聲明:本文為學習筆記,侵權刪
CART(Classification And Regression Tree - 分類/回歸樹)is one of the decision tree algorithms,依靠基尼系數進行分類.The Gini coefficient describes the:drawn at random from a system兩個樣本,The probability of the two samples is not the same.概率越大,基尼系數越大,On the contrary, the smaller the Gini coefficient.基尼系數越小(即:Take almost no different,That is basically the same,It is easy to distinguish the different ones),The higher the degree of system differentiation of the system,It is also more suitable for classification prediction.
基尼系數公式:
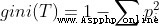
T是樣本空間
piis the proportion of each class in the total sample in the sample space
即:基尼指數是1Subtract the sum of the squares of the proportions of each class
If there is a sample spaceT,通過某種規則,分為了T1,T2two subsample spaces,這是gini(T)的公式:
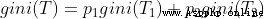
p1,p2分別是T1,T2total sample spaceT的比例.比如T1樣本數=200,T2樣本數=300,T樣本數=500.則p1=0.4,p2=0.6
This formula can also be extended to3,4個...The case of multiple subsample spaces.
決策樹分為分類決策樹和回歸決策樹,More on classification decision trees here.
Classification decision tree tree is used to process離散型數據,That is, data with limited types of data,it outputs the sample類別.
Regression tree is used to process連續型數據,That is, the value of the data in a certain range,輸出是一個數值.
sklearnThe decision tree will automatically try to split the decision tree and regression and tie-in combination of various kinds of the root node,Find the one with the smallest Gini coefficient,and use this as a basis for classification.The decision tree calculates the probability that the data belongs to each class separately,Find the class with the highest probability,The data will be classified into this category.
例如,Here are some users' liking for different movies,0do not like,1是喜歡.評判標准為{劇情,演技}.顯然,這裡只有0,1兩種情況,是離散的數據,So want to judge whether the user likes the movie,需要用的是分類決策樹.
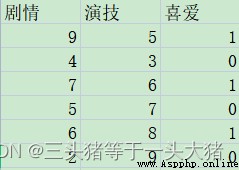
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
data = pd.read_csv(r"D:\Python Code\dataMining\電影.csv",encoding="GBK")
#Plot and acting are independent variables,Like or not is a dependent variable
x=data[["劇情","演技"]]
y=data["喜愛"]
#generates a depth of2的樹
model = DecisionTreeClassifier(max_depth=2,random_state=1)
model.fit(x,y)
#預測4Is this movie popular?.in each list,The previous one is the plot,The latter is acting
pre=model.predict([[8,6],[6,8],[6,7],[4,8]])
print(pre)
輸出:
[1 1 1 0]If the data is slightly more complex,Can also manually adjust the depth of the tree(Also calculated hereThe correct rate of model predictions):
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = pd.read_csv(r"D:\Python Code\dataMining\電影.csv",encoding="GBK")
#Change the data in the age column of the dataset to numeric values,便於處理
data["年齡"] = data["年齡"].replace({"輕":0,"中":1,"高":2})
x=data.drop(columns = "喜愛")
y=data["喜愛"]
#劃分訓練集與驗證集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=1)
#generates a depth of3的樹
model = DecisionTreeClassifier(max_depth=3,random_state=1)
model.fit(x_train,y_train)
#Find the correctness of the model
y_pred = model.predict(x_test)
score = accuracy_score(y_pred,y_test,normalize=True)#normalize = True,返回正確分類的比例, false返回正確分類的樣本數
print(score) #輸出:1.0 評分滿分,Mainly because my dataset is too small,If it is a large data set, this is basically not the case.前面提到,Decision tree classification is actually to calculate the probability that a data belongs to each class,Find the class with maximum probability.Is that we can see that the probability of each data belonging to each category:
probability = model.predict_proba(x_test)
print(probability)
#print(probability[:,1]) 一個小知識點:Read the complete data of a column of a two-dimensional list, Here is the second column read
輸出:
[[0. 1.]
[1. 0.]]
The left column of the output is classified as0(不喜歡),右列是分類為1(喜歡).
All the test includes two sets of data,第一組:0的概率為0, 1的概率為1.
or the dataset is too small,If the data set is larger, it may be:0的概率是0.1,1的概率是0.9Three concepts are needed hereTPR,FPR,ROC,AUC,可以百度一下,Very understandable~
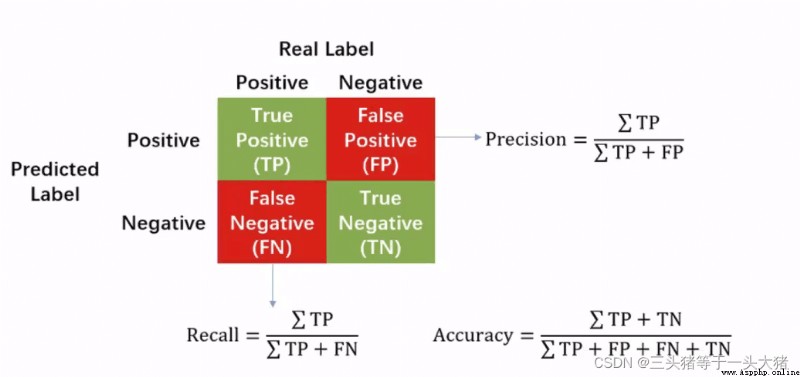
一般在二分類These concepts are used in the problem.
在本例中,Departure forpositive,Not resigned asnegative.for a better presentation,Here is a set of more complex datasets:
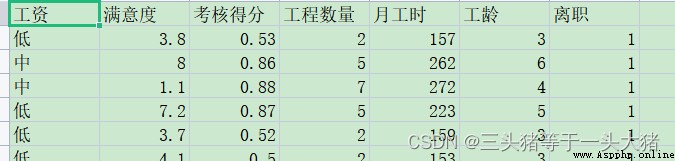
計算tpr,fpr.(The rest is the same as the example above)
#計算tpr,fpr,thres 其中thres是threshol的意思,是一個阈值,Probability is greater than the threshold value can be classified aspositive
fpr,tpr,thres = roc_curve(y_test,probability[:,1]) #Because in this case the dismissal(1)為positive
print(fpr)
print(tpr)
print(thres)輸出:

What does this output mean??Take the data in the red box as an example:最下面的0.7129...是阈值,即:The predicted probability of leaving is greater than0.7129was sentenced to resignation,此時fpr=0.032,tpr=0.928.根據得到的fpr,tpr就可以畫出ROC曲線:
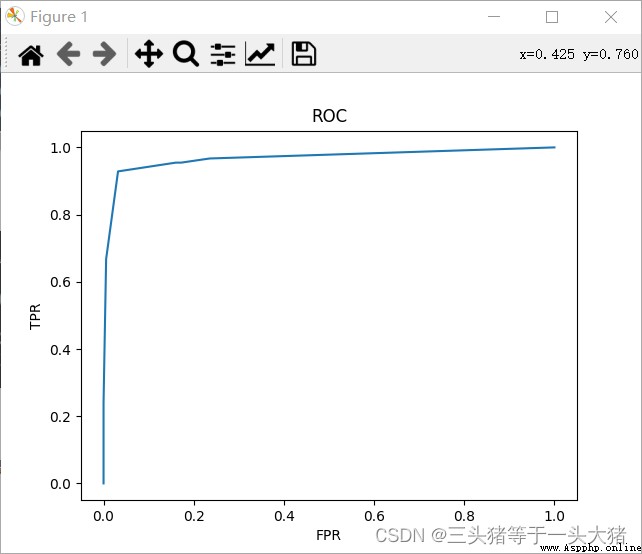
簡單來說,ROC曲線越陡峭,模型越好,或者說,ROC曲線下的面積越大,模型越好,But this can only be qualitatively analyzed,判定ROCThere are special rules for judging the pros and cons of the curve:AUC值(In fact, the area under the curve)
AUC = 0.5~0.7 效果較差
AUC = 0.7~0.85 效果較好
AUC = 0.85~1 效果很好
#計算AUC
from sklearn.metrics import roc_auc_score
AUC = roc_auc_score(y_test,probability[:,1])
print(AUC) #0.9684401481001393關於KThe concept of fold cross-validation,可以看這裡.
注意:If the dataset is small,可以適當提高K值,Ensuring that there is enough data for training at each iteration.If the dataset is large,可適當減小K值,Reduce program running costs.
#計算K折交叉驗證
#scoring="roc_auc"代表以ROC曲線的AUCvalue as a scoring criterion
#cv=5 代表這是5折交叉驗證(默認為3折交叉驗證)
#The result is a length of5的列表
AUC_score = cross_val_score(model,x_train,y_train,scoring="roc_auc",cv=5)
print(AUC_score) 輸出[0.95820899 0.9693086 0.961101 0.96984419 0.9672071 ]
print(AUC_score.mean()) 輸出0.9651339760890151通過KThe test results obtained by folded cross-validation are only once compared to the previous onesAUC值更為准確.同時,KFold cross-validation is also often used withGridsearch網格搜索配合使用.
What is grid search?是一個以KFold cross-validation as an enumeration mechanism for selecting the best parameters for the underlying logic.用大白話說,Just tell the machine what parameters I want to choose,and in what range.Then the machines are brought in one by one to try,At the same time, it will provide a judgment standard for the machine(such as the highest standardAUC的值),to find the best parameters.
舉個例子就是:
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=1)
#Gridsearch
model = DecisionTreeClassifier()
#Need to select the parameters to input through the dictionary formatGridsearch
try_param = {"max_depth":[1,2,3,4,5,6,7,8,9]}
from sklearn.model_selection import GridSearchCV
#scoring Determine selection criteria
grid_search = GridSearchCV(model,try_param,scoring="roc_auc",cv=5)
grid_search.fit(x_train,y_train)
best_param = grid_search.best_params_
print(best_param)
輸出:{'max_depth': 7}
Here I want to know the maximum depth of the tree classification is the best,評價標准是auc, 然後創建一個Gridsearch的模型,Just let him run.will eventually get the best value.但Gridsearch有個缺陷就是:Only the best value within a limited range can be found,比如,萬一max_depth=11Time effect than7的時候要好,By this method it is not possible to obtainmax_depth=11.
當然,這裡輸出max_depth=7效果最好,那麼就可以用max_depth=7Build a classification decision tree,Then the next steps are very normal.