博主:不許代碼碼上紅
項目:python爬蟲實戰
格言:莫道君行早,更有早行人。

1、bs4、BeautifulSoup
是一個可以從HTML或XML文件中提取數據的Python庫.它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式。
BeautifulSoup會幫你節省數小時甚至數天的工作時間。
2、re
指定了一組與之匹配的字符串;模塊內的函數可以檢查某個字符串是否與給定的正則表達式匹配(或者正則表達式是否匹配到字符串,這兩種說法含義相同)。
3、urllib
是一個收集了多個涉及 URL 的模塊的包:
urllib.request 打開和讀取 URL
urllib.error 包含 urllib.request 拋出的異常
urllib.parse 用於解析 URL
urllib.robotparser 用於解析 robots.txt 文件
4、️️️xlwt️️️
xlwt是Python中操作Excel的一個庫,可以將數據保存成Excel。
第一步:引入所需要的庫
from bs4 import BeautifulSoup #網頁解析,獲取數據
import re #正則表達式,進行文字匹配
import urllib.request,urllib.error
import xlwt #進行excel操作
第二步:定義主函數
def main():
主函數用來統籌所有功能模塊函數,可以使真個項目的結構更加清晰。
第三步:定義的正則表達式規則
#影片詳情連接的規則
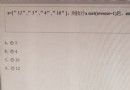
findLink=re.compile(r'<a href="(.*?)"')#創建規則,正則表達式對象,r忽視特殊符號
正則表達式通常被用來檢索、替換那些符合某個模式(規則)的文本。
第四步:創建抓取網頁函數getData
def getData(baseurl):
將我們所要抓取的網頁發放入,例如:
baseurl="https://movie.douban.com/top250?start="
讓後將baseurl傳入getData。
數據抓取成功
鏈接:https://pan.baidu.com/s/1FFrEDZyRi8-6CqUiPB9WbA
提取碼:9527
希望大家多多支持,一起學習、一起進步!