聲明:本文為學習筆記,侵權刪
CART(Classification And Regression Tree - 分類/回歸樹)是決策樹算法的其中一種,依靠基尼系數進行分類。基尼系數描述的是:從一個系統中隨機抽取兩個樣本,這兩個樣本不同類的概率。概率越大,基尼系數越大,反之基尼系數越小。基尼系數越小(即:幾乎取不到不一樣的,也就是說基本上都是一樣的,那不同類的那個就容易被區分出來),系統的系統區分度越高,也就越適合做分類預測。
基尼系數公式:
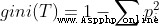
T是樣本空間
pi是該樣本空間中每一個類所占總樣本的比例
即:基尼指數是1減去各個類所占比例的平方和
如果有一個樣本空間T,通過某種規則,分為了T1,T2兩個子樣本空間,這是gini(T)的公式:
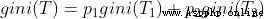
p1,p2分別是T1,T2所占總樣本空間T的比例。比如T1樣本數=200,T2樣本數=300,T樣本數=500。則p1=0.4,p2=0.6
這個公式也可以推廣到3,4個...多個子樣本空間的情況。
決策樹分為分類決策樹和回歸決策樹,這裡更多討論分類決策樹。
分類決策樹樹用來處理離散型數據,也就是數據種類有限的數據,它輸出的是樣本的類別。
回歸樹用來處理連續型數據,也就是數據在某段區間內的取值,輸出是一個數值。
sklearn中的分裂決策樹和回歸決策樹會自動嘗試各種根節點的搭配組合,找到基尼系數最小的一種,並以此作為分類的依據。決策樹分別計算數據屬於每一類的概率,找到概率最大的一類,這個數據就會被分到這一類。
例如,這裡有一部分用戶對不同電影的喜愛程度,0是不喜歡,1是喜歡。評判標准為{劇情,演技}。顯然,這裡只有0,1兩種情況,是離散的數據,因此想要判斷用戶是否喜歡電影,需要用的是分類決策樹。
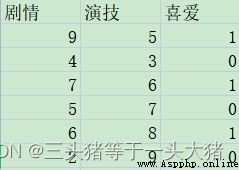
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
data = pd.read_csv(r"D:\Python Code\dataMining\電影.csv",encoding="GBK")
#劇情與演技是自變量,喜愛與否是因變量
x=data[["劇情","演技"]]
y=data["喜愛"]
#生成一個深度為2的樹
model = DecisionTreeClassifier(max_depth=2,random_state=1)
model.fit(x,y)
#預測4種電影是否受歡迎。每個列表中,前一項是劇情,後一項是演技
pre=model.predict([[8,6],[6,8],[6,7],[4,8]])
print(pre)
輸出:
[1 1 1 0]如果數據稍微復雜一些,也可以手動調整一下樹的深度(這裡還計算了模型預測的正確率):
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = pd.read_csv(r"D:\Python Code\dataMining\電影.csv",encoding="GBK")
#把數據集中年齡這一列的數據改為數值,便於處理
data["年齡"] = data["年齡"].replace({"輕":0,"中":1,"高":2})
x=data.drop(columns = "喜愛")
y=data["喜愛"]
#劃分訓練集與驗證集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=1)
#生成一個深度為3的樹
model = DecisionTreeClassifier(max_depth=3,random_state=1)
model.fit(x_train,y_train)
#求模型的正確率
y_pred = model.predict(x_test)
score = accuracy_score(y_pred,y_test,normalize=True)#normalize = True,返回正確分類的比例, false返回正確分類的樣本數
print(score) #輸出:1.0 評分滿分,主要是因為我的數據集太小了,如果是大的數據集就基本上不會有這種情況了前面提到,決策樹分類其實是計算一個數據屬於各個類的概率,找到最大概率的類。我們其實是可以看到每個數據屬於每一類的概率的:
probability = model.predict_proba(x_test)
print(probability)
#print(probability[:,1]) 一個小知識點:讀取二維列表的某一列的完整數據, 這裡讀的是第二列
輸出:
[[0. 1.]
[1. 0.]]
輸出的左列是分類為0(不喜歡),右列是分類為1(喜歡)。
這裡的測試總共包含兩組數據,第一組:0的概率為0, 1的概率為1。
還是數據集太小導致的,數據集大一點的話可能就是:0的概率是0.1,1的概率是0.9這裡需要三個概念TPR,FPR,ROC,AUC,可以百度一下,挺好理解的哈~
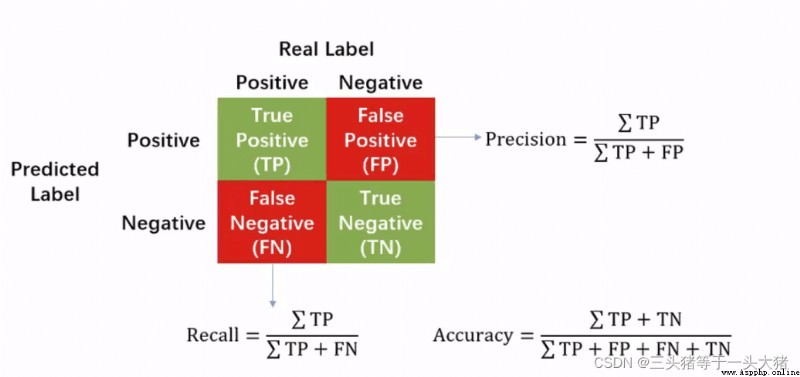
一般在二分類問題中都會用到這些概念。
在本例中,離職為positive,未離職為negative。為了更好得演示,這裡換一組更復雜的數據集:
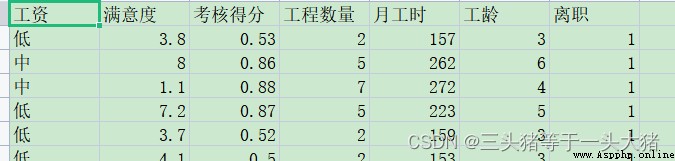
計算tpr,fpr。(其余部分和上面的例子一樣)
#計算tpr,fpr,thres 其中thres是threshol的意思,是一個阈值,概率大於該阈值的時候才能分類為positive
fpr,tpr,thres = roc_curve(y_test,probability[:,1]) #因為本例中取離職(1)為positive
print(fpr)
print(tpr)
print(thres)輸出:

這個輸出是啥意思呢?以紅色框框裡的數據為例:最下面的0.7129...是阈值,即:預測離職的概率大於0.7129的時候被判為離職,此時fpr=0.032,tpr=0.928。根據得到的fpr,tpr就可以畫出ROC曲線:
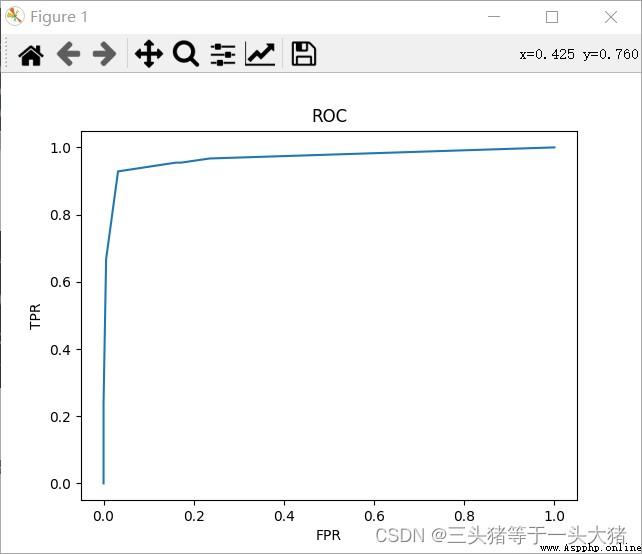
簡單來說,ROC曲線越陡峭,模型越好,或者說,ROC曲線下的面積越大,模型越好,但這只能定性分析,判定ROC曲線的優劣有專門的判定規則:AUC值(其實就是曲線下面積)
AUC = 0.5~0.7 效果較差
AUC = 0.7~0.85 效果較好
AUC = 0.85~1 效果很好
#計算AUC
from sklearn.metrics import roc_auc_score
AUC = roc_auc_score(y_test,probability[:,1])
print(AUC) #0.9684401481001393關於K折交叉驗證的概念,可以看這裡。
注意:若數據集較小,可以適當提高K值,保證每次迭代有足夠的數據用於訓練。若數據集較大,可適當減小K值,減小程序運行成本。
#計算K折交叉驗證
#scoring="roc_auc"代表以ROC曲線的AUC值作為評分標准
#cv=5 代表這是5折交叉驗證(默認為3折交叉驗證)
#得到的結果是長度為5的列表
AUC_score = cross_val_score(model,x_train,y_train,scoring="roc_auc",cv=5)
print(AUC_score) 輸出[0.95820899 0.9693086 0.961101 0.96984419 0.9672071 ]
print(AUC_score.mean()) 輸出0.9651339760890151通過K折交叉驗證得到的檢驗結果比前面只用一次AUC值更為准確。同時,K折交叉驗證也常與Gridsearch網格搜索配合使用。
網格搜索是啥呢?是一個以K折交叉驗證為底層邏輯的選擇最佳參數的枚舉機制。用大白話說,就是告訴機器我要選出哪些參數,且在什麼范圍裡選。然後機器就一個個帶進去試,同時會給機器提供一個判定的標准(比如標准是最高的AUC的值),從而找到最佳的參數。
舉個例子就是:
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=1)
#Gridsearch
model = DecisionTreeClassifier()
#需要選擇的參數要通過字典格式輸入Gridsearch
try_param = {"max_depth":[1,2,3,4,5,6,7,8,9]}
from sklearn.model_selection import GridSearchCV
#scoring 確定選擇的標准
grid_search = GridSearchCV(model,try_param,scoring="roc_auc",cv=5)
grid_search.fit(x_train,y_train)
best_param = grid_search.best_params_
print(best_param)
輸出:{'max_depth': 7}
這裡想要知道最大深度為幾的樹分類效果最好,評價標准是auc, 然後創建一個Gridsearch的模型,讓他自己跑就行了。最終就會得到最好的那個值。但Gridsearch有個缺陷就是:只能求出有限范圍內的最佳值,比如,萬一max_depth=11時候效果比7的時候要好,通過這個方法並不能得到max_depth=11。
當然,這裡輸出max_depth=7效果最好,那麼就可以用max_depth=7建立分類決策樹,然後接下來的步驟就很常規了。