正則作為處理字符串的一個實用工具,在Python中經常會用到,比如爬蟲爬取數據時常用正則來檢索字符串等等。正則表達式已經內嵌在Python中,通過導入re模塊就可以使用,作為剛學Python的新手大多數都聽說”正則“這個術語。
今天來給大家分享一份關於比較詳細的Python正則表達式寶典,學會之後你將對正則表達式達到精通的狀態。

在講正則表達式之前,我們首先得知道哪裡用得到正則表達式。正則表達式是用在findall()方法當中,大多數的字符串檢索都可以通過findall()來完成。
1.導入re模塊
在使用正則表達式之前,需要導入re模塊。
import re
2.findall()的語法:
導入了re模塊之後就可以使用findall()方法了,那麼我們必須要清楚findall()的語法是怎麼規定的。
findall(正則表達式,目標字符串)
不難看出findall()的是由正則表達式和目標字符串組成,目標字符串就是你要檢索的東西,那麼如何檢索則是通過正則表達式來進行操作,也就是我們今天的重點。
使用findall()之後返回的結果是一個列表,列表中是符合正則要求的字符串
1.普通字符
大多數的字母和字符都可以進行自身匹配。
import re
a = "abc123+-*"
b = re.findall('abc',a)
print(b)
輸出結果:
['abc']
2.元字符
元字符指的是. ^ $ + {} []之類的特殊字符,通過它們我們可以對目標字符串進行個性化檢索,返回我們要的結果。
這裡我給大家介紹10個常用的元字符以及它們的用法,這裡我先給大家做1個簡單的匯總,便於記憶,下面會挨個講解每一個元字符的使用。
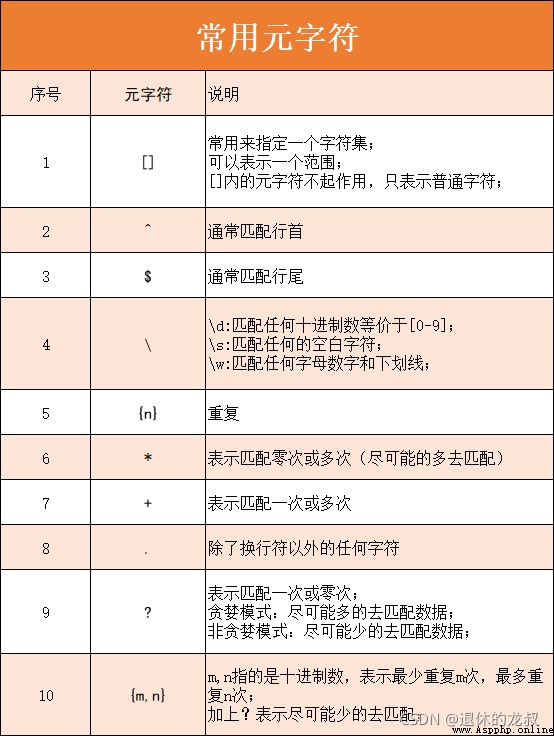
(1) []
[] 的使用方式主要有以下三種:
常用來指定一個字符集。
s = “a123456b”
rule = “a[0-9][1-6][1-6][1-6][1-6][1-6]b” #這裡暫時先用這種麻煩點的方法,後面有更容易的,不用敲這麼多[1-6]
l = re.findall(rule,s)
print(l)
輸出結果為:
['a123456b']
例如要在字符串"abcabcaccaac"中選出abc元素:
s = "abcabcaccaac"
rule = "a[a,b,c]c" # rule = "a[a-z0-9][a-z0-9][a-z0-9][a-z0-9]c"
l = re.findall(rule, s)
print(l)
輸出結果為:
['abc', 'abc', 'acc', 'aac']
例如要在字符串“caabcabcaabc”中選出“caa”:
print(re.findall("caa[a,^]", "caa^bcabcaabc"))
輸出結果為:
['caa^']
注意點:當在[]的第一個位置時,表示除了a以外的都進行匹配,例如把[]中的和a換一下位置:
print(re.findall("caa[^,a]", "caa^bcabcaabc"))
輸出:
['caa^', 'caab']
(2)^
^ 通常用來匹配行首,例如:
print(re.findall("^abca", "abcabcabc"))
輸出結果:
['abca']

粉絲專屬福利
(3) $
$ 通常用來匹配行尾,例如:
print(re.findall("abc$", "accabcabc"))
輸出結果:
['abc']

(4)
反斜槓後面可以加不同的字符表示不同的特殊含義,常見的有以下3種。
d:匹配任何十進制數等價於[0-9]
print(re.findall(“cddda”, “abc123abc”))
輸出結果為:
['c123a']
可以轉義成普通字符,例如:
print(re.findall("^abc", "^abc^abc"))
輸出結果:
['^abc', '^abc']
匹配任何的空白字符例如:
print(re.findall("ss", "a c"))
輸出結果:
[' ', ' ']
匹配任何字母數字和下劃線,等價於[a-zA-Z0-9_],例如:
print(re.findall("www", "abc12_"))
輸出:
['abc', '12_']
(5){n}
{n}可以避免重復寫,比如前面我們用w時寫了3次w,而這裡我們這需要用用上{n}就可以,n表示匹配的次數,例如:
print(re.findall("w{2}", "abc12_"))
輸出結果:
['ab', 'c1', '2_']
(6)*
*表示匹配零次或多次(盡可能的多去匹配),例如:
print(re.findall("010-d*", "010-123456789"))
輸出:
['010-123456789']
**(7) + **
+表示匹配一次或多次,例如
print(re.findall("010-d+", "010-123456789"))
輸出:
['010-123456789']
(8) .
.是個點,這裡不是很明顯,它用來操作除了換行符以外的任何字符,例如:
print(re.findall(".", "010
?!"))
輸出:
['0', '1', '0', '?', '!']
(9) ?
?表示匹配一次或零次
print(re.findall("010-d?", "010-123456789"))
輸出:
['010-1']
這裡要注意一下貪婪模式和非貪婪模式。
貪婪模式:盡可能多的去匹配數據,表現為d後面加某個元字符,例如d*:
print(re.findall("010-d*", "010-123456789"))
輸出:
['010-123456789']
非貪婪模式:盡可能少的去匹配數據,表現為d後面加?,例如d
print(re.findall("010-d*?", "010-123456789"))
輸出為:
['010-']
(10){m,n}
m,n指的是十進制數,表示最少重復m次,最多重復n次,例如:
print(re.findall("010-d{3,5}", "010-123456789"))
輸出:
['010-12345']
加上?表示盡可能少的去匹配
print(re.findall("010-d{3,5}?", "010-123456789"))
輸出:
['010-123']
{m,n}還有其他的一些靈活的寫法,比如:

關於常用的元字符以及使用方法就先到這裡,我們再來看看正則的其他知識。
1.編譯正則
在Python中,re模塊可通過compile() 方法來編譯正則,re.compile(正則表達式),例如:
s = "010-123456789"
rule = "010-d*"
rule_compile = re.compile(rule) #返回一個對象
# print(rule_compile)
s_compile = rule_compile.findall(s)
print(s_compile) #打印compile()返回的對象是什麼
輸出結果:
['010-123456789']
2.正則對象的使用方法
正則對象的使用方法不僅僅是通過我們前面所介紹的 findall() 來使用,還可以通過其他的方法進行使用,效果是不一樣的,這裡我做個簡單的總結:
(1)findall()
找到re匹配的所有字符串,返回一個列表
(2)search()
掃描字符串,找到這個re匹配的位置(僅僅是第一個查到的)
(3)match()
決定re是否在字符串剛開始的位置(匹配行首)
就拿上面的 compile()編譯正則之後返回的對象來做舉例,我們這裡不用 findall() ,用 match() 來看一下結果如何:
s = "010-123456789"
rule = "010-d*"
rule_compile = re.compile(rule) # 返回一個對象
# print(rule_compile)
s_compile = rule_compile.match(s)
print(s_compile) # 打印compile()返回的對象是什麼
輸出:
<re.Match object; span=(0, 13), match='010-123456789'>
可以看出結果是1個match 對象,開始下標位置為0~13,match為 010-123456789 。既然返回的是對象,那麼接下來我們來講講這個match 對象的一些操作方法。

粉絲福利
3.Match object 的操作方法
這裡先介紹一下方法,後面我再舉例,Match對象常見的使用方法有以下幾個:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配開始的位置
(3)end()
返回匹配結束的位置
(4)span()
返回一個元組:(開始,結束)的位置
舉例:用span()來對search()返回的對象進行操作:
s = "010-123456789"
rule = "010-d*"
rule_compile = re.compile(rule) # 返回一個對象
s_compile = rule_compile.match(s)
print(s_compile.span()) #用span()處理返回的對象
結果為:
(0, 13)
4.re模塊的函數
re模塊中除了上面介紹的findall()函數之外,還有其他的函數,來做一個介紹:
(1)findall()
根據正則表達式返回匹配到的所有字符串,這個我就不多說了,前面都是在介紹它。
(2)sub(正則,新字符串,原字符串)
sub() 函數的功能是替換字符串,例如:
s = "abcabcacc" #原字符串
l = re.sub("abc","ddd",s) #通過sub()處理過的字符串
print(l)
輸出:
ddddddacc #把abc全部替換成ddd
(3)subn(正則,新字符串,原字符串)
subn()的作用是替換字符串,並返回替換的次數
s = "abcabcacc" #原字符串
l = re.subn("abc","ddd",s) #通過sub()處理過的字符串
print(l)
輸出:
('ddddddacc', 2)
(4)split()
split()分割字符串,例如:
s = "abcabcacc"
l = re.split("b",s)
print(l)
輸出結果:
['a', 'ca', 'cacc']

關於正則,我就講這麼多了,正則幾乎是Python所有方向中是必不可少的一個基礎,祝你的Python之旅學有所成!

先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦