幾個屬性。也有eat,walk等多個方法。
不過這裡有個隱藏的方法,那就是類構造方法__init__()。該方法是一個特殊的類實例方法。Python是通過該方法來創建類的實例。該方法的方法名是固定的,開頭和結尾各有2個下劃線並且中間不能有空格。
在創建類之後,Python會創建一個默認的構造方法__init__()。如果沒有手動添加__init__()方法的話則使用默認的構造方法創建類的實例(即對象)。 __init__()方法的語法結構是:
def __init__(self,...):
代碼塊
__init__()方法可以有多個參數,但必須包含一個名為self的參數,並且self的參數必須為第一個參數,如果沒有其他參數則是默認構造方法。以上面的Person類為例,可以手動添加一個帶其他參數的__init__()方法。
def __init__(self, head):
self.hand = head
如果手動添加了其他的__init__()方法,則會覆蓋掉默認的構造方法。創建對象時會使用你手動添加的__init__()方法。
創建類對象的過程被稱為類的實例化,其語法結構是類名(參數), 當使用的是默認構造方法時或者添加的__init__()方法中僅有一個self參數,則創建類對象時參數可以不寫。
但是如果__init__()方法中除了self參數還有其他參數的話,則參數必傳。不然,就會報類似於下面的錯誤。
Traceback (most recent call last):
File "/Python_learn/PycharmProjects/python_demo_1/demo/oop/person.py", line 15, in <module>
person = Person()
TypeError: __init__() missing 1 required positional argument: 'head'
這裡就必須要傳入head參數。
person = Person('頭')
person.eat()
前面幾個章節我們多次提到了self參數,那麼這個參數到底有啥作用呢?我們知道類是一個模板,通過類這個模板可以創建出許許多多的對象。那麼該如何區分這些對象呢?就像每個人都有自己的名字一樣,實例化的對象在Python中也有屬於自己的代號(自身的引用)。而python正是通過self參數來綁定調用對象本身。說白了就是通過self參數可以知道當前的方法是被誰調用了。專業一點的解釋是,當某個對象調用類方法時,該方法會把自身的引用作為第一個參數自動傳給該方法。
class Person:
def __init__(self):
print('正在執行構造方法')
def eat(self):
print(self, '正在吃飯')
zhangsan = Person()
zhangsan.eat()
lisi = Person()
lisi.eat()
其運行結果是:
正在執行構造方法
<__main__.Person object at 0x1031cd0f0> 正在吃飯
正在執行構造方法
<__main__.Person object at 0x103338da0> 正在吃飯
這裡實例化了zhangsan和lisi兩個對象。當他們同時調用eat方法時,Python會將其自身的引用綁定到self參數上,可以明顯的看出不同的調用者其self參數是不同的。這裡的self參數就相當於是Java裡的this參數。
類的變量有三種,分別是類變量,實例變量和局部變量。下面直接舉個例子吧!下面代碼定義了一個Person類,該類定義了了三個變量,兩個方法。
class Person:
name = '張三'
def __init__(self):
self.age = 18
def get_info(self):
sex = '男'
print('局部變量sex=', sex)
return sex
print('類屬性name=', Person.name)
person = Person()
print('實例屬性age=', person.age)
person.get_info()
運行結果是:
類屬性name= 張三
實例屬性age= 18
局部變量sex= 男
這裡name,age以及sex三個變量分別是三種不同的變量。下面就分別介紹一下
其中定義在了類體中,所有函數之外;此范圍定義的變量就稱為類變量,就像上面代碼中的name變量。類變量屬於整個類。可以直接通過類名.變量名來獲取,就像上面的Person.name。在實際開發中類變量用的比較少。
定義在類體中,函數內部並且以self.變量名定義的變量就稱為實例變量。就像上面代碼中的age變量。實例變量只作用於調用方法的對象,只能通過對象名訪問,無法通過類名訪問。調用方式如上面實例中的person.age。
定義在類體中,函數內部的變量以"變量名=變量值"的方式定義的變量就稱為局部變量。就像上面代碼中的sex變量,局部變量只能在函數內部使用。
詳細內容可參考:
【Python從入門到精通】(十三)Python面向對象的開發,沒有對象怎麼能行呢?
【Python從入門到精通】(十四)Python面向對象的開發2,封裝,多繼承,多態都了解了麼
異常類的個數和種類有很多。但是這些異常類之間不是相互獨立的。它們的繼承關系如下圖所示: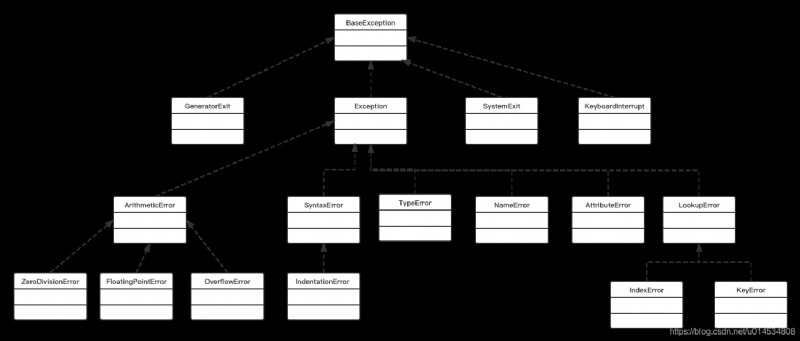
所有的異常類都繼承自基類BaseException類。這個基類BaseException類的父類是object類。基類BaseException類有四個子類。分別是GeneratorExit類,Exception類,SystemExit類,KeyboardInterrupt類。其中Exception類又是實際開發中最常接觸到的異常類,程序中可能出現的各種異常,都繼承自Exception.它以及它的子類構成了Python異常類結構的基礎。其余三個異常類比較少見。
Exception類同樣有三個子類,ArithmeticError類用來處理數字異常,BufferError用來處理字符異常。LookupError用來記錄關鍵字異常,
介紹完了各種異常類的繼承關系,接著就是介紹異常類的使用了。異常類的作用就是捕獲程序運行時的各種異常的,如果不手動捕獲異常的話,Python程序在遇到異常之後就會拋出異常並停止程序的運行。捕獲異常的語法結構如下:
try:
可能產生異常的代碼塊
except [ (Error1, Error2, ... ) [as e] ]:
處理異常的代碼塊1
except [ (Error3, Error4, ... ) [as e] ]:
處理異常的代碼塊2
except [Exception]:
處理其它異常
括號[]括起來的部分可以使用,也可以省略。其中:
它的執行過程是:
首先執行try中的代碼塊,如果執行過程中出現異常,系統會自動生成一個異常類型,並將該異常提交給Python解釋器,此過程稱為捕獲異常。
當Python解釋器收到異常對象時,會尋找能處理該對象的except塊,如果找到合適的except塊,則把該異常交給該except塊處理,這個過程稱為處理異常。如果Python解釋器找不到處理異常的except塊,則程序運行終止,Python解釋器也將退出。
還是舉個簡單的例子:
try:
print(‘try…’)
r = 10 / 0
print(‘result’, r)
except ZeroDivisionError as e:
print(‘ZeroDivisionError’, e)
except Exception as e:
print(‘Exception’, e)
print(‘END’)
運行結果是:
try....
ZeroDivisionError division by zero
END
可以看出當ZeroDivisionError異常能夠匹配Python解釋器自動生成的異常程序就會進入該except塊中。這裡需要注意的如果將Exception的except塊寫到ZeroDivisionError的except塊前面的話,則運行結果會變成下面的結果。這是因為
ZeroDivisionError是Exception類的子類。
try....
Exception division by zero
END
每種異常類型都提供了如下幾個屬性和方法,通過調用它們就可以獲取當前異常類型的相關信息。
args: 返回異常的錯誤編號和描述符號
str(e):返回異常信息,但不包括異常信息的類型。
repr(e):返回較全的異常信息,包括異常信息的類型。
try:
print(‘try…’)
r = 10 / 0
print(‘result’, r)
except ZeroDivisionError as e:
print(‘’, e.args)
print(‘’, str(e))
print(‘’, repr(e))
運行結果是:
try....
('division by zero',)
division by zero
ZeroDivisionError('division by zero')
finally代碼塊,無論try塊是否發生異常,最終都要進入finally語句中,並執行其中的代碼塊,在實際開發中可以將資源回收的工作放入finally塊中。這樣可以保證當不可預知的異常發生時,資源可以被正常回收。這裡的資源指的是數據庫連接,文件流的關閉等。
還是以上面的代碼為例:
try:
print('try....')
r = 10 / 0
print('result', r)
except Exception as e:
print('Exception', e)
except ZeroDivisionError as e:
print('ZeroDivisionError', e)
finally:
print('發生異常時finally語句塊執行...')
print('END')
try:
print('try....')
r = 10 / 1
print('result', r)
except Exception as e:
print('Exception', e)
except ZeroDivisionError as e:
print('ZeroDivisionError', e)
finally:
print('沒發生異常時finally語句塊執行...')
print('END')
運行結果是:
try....
Exception division by zero
發生異常時finally語句塊執行...
END
try....
result 10.0
沒發生異常時finally語句塊執行...
END
可以看出,無論try中是否發生異常,finally塊中的代碼都會執行。當然finally塊只需要搭配try塊使用就可以了。
有時候我們自定義了一個業務異常類,當觸發該異常時將該異常拋給其調用者。又或者當我們捕獲到一個未知異常時,需要將該異常封裝並拋給其調用者。這時候就可以使用raise關鍵字了。其語法結構是:
raise [exceptionName [(reason)]]
其有三種用法:
raise: 單獨一個raise。該語句引發當前上下文中捕獲的異常(比如except塊中)或默認引發RuntimeError異常。
raise異常名稱:raise後帶一個異常類名稱,表示引發執行類型的異常。
raise異常類名稱(描述信息):在引發指定類型的異常的同時,附帶異常的描述信息。
try:
a = input(“輸入一個數:”)
# 判斷用戶輸入的是否為數字
if (not a.isdigit()):
raise ValueError(“a 必須是數字”)
except ValueError as e:
print(“引發異常:”, repr(e))
當輸入一個字母或者漢字時就會拋出ValueError異常。
當然也可以在except中使用raise,將異常重新拋出。
詳細內容可參考:
【Python從入門到精通】(十五)Python異常機制,給代碼加上安全TAO,不放過一個異常
【Python從入門到精通】(十六)Python異常機制2,正確使用Python異常機制的姿勢是啥
什麼是模塊呢?簡單理解的話:模塊就是一個後綴名是.py的模板文件。模塊主要是用於封裝函數和變量。我們可以將實現某一個功能的所有函數封裝放在同一個.py文件中以作為一個模塊提供給其他模塊使用。比如操作日期的模塊time。其對應模板文件就是time.py。
導入模塊的方式有兩種:
import 模塊名1 [as 別名1], 模塊名2 [as 別名2],…
使用這種格式的import語句,會導入指定模塊中所有的成員(包括變量,函數、類等)
from 模塊名 import 成員名1 [as 別名1],成員名2 [as 別名2],…
使用這種格式的import語句,只會導入模塊中指定的成員,而不是全部成員。
用第一種方式導入time模塊,可以使用該模塊下所有的函數
import time
start_time = time.time()
print(start_time)
time.sleep(4)
print(time.time() - start_time)
可以看出導入time之後可以使用其模塊內的所有成員
用第二種方式導入time模塊中的sleep函數,則time函數是使用不了的。
from time import sleep
print(sleep())
PS:如果模塊名中出現空格就無法使用import引入模塊了,這是因為Python 是以空格來隔離一行語句中的不同元素的。針對有空格的模塊名的導入,可以通過__import__函數來導入。比如:現在有一個名為hello test.py的模板文件,可以以__import__("hello test") 這種方式導入。
自定義模塊說白了就是自行創建一個模板文件,然後使用其文件名作為模塊名導入到其他模板文件中。定義了一個名為hello的模板文件,然後在hello_test.py文件中導入。
hello.py文件
def say():
print('苦逼程序員唱著苦逼的歌')
say()
print(__name__)
這裡需要注意的是hello.py文件是放在Python項目的根目錄下。
hello_test.py文件
import hello
hello.say()
運行hello_test之後,輸出的結果是:
苦逼程序員唱著苦逼的歌
hello
苦逼程序員唱著苦逼的歌
我們看到輸出了兩遍,這顯然不是我們想要的結果。我們期望的是say函數只執行一遍,也就是在hello_test調用的地方執行。而不是在hello.py文件中還執行一遍。那麼這個問題該如何處理呢?
【Python從入門到精通】(十七)Python模塊和包的基本使用,簡單一文,一分鐘看完
Python對文件的操作比較方便。沒有像Java那樣整那麼多IO操作類。首先歡迎open函數粉墨登場,該函數主要是用來創建或者打開文件的,其語法格式是:
file=open(filename, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
file: 表示要創建的文件對象。
file_name:要創建或打開的文件的文件名稱,該名稱要用引號括起來,需要注意的是,如果要打開的文件和當前執行的代碼文件位於同一目錄,則直接寫文件名即可。否則此參數需要指定打開文件所在的完整路徑。
mode:可選參數,用於指定文件的打開模式,可選的打開模式如下表所示。如果不寫,則默認以只讀(r)模式打開文件。
buffering:可選參數,用於指定對文件做讀寫操作時,是否使用緩沖區。如果buffering參數的值為0(或者False)則表示在打開指定文件時不使用緩沖區;如果buffering參數值為大於1的整數,該整數用於緩沖區的大小(單位是字節);如果buffering參數的值為負數,則表示使用默認的緩沖區大小。默認情況下open函數是打開緩沖區的。
encoding: 手動設置打開文件時所使用的編碼格式,不同平台的ecoding參數值也不同,以Windows為例,其默認的GBK編碼。
表1. open函數支持的文件打開模式
模式
含義
注意事項
r
只讀模式打開文件,讀文件內容的指針會放在文件的開頭
操作的文件必須存在
rb
以二進制格式,采用只讀模式打開文件,讀文件內容的指針位於文件的開頭,一般用於非文本文件,如圖片文件、音頻文件
操作的文件必須存在
r+
打開文件後,既可以從頭讀取文件內容,也可以從開頭向文件中寫入新的內容,寫入的新內容會覆蓋文件中等長度的原有內容
操作的文件必須存在
rb+
以二進制格式、采用讀寫模式打開文件,讀寫文件的指針會放在文件的開頭,通常針對非文本文件 (如音頻文件)
操作的文件必須存在
w
以只寫模式打開文件,若該文件存在,打卡時會清空文件中原有的內容
若文件存在,會清空其原有內容(覆蓋文件);反之,則創建新文件。
wb
以二進制格式,只寫模式打開文件,一般用於非文本文件(如音頻文件)
若文件存在,會清空其原有內容(覆蓋文件);反之,則創建新文件。
w+
打開文件後,會對原有內容進行清空,並對該文件有讀寫權限
若文件存在,會清空其原有內容(覆蓋文件);反之,則創建新文件。
wb+
以二進制格式,讀寫模式打開文件,一般用於非文本文件
a
以追加模式打開一個文件,對文件只有寫入權限,如果文件已經存在,文件指針將放在文件的末尾(即新寫入內容會位於已有內容之後);反之,則會創建新文件
ab
以二進制格式打開文件,並采用追加模式,對文件只有寫權限,如果該文件已存在,文件指針位於文件末尾(新寫入文件會位於已有內容之後);反之,則創建新文件
a+
以讀寫模式打開文件,如果文件存在,文件指針放在文件的末尾(新寫入文件會位於已有內容之後);反之,則創建新文件
ab+
以二進制模式打開文件,並采用追加模式,對文件具有讀寫權限,如果文件存在,則文件指針位於文件的末尾(新寫入文件會位於已有內容之後);反之,則創建新文件
從上表我們可以得出如下結論:
文件的讀取有三種方法:
舉個例子吧!現創建一個名為my_file.txt的文件,文件中有如下內容:
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
下面分別用介紹的三種方法來讀取該文件中的所有內容:
# 讀取文本文件
print("*********read方法讀取全部內容**********")
f = open('my_file.txt', encoding='utf-8')
print(f.read())
f.close()
print("*********readline方法讀取全部內容**********")
f = open('my_file.txt', encoding='utf-8')
line_txt = f.readline()
while line_txt:
print(line_txt)
line_txt = f.readline()
f.close()
print("*********readline方法讀取全部內容**********")
f = open('my_file.txt', encoding='utf-8')
print(f.readlines())
運行的結果是:
*********read方法讀取全部內容**********
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
*********readline方法讀取全部內容**********
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
*********readline方法讀取全部內容**********
['全網同名:
', '這是Python系列的第十八篇文章
', 'https://feige.blog.csdn.net/']
一般而言,readline函數和readlines函數用於讀取文本文件,而read函數則即可讀取文本文件又可以讀取非文本文件。
現有文件write_file.txt,文件中有如下兩行內容。
這是Python系列的第十九篇文章
file.write(str): 其中,file表示已經打開的文件對象;str表示要寫入文件的字符串(或字節串,僅適用寫入二進制文件中)
需要注意的是在使用write()向文件中寫入數據,需保證使用open()函數是以r+、w、w+、a或者a+模式打開文件,否則執行write()函數會拋出io.UnsupportedOperation 錯誤。
file = open(‘write_file.txt’, mode=‘w’, encoding=‘utf-8’)
file.write(‘日拱一卒’)
file.close()
通過w模式打開執行write方法寫入日拱一卒之後,文件中原有的內容就被清空了。這裡需要注意的這裡要指定編碼為utf-8,因為在window下文件的默認open函數指定的默認編碼格式是gbk。用utf-8格式打開文件可能會出現亂碼。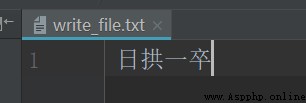
file.writelines(str):
其中,file表示已經打開的文件對象,str表示要寫入文件的內容,可以支持多行數據的寫入。
file = open(‘write_file.txt’, mode=‘w’, encoding=‘utf-8’)
file2 = open(“my_file.txt”, encoding=‘utf-8’)
file.writelines(file2.read())
file.close()
這裡讀取的文件的編碼和寫入的文件編碼需要保持一致。不然,就會報UnicodeDecodeError編碼錯誤。寫入之後會清空文件的原有內容。
創建一個名為my_file.txt的文件,文件有如下內容:
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
通過二進制的方式(rb)打開圖片,針對二進制文件(圖片,視頻等)的話只能使用rb方式來讀取文件。
f = open(‘my_file.txt’, ‘rb’)
f_bytes = f.read()
print(f_bytes)
print(f_bytes.decode(‘utf-8’))
f.close()
運行結果是:
b'??¨??????????????????é£???¥
è????ˉPython?3?????????????????ˉ???????
https://feige.blog.csdn.net/'
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
*********readline方法讀取全部內容**********
全網同名:
這是Python系列的第十八篇文章
以二進制的方式寫入數據
如下代碼就是將圖片demo.jpg的內容寫入到圖片demo1.jpg中,如果demo1.jpg文件不存在則會先創建一個文件。
write_file = open(‘demo1.jpg’, mode=‘wb’)
read_file = open(‘demo.jpg’, mode=‘rb’)
write_file.write(read_file.read())
read_file.close()
write_file.close()
只寫模式追加數據
如下就是在append_file.txt文件中追加好好加油數據,a的話是只寫模式
append_file = open(‘append_file.txt’, mode=‘a’, encoding=‘utf-8’)
append_file.write("
好好加油")
append_file.close()
前面介紹的以w開頭的模式,如果被寫入文件中原有數據則會被覆蓋。如果不想原有數據被覆蓋可以使用追加寫入數據的方式。
讀寫模式下可以調用read()方法進行讀,也可以調用write方法進行寫。
read_write_file = open('append_file.txt', mode='r+', encoding='utf-8')
print(read_write_file.read())
read_write_file.write('
努力向上,天天向上')
print(read_write_file.read())
read_write_file.close()
運行結果是:
全網同名:
這是Python系列的第十八篇文章
https://feige.blog.csdn.net/
需要注意的是read方法只能調用一遍。read函數只能讀取寫入之前的數據,如果要讀取寫入之後的數據需要重新調用open函數。
我們注意文件操作完之後需要手動調用close()方法關閉文件流。實際開發中建議將調用close函數的代碼塊放在finally塊中以防止出現異常導致文件流不能被關閉。標准的使用方式是:
f = open('my_file.txt', encoding='utf-8')
try:
print(f.read())
finally:
f.close()
那麼,有沒有更加便捷的方式呢?答案是有的:那就是通過with as 語句來操作文件。其語法格式是:
with 表達式 [as target]:
代碼塊
此格式中,用[]括起來的部分可以使用,也可以省略。其中,target參數用於指定一個變量,該語句會將表達式指定的結果保存到該變量中。with as 語句中的代碼塊如果不想執行任何語句,可以直接使用 pass 語句代替。
用with as改造上面的代碼就是:
with open('my_file.txt', encoding='utf-8') as f:
print(f.read())
不用手動關閉文件流。
【Python從入門到精通】(十八)Python的文件夾操作,創建文件夾復制文件等等
【Python從入門到精通】(十九)Python對文件的讀寫操作一覽表,非常實用,非常簡單
進程是什麼?進程說白了就是應用程序的執行實例。你在電腦上聽著歌兒,敲著代碼,掛著微信。這些任務都是由不同的應用程序來執行。操作系統會給每個應用程序分配不同的進程。通過CPU的調度來使這些動作可以“同時”進行,這裡說是同時進行實際上不是的,因為CPU在同一時間內只能有一條指令執行,但是因為CPU執行的速度太快了,給用戶的感覺就是在同時進行。進程是可以占用物理內存的。
線程是進程的組成部分,一個進程可以擁有多個線程.CPU調度進程的最小粒度是線程。其中由主線程來完成從開始到結束的全部操作。其他線程在主線程運行時被創建或者結束。
主線程在程序初始化之後就會被創建。如果一個程序只有一個主線程就稱為單線程,如果有多個線程則稱之為多線程。 創建多個線程之後,每個線程的執行都是獨立的。
Python創建線程的方式有兩種: 創建線程都需要引入threading模塊。首先讓我們來看看Thread類的構造方法。
__init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
此構造方法中,以上所有參數都是可選參數,即可以使用,也可以忽略。
其中各個參數的含義如下:
group:指定所創建的線程隸屬於哪個線程組。
target:指定所創建的線程要調用的目標方法。
args:以元組的方式,為target指定的方法傳遞參數,如果傳入的是元組中有多個參數的話則傳入方式是(arg1,arg2,....argn,)
kwargs:以字典的方法,為target指定的方法傳遞參數。
daemon:指定所創建的線程是否為後台線程。
name: 指定線程的名稱
第一種方式:就是直接調用Thread類的構造方法創建一個線程的實例。
import threading
def async_fun(*add):
for arc in add:
print(threading.current_thread().getName() + " " + arc)
my_tuple = (“”, “好好學習”, “早日突破職業瓶頸”)
thread = threading.Thread(target=async_fun, args=my_tuple)
thread.start()
for i in range(4):
print(threading.current_thread().getName() + “執行” + str(i)+ “次”)
運行結果是:
Thread-1 MainThread執行0次
MainThread執行1次
MainThread執行2次
MainThread執行3次
Thread-1 好好學習
Thread-1 早日突破職業瓶頸
如上方法就是實例化一個線程Thread-1讓他異步調用async_fun方法。可以看出主線程MainThread和線程Thread-1是交替調用的(每次的執行結果都不同)。這說明了這兩個線程是交替獲得CPU的執行權限的。需要特別注意的是線程必須要調用start()方法才能執行。
2. 第二種方式:就是繼承threading.Thread。然後,重寫run方法。
import threading
class MyThread(threading.Thread):
def __init__(self, add):
threading.Thread.__init__(self)
self.add = add
# 重寫run()方法
def run(self):
for arc in self.add:
print(threading.current_thread().getName() + " " + arc)
my_tuple = ("", "好好學習", "早日突破職業瓶頸")
thread = MyThread(my_tuple)
thread.start()
for i in range(4):
print(threading.current_thread().getName() + "執行" + str(i)+ "次")
運行結果是:
Thread-1 MainThread執行0次
MainThread執行1次
Thread-1 好好學習
Thread-1 早日突破職業瓶頸
MainThread執行2次
MainThread執行3次
這裡定義了了MyThread類,並重寫了run方法。run方法就是線程真正要執行的任務。相當於上例中async_fun函數的內容移到了run方法中。
說完了如何創建一個線程接下來讓我們來看看線程的生命周期。一個線程一共有五個狀態。
分別是新建狀態(初始化狀態),就緒狀態,運行狀態,阻塞狀態以及死亡狀態。狀態之間的關系圖如下: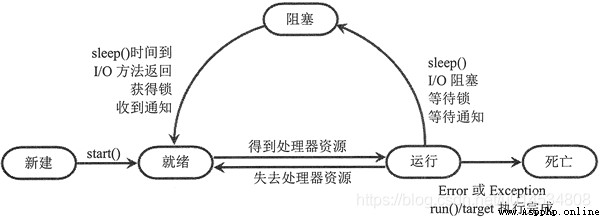
join()方法的功能是在程序指定位置,優先讓該方法的調用者使用CPU資源,即調用線程等待該線程完成後,才能繼續用下運行。
該方法的語法格式如下:thread.join( [timeout])
其中,thread為Thread類或其子類的實例化對象;timeout參數作為可選參數,
其功能是指定thread線程最多可以霸占CPU資源的時間,如果省略,則默認直到thread執行結束才釋放CPU資源。
import threading
# 定義線程要調用的方法
def async_fun(*add):
for arc in add:
print(threading.current_thread().getName() + " " + arc)
my_tuple = ("", "好好學習", "早日突破職業瓶頸")
# 創建線程
thread = threading.Thread(target=async_fun, args=my_tuple, name="線程1")
thread2 = threading.Thread(target=async_fun, args=my_tuple, name='線程2')
# 啟動線程
thread.start()
# 等待線程1執行完
thread.join()
# 線程1執行完之後啟動線程2
thread2.start()
thread2.join()
運行結果是:
線程1
線程1 好好學習
線程1 早日突破職業瓶頸
線程2
線程2 好好學習
線程2 早日突破職業瓶頸
如上有線程1和線程2兩個線程。在線程1調用thread.join()之後線程1和線程2的執行由並行改成了串行。也就是說必須是線程1執行完之後才啟動線程2。現在把該語句去掉變成下面這樣:
# 啟動線程
thread.start()
# 線程1執行完之後啟動線程2
thread2.start()
thread2.join()
運行結果是:
線程1
線程2
線程2 好好學習
線程2 早日突破職業瓶頸
線程1 好好學習
線程1 早日突破職業瓶頸
可以看出線程1和線程2的運行是並行的。
位於time模塊中的sleep(secs)函數,可以實現令當前執行的線程暫停secs秒後在繼續執行,所謂暫停,即令當前線程進入阻塞狀態,當達到sleep()函數規定的時間後,
再由阻塞狀態轉為就緒狀態,等待CPU調度。
# 定義線程要調用的方法
def async_fun(*add):
for arc in add:
start_time = time.time()
time.sleep(2)
print(str((time.time() - start_time)) + " 秒 " + threading.current_thread().getName() + " 結束調用" + arc)
my_tuple = ("", "好好學習", "早日突破職業瓶頸")
# 創建線程
thread = threading.Thread(target=async_fun, args=my_tuple)
# 啟動線程
thread.start()
運行結果是:
2.0052337646484375 秒 Thread-1 結束調用
2.004210948944092 秒 Thread-1 結束調用好好學習
2.002394199371338 秒 Thread-1 結束調用早日突破職業瓶頸
可以看出線程每次執行都花費了2秒的時間。
【Python從入門到精通】(二十)Python並發編程的基本概念-線程的使用以及生命周期
前面幾篇文章介紹的線程都是直接通過代碼手動創建的線程。線程執行完任務之後就會被系統銷毀,下次再執行任務的時候再進行創建。這種方式在邏輯上沒有啥問題。但是系統啟動一個新線程的成本是比較高,因為其中涉及與操作系統的交互,操作系統需要給新線程分配資源。打個比方吧!就像軟件公司招聘員工干活一樣。當有活干時,就招聘一個外包人員干活。當活干完之後就把這個人員辭退掉。你說在這過程中所耗費的時間成本和溝通成本是不是很大。那麼公司一般的做法是:當項目立項時就確定需要幾名開發人員,然後將這些人員配齊。然後這些人員就常駐在項目組,有活就干,沒活就摸魚。線程池也是同樣的道理。線程池可以定義最大線程數,這些線程有任務就執行任務,沒任務就進入線程池中歇著。
線程池的基類是concurrent.futures模塊中的Executor類,而Executor類提供了兩個子類,即ThreadPoolExecutor類和ProcessPoolExecutor類。其中ThreadPoolExecutor用於創建線程池,而ProcessPoolExecutor用於創建進程池。本文將重點介紹ThreadPoolExecutor類的使用。首先,讓我們來看看ThreadPoolExecutor類的構造函數。這裡使用的Python版本是:3.6.7。
def __init__(self, max_workers=None, thread_name_prefix=''):
"""Initializes a new ThreadPoolExecutor instance.
Args:
max_workers: The maximum number of threads that can be used to
execute the given calls.
thread_name_prefix: An optional name prefix to give our threads.
"""
if max_workers is None:
# Use this number because ThreadPoolExecutor is often
# used to overlap I/O instead of CPU work.
max_workers = (os.cpu_count() or 1) * 5
if max_workers <= 0:
raise ValueError("max_workers must be greater than 0")
self._max_workers = max_workers
self._work_queue = queue.Queue()
self._threads = set()
self._shutdown = False
self._shutdown_lock = threading.Lock()
self._thread_name_prefix = (thread_name_prefix or
("ThreadPoolExecutor-%d" % self._counter()))
他的構造函數只有兩個參數:一個是max_workers參數,用於指定線程池的最大線程數,如果不指定的話則默認是CPU核數的5倍。另一個參數是thread_name_prefix,它用來指定線程池中線程的名稱前綴。其他參數:
_shutdown初始值值為False,默認情況下線程池不銷毀,即線程池的生命周期跟項目的生命周期一致。self._work_queue = queue.Queue()生成緩沖隊列。_threads沒有任務被提交時,線程的數量設置為0。_shutdown_lock 指定線程池的鎖是Lock鎖。submit(self, fn, *args, **kwargs):*args代表傳給fn函數的參數,**kwargs代表以關鍵字參數的形式為fn函數傳入參數。shutdown(self, wait=True):map(func, *iterables, timeout=None, chunksize=1):map(func,*iterables),只是該函數將會啟動多個線程,以異步方式立即對iterables執行map處理。程序將task函數通過submit方法提交給線程池之後,線程池會返回一個Future對象,該對象的作用主要是用於獲取線程任務函數的返回值。Future提供了如下幾個方法。
cancel():取消該Future代表的線程任務。如果該任務正在執行,不可取消,則該方法返回False;否則,程序會取消該任務,並返回True。result(timeout=None):獲取該 Future 代表的線程任務最後返回的結果。如果 Future 代表的線程任務還未完成,該方法將會阻塞當前線程,其中 timeout 參數指定最多阻塞多少秒。add_done_callback(fn):為該 Future 代表的線程任務注冊一個“回調函數”,當該任務成功完成時,程序會自動觸發該 fn 函數。done():如果該Future代表的線程任務被成功取消或執行完成,則該方法返回True。該例中創建了一個最大線程數是2的線程池來執行async_add函數。
from concurrent.futures import ThreadPoolExecutor
import threading
import time
def async_add(max):
sum = 0
for i in range(max):
sum = sum + i
time.sleep(1)
print(threading.current_thread().name + "執行求和操作求得的和是=" + str(sum))
return sum
# 創建兩個線程
pool = ThreadPoolExecutor(max_workers=2, thread_name_prefix='測試線程')
# 向線程池提交一個task,20作為async_add()函數的參數
future1 = pool.submit(async_add, 20)
# 向線程池再提交一個task
future2 = pool.submit(async_add, 50)
# 判斷future1代表的任務是否執行完
time.sleep(2)
print(future1.done())
print(future2.done())
# 查看future1代表的任務返回的結果
print('線程一的執行結果是=' + str(future1.result()))
# 查看future2代表的任務的返回結果
print('線程二的執行結果是=' + str(future2.result()))
print("----" + threading.current_thread().name + "----主線程執行結束-----")
運行結果是:
測試線程_0執行求和操作求得的和是=190
測試線程_1執行求和操作求得的和是=1225
True
True
線程一的執行結果是=190
線程二的執行結果是=1225
----MainThread----主線程執行結束-----
本例中定義了一個最大線程數是2的線程池,並向線程池中提交了兩個任務,其中async_add函數就是要執行的任務。在async_add函數中添加 time.sleep(1) 休眠一秒是為了驗證done()方法返回的結果。最後才打印主線程執行結束表明result()方法是阻塞的。如果將result()屏蔽掉。
改成如下形式:
# 創建兩個線程
pool = ThreadPoolExecutor(max_workers=2, thread_name_prefix='測試線程')
# 向線程池提交一個task,20作為async_add()函數的參數
future1 = pool.submit(async_add, 20)
# 向線程池再提交一個task
future2 = pool.submit(async_add, 50)
# 判斷future1代表的任務是否執行完
print(future1.done())
print(future2.done())
print("----" + threading.current_thread().name + "----主線程執行結束-----")
則運行結果是:
False
False
----MainThread----主線程執行結束-----
測試線程_0執行求和操作求得的和是=190
測試線程_1執行求和操作求得的和是=1225
詳情可以查看
【Python從入門到精通】(二十二)Python線程池的正確使用姿勢
PIL庫 Python Imaging Library,已經是Python平台事實上的圖像處理標准庫了。PIL功能非常強大,但API卻非常簡單易用。但是PIL庫僅僅支持到Python 2.7。為了兼容Python 3.x開源社區提供了兼容版本Pillow,通過Pillow大家就可以愉快的在Python 3.x上使用PIL庫了。
通過pip命令安裝Pillow還是非常方便的,一行命令就可以
安裝最新版本的命令
pip install Pillow
安裝指定版面的命令pip install Pillow=={version} 這裡的version需要替換成指定的版本號,比如要下載8.3.0版本。
pip install Pillow==8.3.0
如果你不知道有哪些版本可以通過pip install Pillow== 進行查看。
下表是Pillow與Python的版本對應表。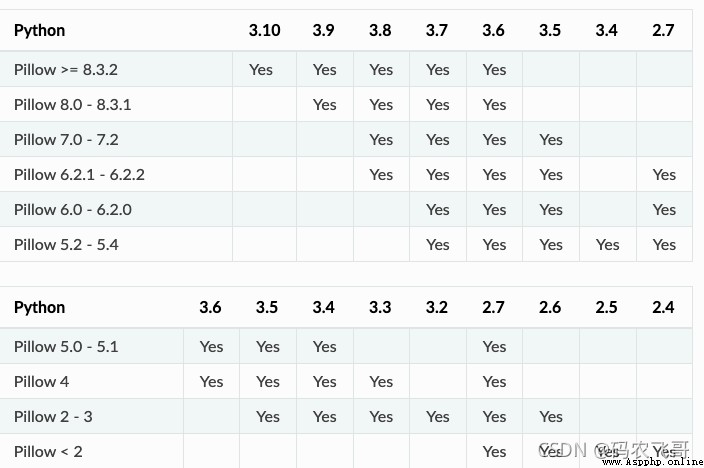
PIL庫有很多模塊,這裡重點介紹一些常用的模塊。首先,總體來看下各個模塊的作用。
模塊名
主要作用
Image
Image模塊提供了一個具有相同名稱的類用於表示PIL的image對象,它有許多工廠類,包括從文件中加載image以及創建新的image
ImageColor
ImageColor 模塊包含了CSS3中的顏色說明符到RGB元組的顏色表和轉換器,這個模塊在PIL.Image.new()和ImageDraw模塊以及其他模塊使用
ImageFont
ImageFont 用於設置字體,它主要用在PIL.ImageDraw.ImageDraw.text() 方法中。
ImageDraw
ImageDraw 模塊為Image模塊提供了簡單的2D圖形,利用該模塊可以創建新圖形,修飾現有圖形,然後生成新的圖形以供使用
下面就詳細介紹下各個模塊的
Image是PIL庫的核心模塊,大部分圖片的操作都離不開它,利用它可以從文件中加載image,以及創建新的image。以及將Images保存為圖片。
加載圖片文件
PIL.Image.open(fp, mode=‘r’, formats=None)
其中 fp是圖片文件名稱,mode 表示圖片路徑的讀取模式,默認是’r’模塊。返回Image對象
try:
img = Image.open("img1.jpeg")
finally:
# 這種打開方式需要手動關閉文件流
img.close()
這裡Image使用完成之後需要手動關閉。比較推薦下面的with … as … 的寫法
with Image.open('img1.jpeg') as img:
下面列舉的img都是前面通過open獲取到的Image對象。
2. 獲取圖片的寬,高。通過img.size 可以獲取圖片的寬,高。i
width, height = img.size
展示圖片show()
img.show()
圖片旋轉,通過rotate方法對圖片進行旋轉,下面就是將圖片旋轉45度展示出來。
img.rotate(45).show()
圖片縮放,通過thumbnail方法可以實現對圖片的縮放。
img.thumbnail((width / 2, height / 2))
保存圖片
save(self, fp, format=None, **params)
該方法可以將Image對象保存為一個圖片文件。其中:fp為圖片保存的路徑。**params是可變參數,一般是傳入圖片的後綴名。
img.save('thumbnail.jpeg')
創建新Image
PIL.Image.new(mode, size, color=0)
該方法有三個參數,mode用於指定生成的圖片是RGB還是RGBA。這裡RGBA各個字母表示的意思是:r 表示red, g 表示gree, b表示blue,a 表示alpha 透明度。一般而言只需要指定RGB即可。如果需要創建一個透明底的圖片則需要傳入RGBA。
size 用於指定圖片的寬高,傳入的是一個元組。
color 用於指定圖片的顏色,如果前面mode傳入的是RGB的話,則該參數需要傳入含有三個元素的元組。比如:(255, 0, 0),如果前面mode傳入的是RGBA的話,則該參數需要傳入含有四個元素的元素,比如:(255,0,0,204)。
下面的代碼就是創建一個寬高各為500的,背景色是紅色的圖片。
newImg = Image.new('RGB', (500, 500), (255, 0, 0))
newImg.save('newImg.png')
復制圖片,通過copy()方法,可以copy一個圖片。
copyImg = img.copy()
newImg.save(op.join(base_path, ‘copyImg.png’))
粘貼圖片:通過 paste方法可以將一個圖片粘貼到另一個圖片之上。
該模塊主要是從CSS3中的顏色說明符中獲取到RGB值。這裡說一個方法:getrgb 方法就是獲取RGB值。
# 獲取顏色的RBGA值
rgb_tup = ImageColor.getrgb("#ff0000cc")
print(rgb_tup)
運行結果是(255, 0, 0, 204)
ImageFont 用於設置字體,它主要用在PIL.ImageDraw.ImageDraw.text() 方法中。首先,這裡介紹其最常用的方法
PIL.ImageFont.truetype (font = None , size = 10 , index = 0 , encoding = '' , layout_engine = None )
從文件或類文件對象加載 TrueType 或 OpenType 字體,並創建字體對象。該函數從給定的文件或類文件對象加載一個字體對象,並為給定大小的字體創建一個字體對象。
Pillow 使用 FreeType 打開字體文件。如果您在 Windows 上同時打開多種字體,請注意 Windows 將可以在 C 中同時打開的文件數限制為 512。如果接近該限制,OSError可能會拋出an ,報告 FreeType“無法打開資源”。
此功能需要 _imagingft 服務。
參數
font – 包含 TrueType 字體的文件名或類似文件的對象。如果在此文件名中找不到該文件,加載程序也可能會在其他目錄中進行搜索,例如fonts/ Windows 或 上的目錄/Library/Fonts/, /System/Library/Fonts/以及~/Library/Fonts/macOS上的目錄。
size – 請求的大小,以磅為單位。
index – 要加載的字體(默認是第一個可用的字體)。
encoding—要使用的字體編碼(默認為 Unicode)。可能的編碼包括(有關更多信息,請參閱 FreeType 文檔):
這指定要使用的字符集。它不會改變後續操作中提供的任何文本的編碼。
layout_engine 要使用的布局引擎(如果可用): ImageFont.LAYOUT_BASIC或ImageFont.LAYOUT_RAQM.
返回值
一個字體對象。
img_font = ImageFont.truetype('simsun.ttf', size=20)
這裡代碼的意思是創建一個字體大小為20的宋體的字體。
終於說到ImageDraw模塊了,這個模塊也是一個非常重要的模塊,它主要是可以給圖片添加文字以及劃線等。
Draw方法
PIL.ImageDraw.Draw(im, mode=None)
給指定的Image對象創建一個draw對象。
參數:
im: 需要被繪畫的image對象
mode: 用於顏色值的可選模式,對於RGB圖像,此參數可以是RGB或者RGBA(將繪圖混合到圖像中)。對於所有其他模式,此參數必須與圖像模式相同,如果省略,模式默認是圖像的模式。
2. text方法
ImageDraw.text(xy, text, fill=None, font=None, anchor=None, spacing=4, align='left', direction=None, features=None, language=None, stroke_width=0, stroke_fill=None, embedded_color=False)
在給定的位置上添加文本
參數:
xy – 文本的錨點坐標。
text – 要繪制的字符串。如果它包含任何換行符,則文本將傳遞給 multiline_text()。
fill- 用於文本的顏色。
font- 一個ImageFont實例。
anchor—— 文本錨對齊方式。確定錨點與文本的相對位置。默認對齊方式是左上角。有關有效值,請參閱文本錨點。對於非 TrueType 字體,將忽略此參數。
此參數存在於 Pillow 的早期版本中,但僅在 8.0.0 版中實現。
spacing– 如果文本傳遞到multiline_text(),則為 行之間的像素數。
align- 如果文本被傳遞到 multiline_text(), “left”,“center"或"right”。確定線條的相對對齊方式。使用anchor參數指定對齊到xy。
direction——文本的方向。它可以是"rtl"(從右到左)、“ltr”(從左到右)或"ttb"(從上到下)。需要 libraqm。
features—— 要在文本布局期間使用的 OpenType 字體功能列表。這通常用於打開默認情況下未啟用的可選字體功能,例如"dlig"或"ss01",但也可用於關閉默認字體功能,例如"-liga"禁用連字或"-kern" 禁用字距調整。要獲取所有支持的功能,請參閱OpenType 文檔。需要 libraqm。
language—— 文本的語言。不同的語言可能使用不同的字形形狀或連字。此參數告訴字體文本使用的語言,並根據需要應用正確的替換(如果可用)。它應該是BCP 47 語言代碼。需要 libraqm。
stroke_width–文本筆劃的寬度。
stroke_fill – 用於文本筆劃的顏色。如果沒有給出,將默認為fill參數。
embedded_color– 是否使用字體嵌入顏色字形(COLR、CBDT、SBIX)。8.0.0 版中的新功能。
# 給圖片上添加文字
with Image.open(op.join(base_path, 'img4.jpeg')) as im:
font = ImageFont.truetype(op.join(base_path, 'simsun.ttf'), size=80)
rgb_tup = ImageColor.getrgb("#ff0000cc")
draw = ImageDraw.Draw(im)
text = "瑪莎拉蒂"
draw.text((650, 550), text, fill=rgb_tup, font=font)
im.save(op.join(base_path, '瑪莎拉蒂.png'), 'png')
運行結果是:
現在有這兩張美女照片分別是:img2.jpeg和img3.png。我想把img3.png粘貼到img2.jpeg上。該如何操作呢 其中img3.png還是透明底的。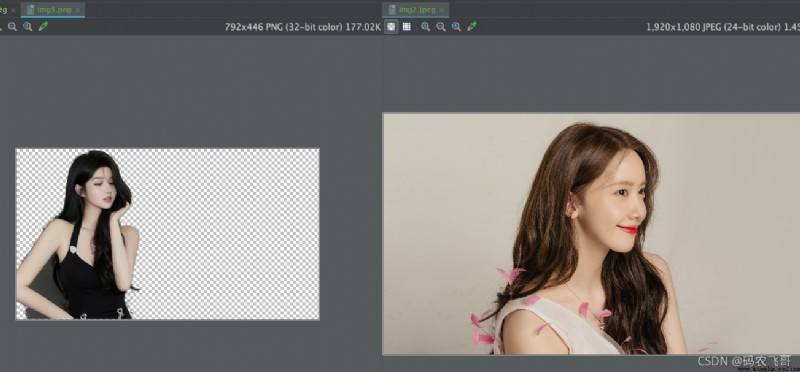
直接上paste方法
img2 = Image.open(‘img2.jpeg’)
img3 = Image.open(‘img3.png’)
img2.paste(img3)
img2.save(‘beautiful_paste.jpeg’)
運行結果是:
img3.png 圖片粘貼到img2上之後背景色變成了黑色,這顯然沒有達到我們期望的結果。這該如何處理呢?
問題不大,只需要小小的修改一下代碼.
3. 小小修改一下,將背景改成透明底
# 透明底
img2 = Image.open('img2.jpeg').convert('RGBA')
img3 = Image.open('img3.png').convert('RGBA')
# 獲取r,g,b,a的值
r, g, b, a = img3.split()
# 傳入透明值
img2.paste(img3, box=(0, 0), mask=a)
img2.save('beautiful_paste2.png')
運行結果是:
這下就變成了透明底了。兩位美女都可以盡情欣賞了。
詳細內容可以查看
??【Python從入門到精通】(二十六)用Python的PIL庫(Pillow)處理圖像真的得心應手??
??【Python從入門到精通】(二十七)更進一步的了解Pillow吧!
至此Python的基礎內容已經全部介紹完了。
干貨太多,編輯器都有點卡頓了。
還是那句話,收藏下來邁出了學習的第一步。
B站的小姐姐看一千遍還是別人的,C站的文章看一遍就是自己的了。
干貨握在手,妹子跟你走。
為了更好幫助更多的小伙伴對Python從入門到精通,我從CSDN官方那邊搞來了一套 《Python全棧知識圖譜》,尺寸 870mm x 560mm,展開後有一張辦公桌大小,也可以折疊成一本書的尺寸,有興趣的小伙伴可以了解一下------掃描下圖中的二維碼即可購買。
我本人也已經用上了,感覺非常好用。圖譜桌上放,知識心中留。
我是,再次感謝您讀完本文。
需要源碼的小伙伴關注下方公眾號,回復【python】
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦